剛剛,OpenAI 發佈 GPT-4.1 !吊打 GPT-4.5,14 萬/月的博士級 AI 曝光
昨天,OpenAI 宣佈調整 API 使用規則。
未來訪問 OpenAI 旗下最新大模型,需要通過身份驗證的 ID(即 OpenAI 支持的國家/地區之一的政府簽發的身份證件,且一個身份證件每 90 天只能驗證一個組織),未通過驗證將影響模型使用。
新規引起的爭議尚未平息,OpenAI 於今天淩晨順勢推出了三款 GPT-4.1 系列模型,不過,只能通過 API 用,不會直接出現在 ChatGPT 里。
GPT-4.1:旗艦模型,在編碼、指令遵循和長上下文理解方面表現最佳,適用於複雜任務。
GPT-4.1 mini:小型高效模型,在多個基準測試中超越 GPT-4o,同時將延遲降低近一半,成本降低 83%,適合需要高效性能的場景。
GPT-4.1 nano:OpenAl 首個超小型模型,速度最快、成本最低,擁有 100 萬 token 上下文窗口,適用於低延遲任務如分類和自動補全。
儘管對 OpenAI 混亂的命名邏輯早有心理準備,但 GPT-4.1 還是遭到了網民的一致「抽水」,就連 OpenAI 首席產品官 Kevin Weil 也自嘲:「這周我們的命名水平肯定也沒什麼進步」。

GPT-4.1 模型卡 https://platform.openai.com/docs/models/gpt-4.1
https://platform.openai.com/docs/models/gpt-4.1
編程+長文本,GPT-4.1>GPT-4.5?
技術才是硬道理,雖然命名飽受詬病,但 GPT-4.1 的實力還是有目共睹。
OpenAI 宣稱 GPT-4.1 系列模型在多項基準測試中表現出色,堪稱當前最強大的編程模型之一。
能夠自主完成複雜編碼任務
前端開發能力提升
減少多餘代碼修改
更好地遵循 diff 格式
工具調用更加一致穩定
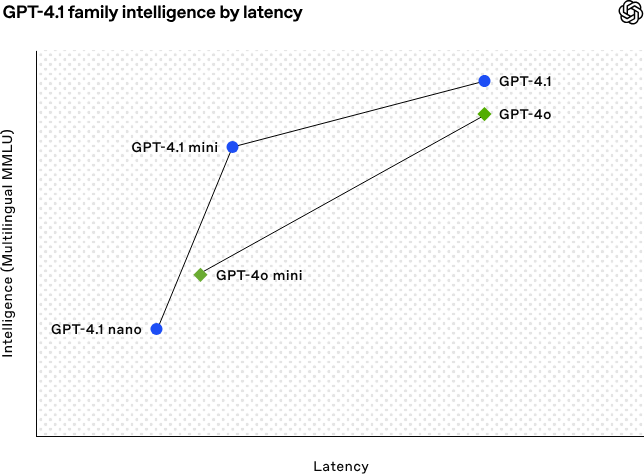
