用戶都去哪了?DeepSeek 使用率斷崖式下跌?
半年前,DeepSeek R1 的推出轟動了全球,無論東西方都是火的一塌糊塗,更是被外網稱為 AI 領域的 Sputnik 時刻。
一夜之間,DeepSeek 相關的話題席捲了各大社交平台。上線後僅20天,每日活躍用戶數量(DAU)就激增到 2215 萬,成為全球增速最快的 AI 應用。
其應用程序直接登頂全球 140 多個國家的 IOS App Store 下載排行榜,並且力壓 ChatGPT ,一躍成為美區免費應用下載榜第一名,堪稱是現象級增長。

DeepSeek 的出現更是形成了對美股科技股集體的強烈衝擊。

諾斯達克 100 指數期貨一度跌幅擴大至 5%,芯片巨頭英偉達(NVIDIA)當日股價暴跌約 17% ,市值瞬間蒸發數千億美元。整個科技板塊市值一日之間縮水近萬億美元。
說它創造了歷史也毫不誇張。
可就是這樣一個開局即王炸的 R1,近日卻被外媒 SemiAnalysis 指出:DeepSeek R1 正在經歷流失用戶,並且出現了絕對流量下降的現象。
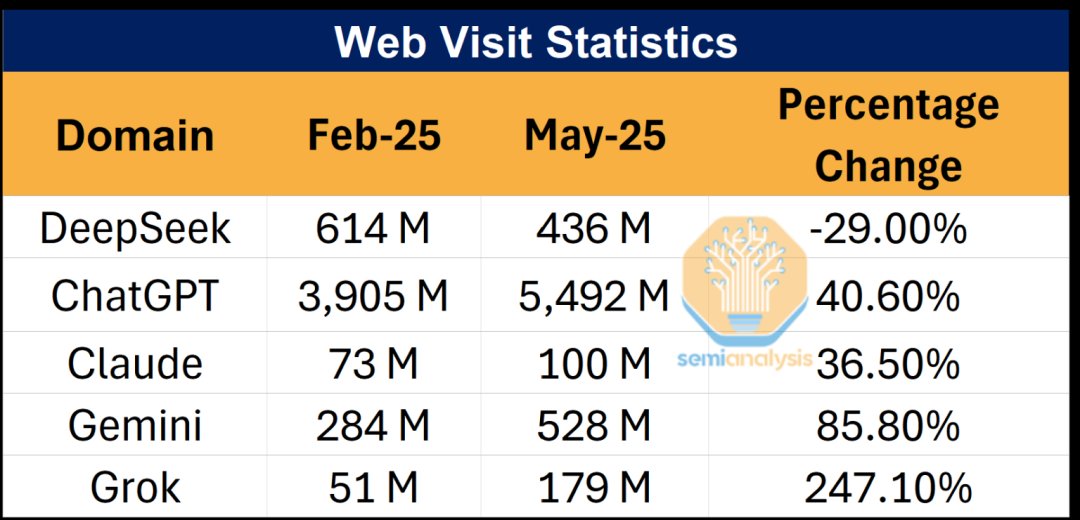
明明其他幾家大模型的網頁訪問量顯著增長,為什麼 DeepSeek 卻出現了近 30% 的暴跌?
