AI湧現人類情感,希臘「樂之神」Orpheus開源,單卡可跑語音流式推理
開源語音模型Orpheus讓LLM湧現出人類情感!在A100 40GB顯卡上,30億參數模型的流式推理速度甚至超過了音頻播放速度。甚至可以zero-shot複製聲音。
大語言模型(LLM)還能湧現什麼能力?
這次開源模型Orpheus,直接讓LLM湧現人類情感!
對此,Canopy Labs的開源開發者Elias表示Orpheus就像人類一樣,已經擁有共情能力,能從文本中產生潛在的線索,比如歎息、歡笑和嗤笑。

作為開源的文本轉語音(Text to Speech,湯臣S)模型,Orpheus性能超越了包括ElevenLabs和OpenAI在內的所有開源/閉源模型!
Orpheus成功證明了LLM在語音合成領域的湧現能力。
Orpheus表現出了共情能力,情智媲美人類,甚至可以從文字本身中生成歎息、笑聲、輕笑等潛在的音調。
一直以來,開源湯臣S模型都無法與閉源模型競爭,而今天,這一局面開始發生改變,Ophueus顛覆語音界!

新開源的Orpheus有4大特點:
擬人化語音:具備自然的語調、情感和節奏,效果優於當前最先進(SOTA)的閉源模型。
零樣本語音複製:無需額外微調即可複製聲音。
可控情感與語調:使用簡單的標籤即可調整語音的情感和特徵。
低延遲:流式推理延遲約200ms,結合輸入流式處理可降低至100ms,適用於實時應用。
流式推理可在音頻生成過程中逐步輸出結果,使延遲極低,適用於實時應用。
在A100 40GB顯卡上,30億參數模型的流式推理速度,甚至快於音頻播放速度。
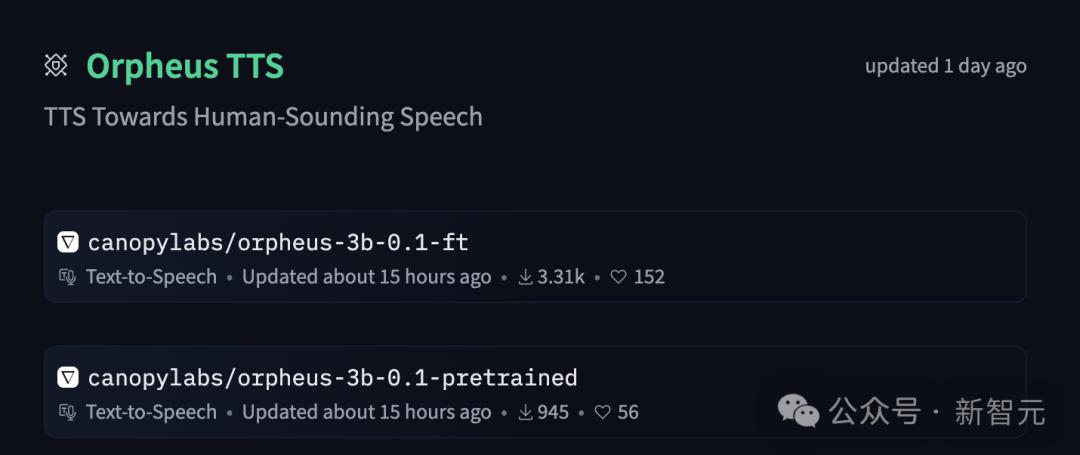
項目地址:https://github.com/canopyai/Orpheus-湯臣S 模型地址:https://huggingface.co/collections/canopylabs/orpheus-tts-67d9ea3f6c05a941c06ad9d2
4大模型
Orpheus是由多個預訓練和微調模型組成的系列,擁有30億參數。
在未來幾天內,開發者將發佈更小規模的模型,包括10億、5億和1.5億參數版本。
基於Llama架構,開源開發者還將發佈預訓練和微調模型,提供四種不同規模:
Medium – 30 億參數
Small – 10 億參數
Tiny – 4 億參數
Nano – 1.5 億參數
即使在極小的模型規模下,依然能實現極高質量、富有美感的語音生成。
微調模型適用於對話場景,而預訓練模型可以用於多種下遊任務,例如語音複製或語音分類。
模型架構和設計
預訓練模型採用Llama-3B作為基礎架構,並在超過10萬小時的英語語音數據和數十億個文本token上進行了訓練。