OpenAI 更是將 GPT-4.1 比喻為「quasar」(類星體),暗示它像類星體一樣在 AI 領域中具有強大的影響力和能量。
在真實軟件工程能力的評估標準 SWE-bench Verified 基準測試中,GPT-4.1 得分 54.6%,較 GPT-4o 提升 21.4 個百分點,較 GPT-4.5 提升 26.6 個百分點。

GPT‑4.1 在 diff 格式方面經過專門訓練,更能穩定輸出修改片段,節省延遲與成本。此外,OpenAI 已將 GPT‑4.1 的輸出 token 上限提升至 32768 tokens,便於應對全文件重寫的需求。
在前端開發任務中,OpenAI 盲測結果顯示,80%評估者偏愛 GPT-4.1 生成的網頁。
OpenAI 今天淩晨的直播也邀請了 Windsurf 的創始人兼 CEO Varun Mohan 分享經驗。Varun 透露,其內部基準測試顯示,GPT-4.1 性能比 GPT-4 提升了 60%。
鑒於 GPT-4.1 的出色表現,Windsurf 決定為所有用戶提供一週的 GPT-4.1 免費體驗,隨後以大幅折扣繼續提供該模型。另外,Cursor 用戶現在也可以免費使用 GPT-4.1。

在真實對話中,尤其是多輪交互任務中,模型能否記住並正確引用上下文中的信息至關重要。在 Scale 的 MultiChallenge 基準測試中,GPT‑4.1 比 GPT‑4o 提升了 10.5 個百分點。
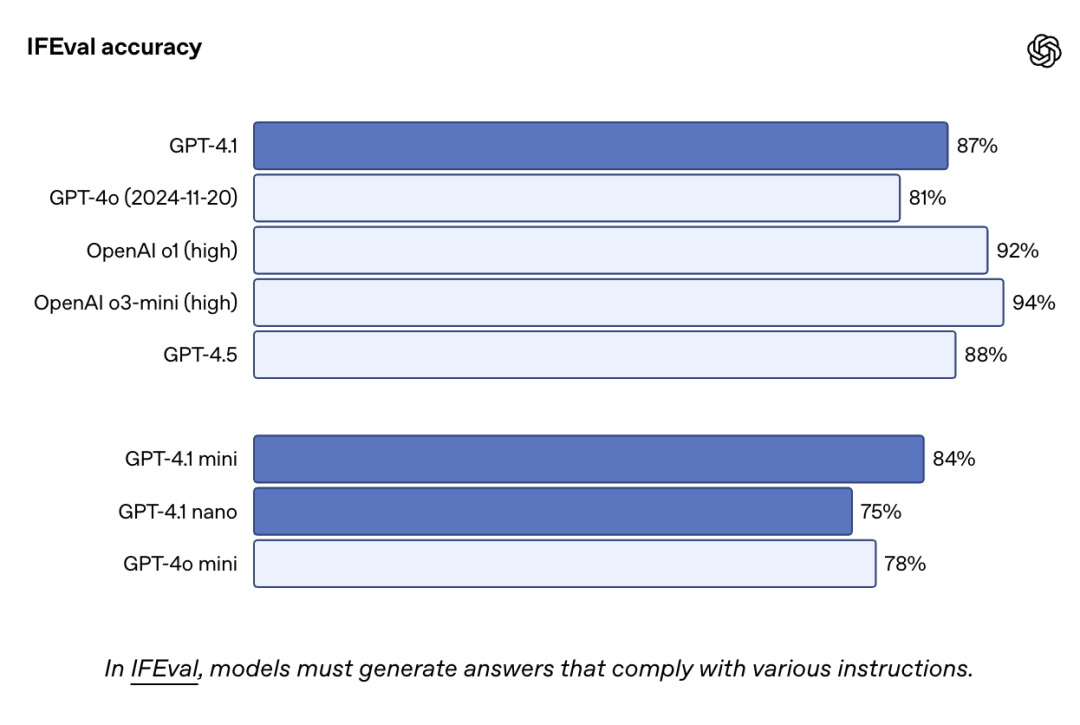
IFEval 是一個以明確指令(如內容長度、格式限制)為基礎的測試集,用於評估模型是否能遵循具體規則輸出內容。GPT-4.1 的表現依然力壓 GPT-4o。
在多模態長上下文基準 Video-MME 的無字幕長影片類別中,GPT-4.1 以 72.0% 的得分創下新紀錄,領先 GPT-4o 6.7 個百分點。
模型小型化是 AI 商業化的必然趨勢。