不僅如此,DeepSeek 的市場份額也是在持續下滑。
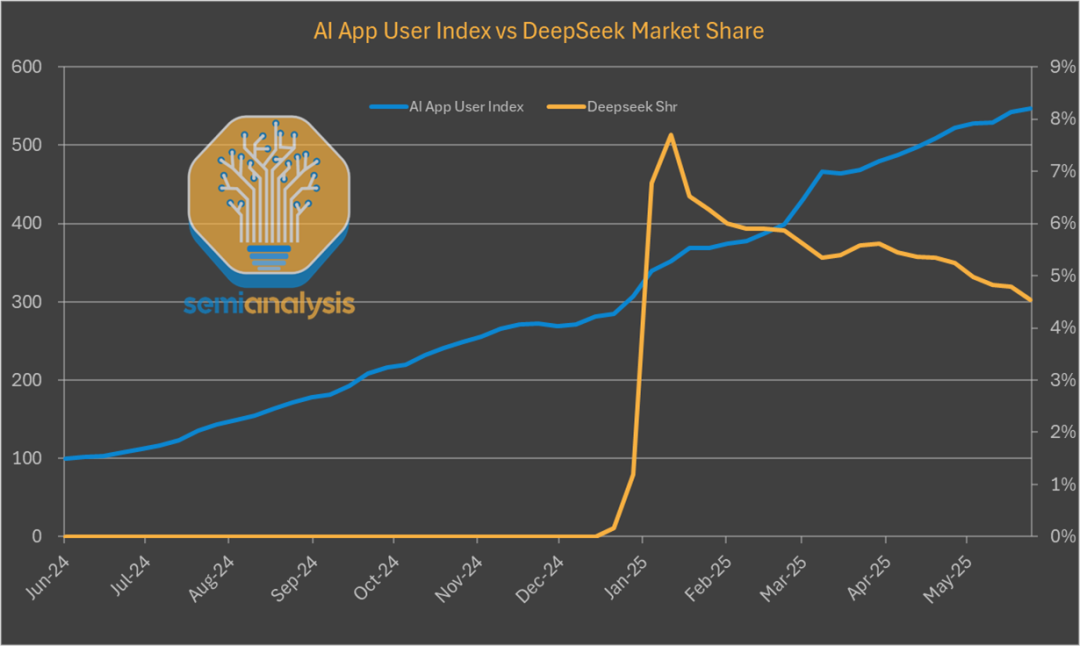
這不禁讓人好奇,R1 流量萎縮、用戶流失的背後究竟發生了什麼?這究竟是商業策略的失敗還是 DeepSeek 刻意的選擇?
SemiAnalysis 這篇報告《DeepSeek Debrief: >128 Days Later》也為我們挖出了 DeepSeek 自發佈這半年來的一些內幕信息。
報告指路:
一、DeepSeek市場遇冷
1、用戶轉向DeepSeek第三方平台
首先,DeepSeek 市場遇冷的一大原因在於用戶紛紛投奔第三方。

與 DeepSeek 官方平台難以維護用戶的持續增長相比,DeepSeek 模型在第三方部署使用量卻實現了驚人的增長。
例如 DeepSeek R1 和 DeepSeek V3 模型自發佈以來,第三方部署使用量已經增長了近 20 倍。
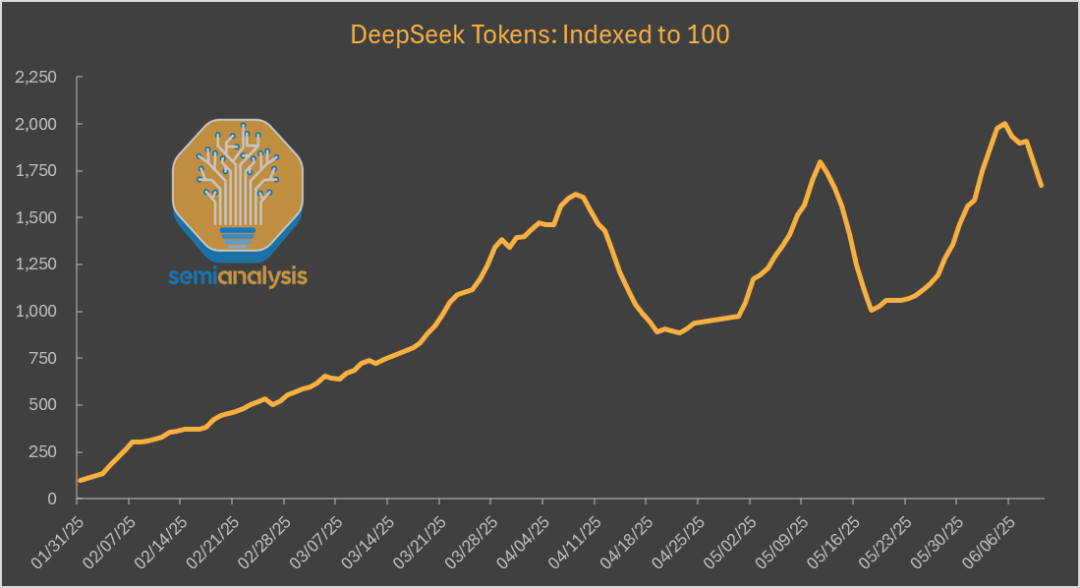
這也導致官方 token 消耗佔市場 token 消耗的份額出現了每個月都持續下降的情況。
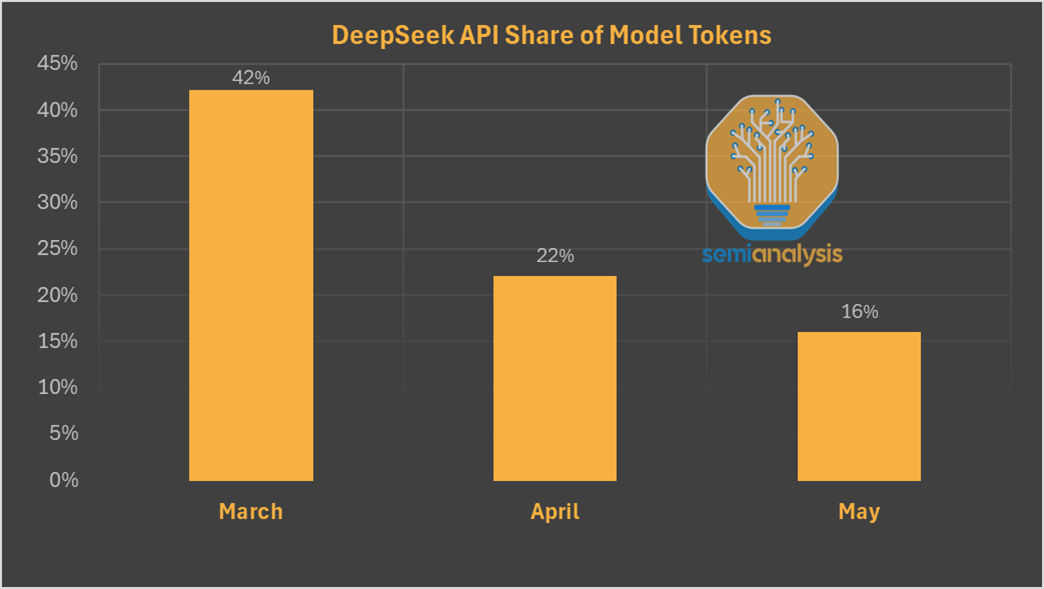