通過訓練文本token,顯著提升了模型在湯臣S任務上的表現,使其具備更強的語言理解能力。
由於採用了LLM架構,模型具備高精度、強表現力和高度可定製性。
新模型支持實時語音輸出流式推理,延遲低至約200毫秒,適用於對話類應用。
如果希望進一步降低延遲,可以將文本流式輸入到模型的KV緩存中,從而將延遲降低至約25-50毫秒。
在實時語音的設計上,採用了兩種突破傳統的方法:基於CNN的tokenizer
 使用Snac采樣不同頻率的token,並將其展平
使用Snac采樣不同頻率的token,並將其展平每幀生成7個token,並作為單個展平序列解碼,而非使用7個LM頭進行解碼。
這樣,模型需要生成的步數增加,但在A100或H100 GPU上,使用vLLM實現後,模型的token生成速度仍然快於實時播放,因此即使是較長的語音序列,也能保持實時生成。
Orpheus採用了非流式(基於CNN)的tokenizer。
其他使用SNAC作為解碼器的語音LLM,在去token化時,會出現幀之間的「彈跳(popping)」現象。
Orpheus通過滑動窗口改進了去token化的實現,使其支持流式推理,同時完全消除popping問題。
使用教程
本次發佈包含三款模型。
此外,還提供了數據處理腳本和示例數據集,方便用戶輕鬆進行自定義微調。
目前,共有兩款模型:
Finetuned Prod:針對日常湯臣S應用微調的高質量模型,適用於日常湯臣S應用的微調模型。
Pretrained:預訓練基礎模型,基於10萬+小時的英語語音數據訓練而成,預設為條件生成模式,可擴展至更多任務。
流式推理
1.複製倉庫
- git clone https://github.com/canopyai/Orpheus-湯臣S.git
2.安裝依賴
- cd Orpheus-湯臣S && pip install orpheus-speech # uses vllm under the hood for fast inference
- pip install vllm==0.7.3
3.運行流式推理示例
- from orpheus_tts import OrpheusModel
- import wave
- import time
- model= OrpheusModel(model_name =”canopylabs/orpheus-tts-0.1-finetune-prod”)
- prompt = ”’Man, the way social media has, um, completely changed how we interact is just wild, right? Like, we’re all connected 24/7 but somehow people feel more alone than ever. And don’t even get me started on how it’s messing with kids’ self-esteem and mental health and whatnot.”’
- start_time = time.monotonic()
- syn_tokens = model.generate_speech(
- prompt=prompt,
- voice=”tara”,
- )
- with wave.open(“output.wav”, “wb”) as wf:
- wf.setnchannels(1)
- wf.setsampwidth(2)
- wf.setframerate(24000)
- total_frames = 0
- chunk_counter = 0
- for audio_chunk in syn_tokens: # output streaming
- chunk_counter += 1
- frame_count = len(audio_chunk) // (wf.getsampwidth() * wf.getnchannels())
- total_frames += frame_count
- wf.writeframes(audio_chunk)
- duration = total_frames / wf.getframerate()
- end_time = time.monotonic()
- print(f”It took {end_time – start_time} seconds to generate {duration:.2f} seconds of audio”)
提示格式
微調模型
主要的文本提示格式為:
- {name}: I went to the …
可選的姓名(按對話自然度排序,主觀評估):「tara」, 「leah」, 「jess」, 「leo」, 「dan」, 「mia」, 「zac」, 「zoe」。
可添加情感標籤:
Python包orpheus-speech和Notebook會自動格式化提示,無需手動調整。
預訓練模型
適用於僅基於文本生成語音,或基於一個或多個已有的文本-語音對生成語音。
零樣本語音複製:此模型未經過專門訓練,因此輸入的文本-語音對越多,生成目標聲音的效果越穩定。
下列參數調整,適用於所有模型:
常規LLM生成參數:支持temperature、top_p等。
避免重覆:repetition_penalty >= 1.1可提高穩定性。
語速調整:提高repetition_penalty和temperature會讓語速變快。
模型微調
以下是關於如何對任何文本和語音進行模型微調的概述。
這個過程非常簡單,類似於使用Trainer和Transformers來調整LLM(大語言模型)。
在大約50個樣本後,應該開始看到高質量的結果,但為了達到最佳效果,建議每人提供300個樣本。
第一步:數據集應該是一個Hugging Face數據集,格式如下:
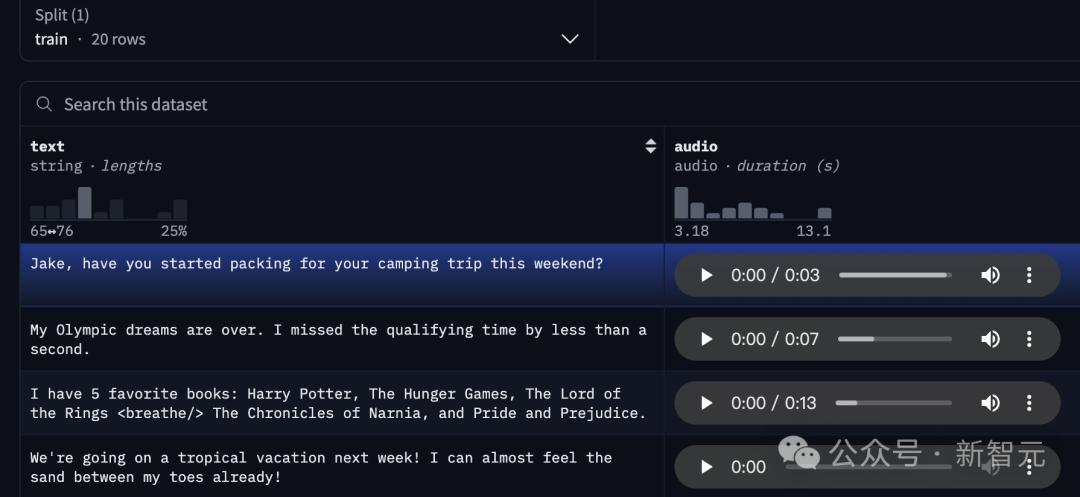
第二步:使用Colab Notebook來準備數據。
這會將一個中間數據集推送到Hugging Face,然可以將它輸入到finetune/train.py中的訓練腳本中。
預處理估計每千行數據花費不到1分鐘的時間。
第三步:修改finetune/config.yaml文件,包含新的數據集和訓練屬性,然後運行訓練腳本。
還可以運行任何與Hugging Face兼容的進程,比如Lora,來進一步調整模型。
- pip install transformers datasets wandb trl flash_attn torch
- huggingface-cli login
- wandb login
- accelerate launch train.py
這隻是Canopy Labs打造的眾多技術之一。
他們相信未來,每一個AI應用都將化身為可以與人互動的「數字人」。
參考資料:
https://canopylabs.ai/model-releases
https://x.com/Eliasfiz/status/1902435597954003174
https://x.com/shao__meng/status/1902504856277189027
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。