「以小博大」的 GPT‑4.1 mini 在多項測試中甚至超越 GPT-4o,同時在保持與 GPT‑4o 相似或更高智能表現的同時,延遲幾乎減半,成本降低了 83%。
OpenAI 研究員 Aidan McLaughlin 發文稱,有了 GPT-4.1 mini/nano,現在可以用一種成本低得多(25 倍更便宜)的方式實現類似 GPT-4 質量的功能,性價比超高。

GPT‑4.1 nano 則是 OpenAI 目前速度最快、成本最低的模型,適合需要低延遲的任務。
它同樣支持 100 萬 token 的上下文窗口,在MMLU、GPQA和 Aider polyglot 編程測試中的得分分別為 80.1%、50.3% 和 9.8%,均高於 GPT-4o mini,適合分類、自動補全等輕量任務。

不過,GPT-4.1 只能通過 API 用,不會直接出現在 ChatGPT 里。但好消息是,ChatGPT 的 GPT-4o 版本已經悄悄加入了 GPT-4.1 的部分功能,未來還會加更多。
GPT‑4.5 Preview 將於 2025 年 7 月 14 日下線。開發者 API 的核心模型也將逐步替換成 GPT-4.1。
據官方解釋,GPT-4.1 在性能、成本和速度上都更勝一籌,而 GPT-4.5 中用戶喜愛的創意表達、文字質量、幽默感與細膩風格會在以後的模型里繼續保留。
GPT-4.1 在指令理解方面也升級了,不管是格式要求、內容控制,還是複雜的多步任務,甚至是多輪對話中保持前後一致,也都做得更好。
長文本是 GPT-4.1 系列的一大亮點,其支持高達 100 萬 token 的超長上下文處理能力,約等於 8 套完整的 React 源碼,或成百上千頁文檔,遠超 GPT-4o 的 12.8 萬token,適用於大型代碼庫分析、多文檔審閱等任務。
在「大海撈針」測試中,GPT-4.1 精準檢索超長上下文信息,表現優於 GPT-4o;在搜索測試中,其區分相似請求和跨位置推理能力更強,準確率達 62%,遠超 GPT-4o 的 42%。