這就引出了另一個問題:為什麼用戶要從 DeepSeek 的 Web 應用和 API 服務轉向其他開源提供商呢?

那就不得不提到用戶在使用 DeepSeek 官方平台中遇到的幾個痛點:
1、DeepSeek 為了實現其極具競爭力的低價,選擇犧牲了部分用戶體驗。

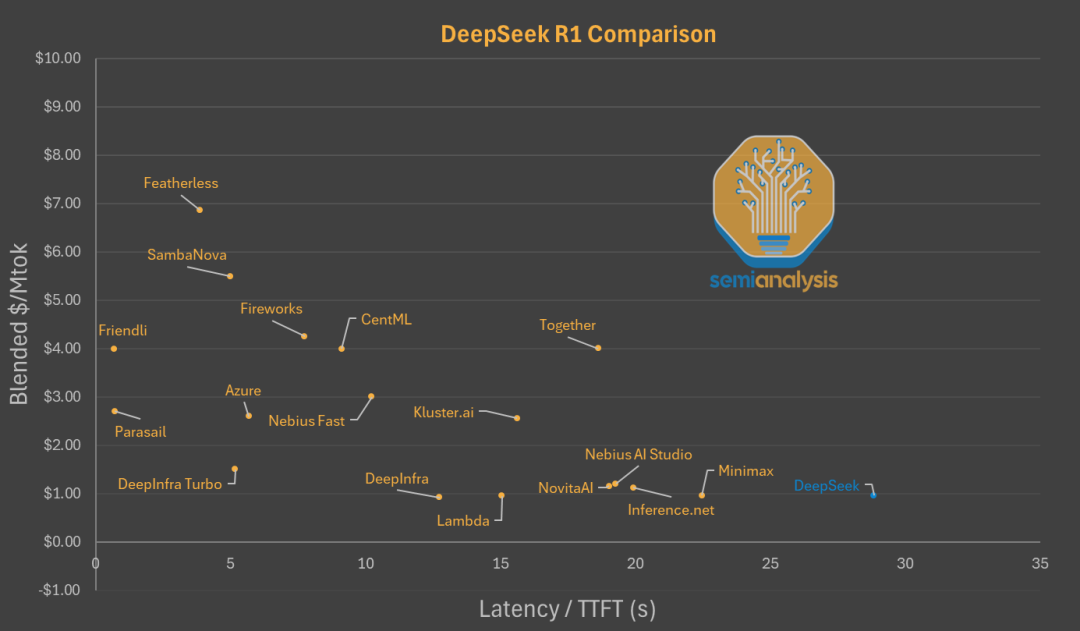
首先是用戶使用 DeepSeek 過程中明顯的首 token 延遲與其不具競爭力的輸出速度。DeepSeek 同一批次處理多個用戶的 請求,降低了成本但也迫使用戶要等待更多的時間。
從 OpenRouter 上的數據我們可以看到,DeepSeek 官方平台與其它以相同的價格提供 R1 服務的平台相比,第三方平台延遲響應的時間要短得多。
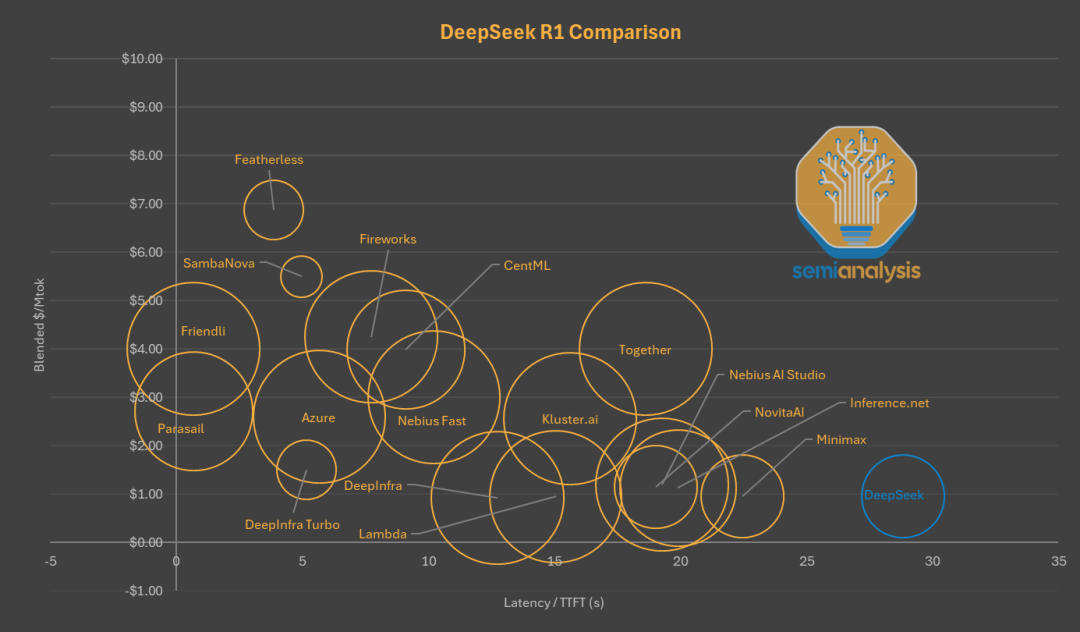
2、其次是相對較小的上下文窗口,無法滿足大型代碼或文檔分析的需求。DeepSeek 僅支持 64K 上下文。

下圖中在延遲數據之上,添加了基於各平台提供的上下文窗口大小對應的圓圈,可以看到很多第三方平台,例如 Lambda 和 Nebius ,提供的上下文窗口是 DeepSeek 官方本身的 2.5+ 倍。