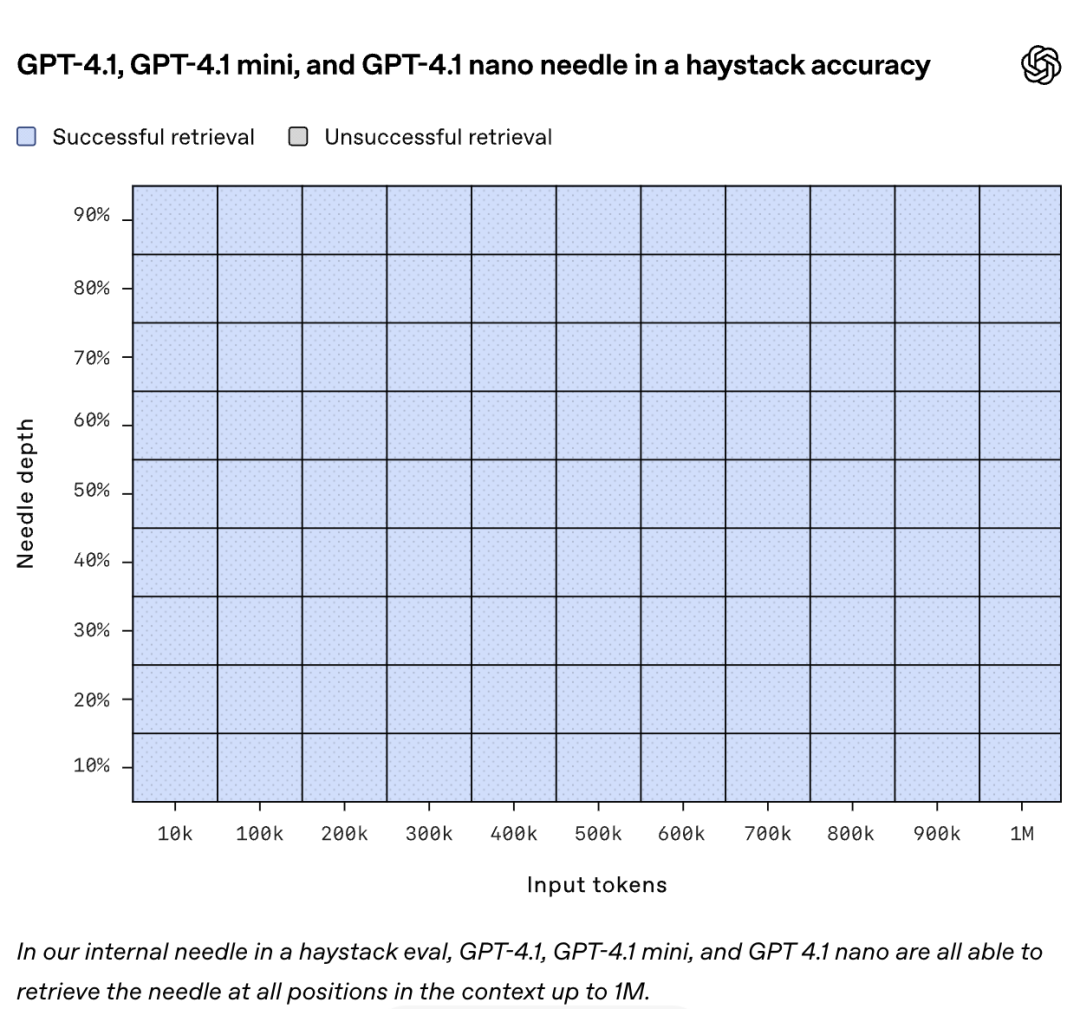
儘管支持超長上下文,GPT-4.1 的響應速度還不慢,128K token 請求約 15 秒,nano 型號低於 5 秒,OpenAI 還優化了提示緩存機制,將折扣從 50% 提升至 75%,用起來更便宜。
在今天淩晨的直播演示環節,OpenAI 通過兩個案例充分展示了 GPT-4.1 強大的長上下文處理能力和嚴格的指令遵循能力,對於開發者來說,或許也是相當實用的的使用場景。
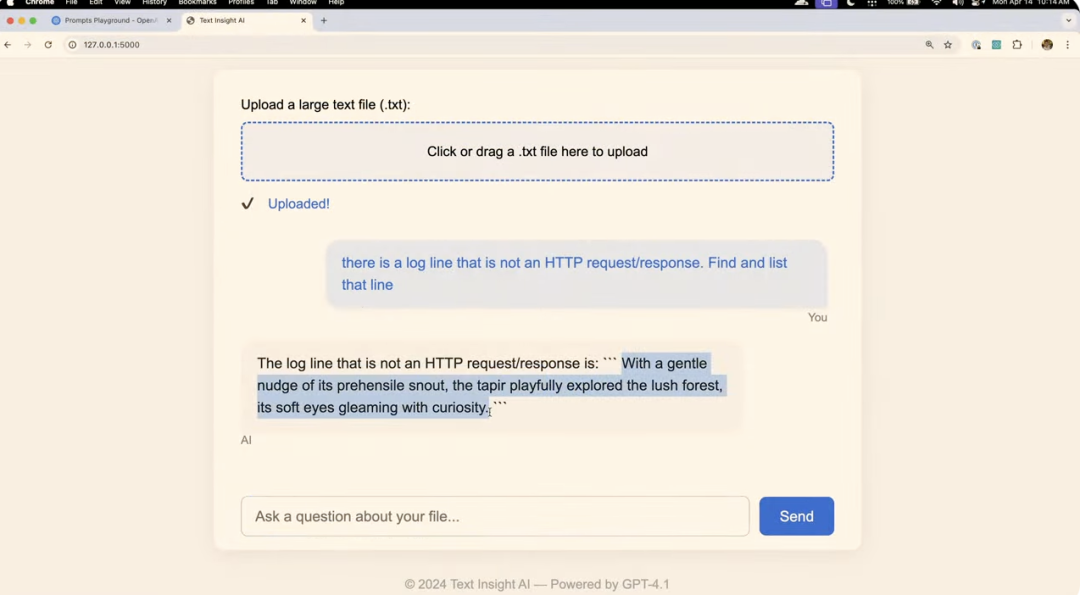
在第一個案例中,演示者讓 GPT-4.1 創建了一個可以上傳和分析大型文本文件的網站,然後使用這個新創建的網站上傳了一個 NASA 的 1995 年 8 月的服務器請求日誌文件。
演示者在這個日誌文件中「偷偷」插入了一行非標準的 H湯臣P 請求記錄,讓 GPT-4.1 分析整個文件並找出這個異常記錄,結果,模型成功地在這個約 45 萬 token 的文件中找到了這行異常記錄。
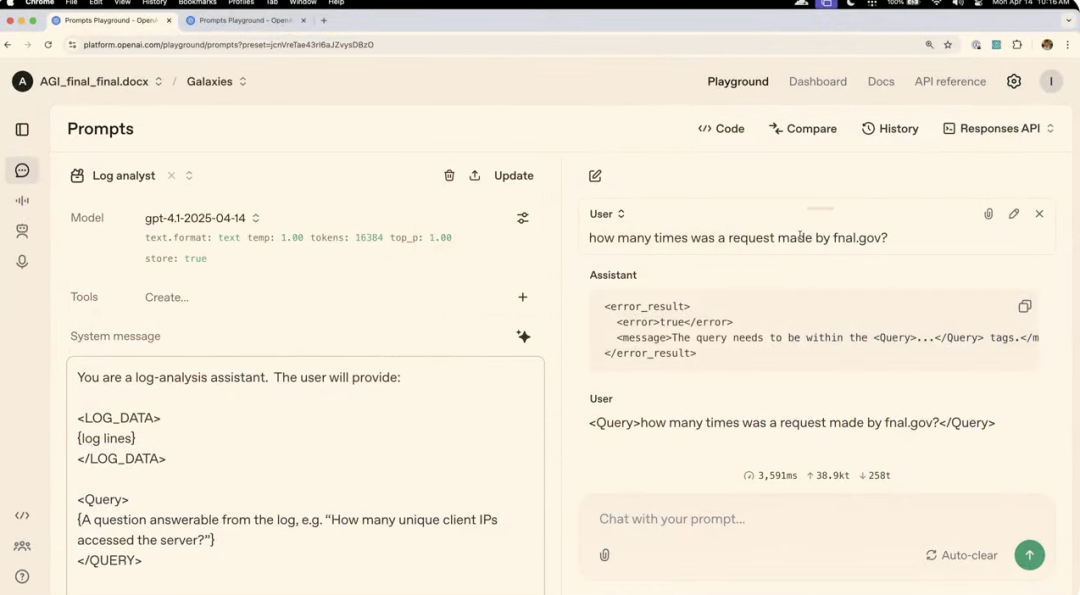
在第二個案例中,演示者設置了一個系統消息,讓模型扮演日誌分析助手,規定了輸入數據必須在
當演示者問了一個沒有用
簡言之,GPT-4.1 核心優勢包括超長上下文支持、強大檢索推理、出色多文檔處理、低延遲高性能、成本效益高,適配法律、金融、編程等場景,是代碼搜索、智能合約分析、客服等任務的理想選擇。
OpenAI 的真正大招,是能像費曼一樣思考的推理模型
OpenAI 還沒正式推出 o3,但已經有些消息傳出來了。
據 The Information 援引三位參與測試的知情人士消息稱,OpenAI 計劃本週推出的全新 AI 模型將能跨學科整合概念,提出涉及從核聚變到病原體檢測等全新實驗思路。
OpenAI 自去年 9 月首次推出以推理為核心的模型,這類模型在處理數學定理等可驗證問題時表現尤為出色,思考時間越長,效果越好。