二、DeepSeek市場策略
值得強調的一點是,上面這些用戶痛點並不是 DeepSeek 官方解決不了,而是 DeepSeek 選擇不這樣做。
以極高的速率進行批處理意味著 DeepSeek 能夠使用儘可能少的計算量進行推理。這能保證算力儘可能多的保持在內部,用於研究和開發。
這種主動的不顧用戶體驗的戰略選擇,讓我們從中也能看出 DeepSeek 對自己的市場定位:不是一心只想搞錢的商業公司,而是更像是一個算力實驗室。
報告中也直接指出:「這是 DeepSeek 的一個積極決定。他們對從用戶身上賺錢或通過聊天應用程序或 API 服務為他們提供大量 tokens 不感興趣。該公司只專注於實現 AGI,對最終用戶體驗不感興趣。」

不得不說,在 OpenAI, Xai 等一眾商業公司中,DeepSeek 選擇的這樣「離經叛道」的商業範式,倒頗有一股不忘初心、押注未來的意味,這也讓人更加期待 R2 的到來。
三、Anthropic
報告中還提到了另一家和 DeepSeek 處境相似的公司:Anthropic 。在 AI 世界中,算力即生產力,而 Anthropic 和 DeepSeek 一樣,也受算力有限影響。
那麼 Anthropic 是怎麼應對的呢?
Anthropic 將產品開發的重點放在代碼上,並在 Cursor 等編碼應用程序中得到了廣泛採用。 經過市場檢驗後,Anthropic 推出了 Claude Code,這是在其終端中內置的編碼工具。
一經推出,Claude Code 的使用量猛增,令 OpenAI 的 Codex 望塵莫及,但這也給公司的算力帶來了巨大的壓力。
Anthropic 破局的策略主要有兩點。
-
首先是積極與亞馬遜和Google等雲服務巨頭合作,以獲取更多的計算資源。
Anthropic 從亞馬遜獲得了超過五十萬個 Trainium 芯片,然後把它們用於推理和訓練。
Anthropic 還從 Google Cloud Platform 租用了大量計算資源,特別是 TPU。
-
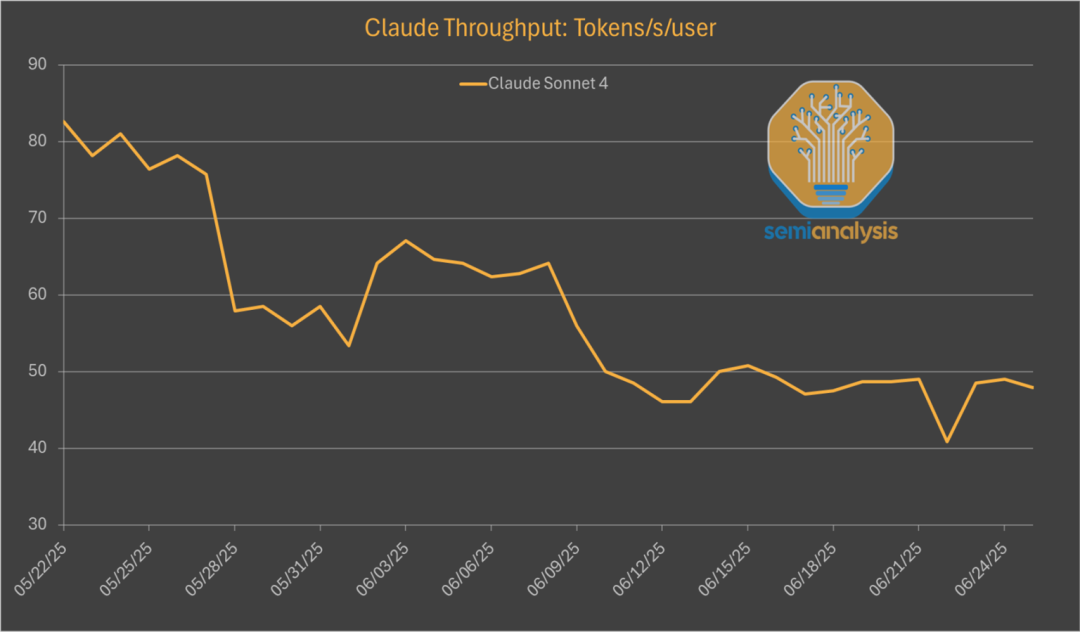
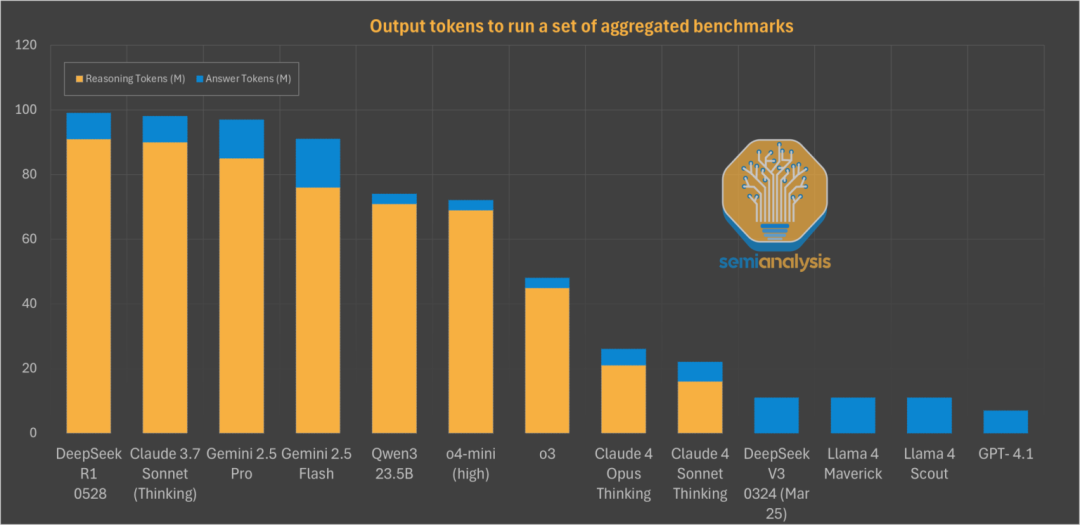
其次是通過優化模型,使得模型在回答問題時使用的 token 數量更少。