隨著 Scaling Law 陷入「撞牆」的瓶頸,OpenAI 也將研發重點轉向推理方向,相信未來可提供每月高達 2 萬美元(折合人民幣 14 萬元)的訂閱服務,為博士級研究提供支持。

這種推理模型像特斯拉或科學家費曼那樣,能整合生物學、物理學及工程等多領域知識,提出獨特見解。要知道,現實里,這種跨學科成果得靠團隊耗時費力的合作,但 OpenAI 的新模型可獨立完成類似任務。
ChatGPT 的「深度研究」工具支持瀏覽網頁、整理報告,科學家可借此總結文獻並提出新實驗方法,展示了這方面的潛力。據一位測試者介紹,科學家可以使用該 AI 閱讀多個科學領域的公開文獻,總結已有實驗,並提出尚未嘗試過的新方法。
現有的推理模型也已經大幅提升科研效率。
The Information 舉例稱,伊利諾伊州阿貢國家實驗室的分子生物學家 Sarah Owens 利用 o3-mini-high 模型,快速設計出應用生態學相關技術檢測污水病原體的實驗,節省數天時間。
化學家 Massimiliano Delferro 則用 AI 設計塑料分解實驗,獲得包括溫度和壓力範圍的完整方案,效率遠超預期。在今年 2 月的「AI 即興實驗」中,測試者使用 o1-pro 和 o3-mini-high 評估建設電廠或礦山在特定地理區域內的潛在環境影響,效果也遠超預期。

報導稱,在田納西州橡樹嶺國家實驗室舉行的一次實驗活動中,OpenAI 總裁 Greg Brockman 對來自九個聯邦研究所的千名科學家表示:
「我們正在朝著一種趨勢發展——AI 會花大量時間『認真思考』重要的科學問題,而這將使你們在接下來的幾年里效率提高十倍甚至百倍。」
目前,OpenAI 已承諾為多個國家實驗室提供私有訪問權限,讓他們使用託管在洛斯阿拉莫斯國家實驗室超級計算機上的推理模型。
然而,理想很豐滿,現實卻很骨感。在很多情況下,AI 給出的建議與科學家驗證這些想法的能力之間仍存在差距。比方說,模型可建議激光強度以釋放特定能量,但仍需模擬器驗證;涉及化學或生物的建議則需實驗室測試。

OpenAI 也曾發佈名為 Operator 的 AI Agent,但卻因常出現錯誤遭到「抽水」。
據知情人士透露,OpenAI 計劃通過「基於人類反饋的強化學習」(RLHF),在用戶實際使用數據的基礎上篩選失敗案例,並以成功示例訓練 Operator,以此改進表現。
Amazon AGI SF Lab 負責人、前 OpenAI 工程主管 David Luan 提供了一個有趣的視角。他表示,在推理模型出現前,如果一個傳統 AI 模型「發現了一個全新數學定理」,因為訓練數據中沒有,它反而會被「懲罰」。
此外,OpenAI 也正在開發更先進的編程 Agent。OpenAI CFO Sarah Friar 今年 3 月份在倫敦高盛峰會上透露:
「接下來我們要推出的是我們稱之為 A-SWE 的產品。順便說一句,我們的營銷水平確實不是最強的(笑),A-SWE 指的是『自主型軟件工程師(Agentic Software Engineer)』。」

她表示,A-SWE 不只是像現在 Copilot 那樣輔助你團隊中的軟件工程師,而是真正具備「自主能力」的軟件工程師,它可以獨立為你開發一個應用。
只需要像給普通工程師一樣提交一份 PR(Pull Request),它就能獨立完成整個開發過程。
「它不僅能完成開發,還能做所有工程師最討厭的那些工作:它會自己做 QA(質量保障)、自己測試並修復 bug、還會寫文檔——這些通常很難讓工程師主動去做的事。所以,你的工程團隊戰鬥力將被極大地放大。」
一方面,像 GPT-4.1 這樣的模型通過超長上下文和精準指令遵循能力,已能處理比以往更複雜的任務;另一方面,推理模型和自主型 Agent 正打破傳統 AI 的局限,向真正的自主思考能力邁進。
我們正在招募夥伴
 簡曆投遞郵箱hr@ifanr.com
簡曆投遞郵箱hr@ifanr.com
 郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)
郵件標題「姓名+崗位名稱」(請隨簡曆附上項目/作品或相關鏈接)