這意味著,即使 Anthropic 的輸出速度(tokens per second)較慢,但由於其回答更精煉,完成任務的總時間可能與競爭對手相當甚至更短,從而在一定程度上彌補了速度上的不足。
四、國內網民的態度
除了外媒的點評,國內網民對於 DeepSeek 的「抽水」更是一直沒斷過。
1、「抽水」使用體驗
原因主要有:速度太慢、幻覺問題、服務器繁忙無法使用、和諧問題。



2、轉用其他模型
大模型行業的競爭日益加劇,各家模型迭代層出不窮。
自 R1 發佈後這半年來,GPT-4.5、Gemini 2.5、文心大模型4.5、通義千問3、Claude 4、Grok 4、Kimi K2 相繼發佈。雖然在 5 月,R1 進行了一次重要更新,但 R2 的推出一再被延遲,一次更新似乎並不足以留住用戶轉向新迭代出的其他模型。



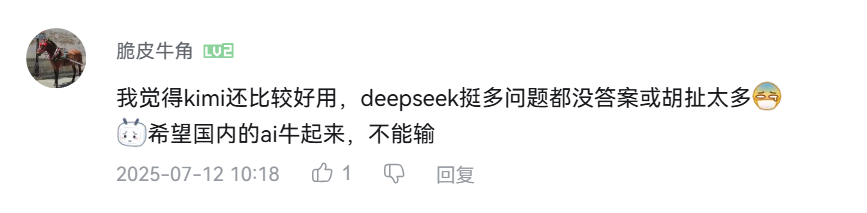
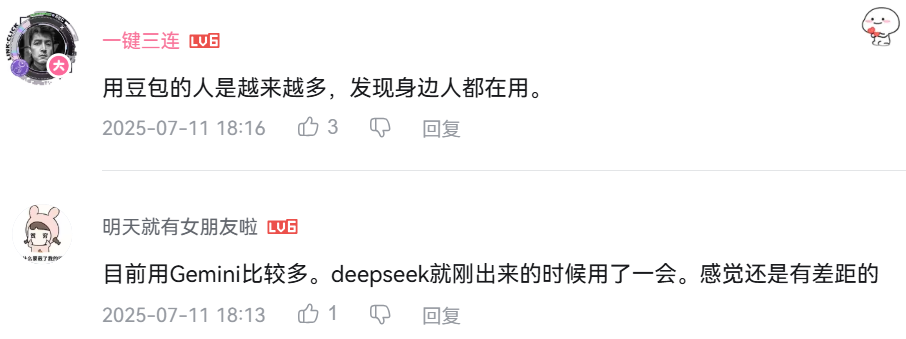
3、堅定擁護
也有很多對 DeepSeek 的積極評價,整體評價風向向好。
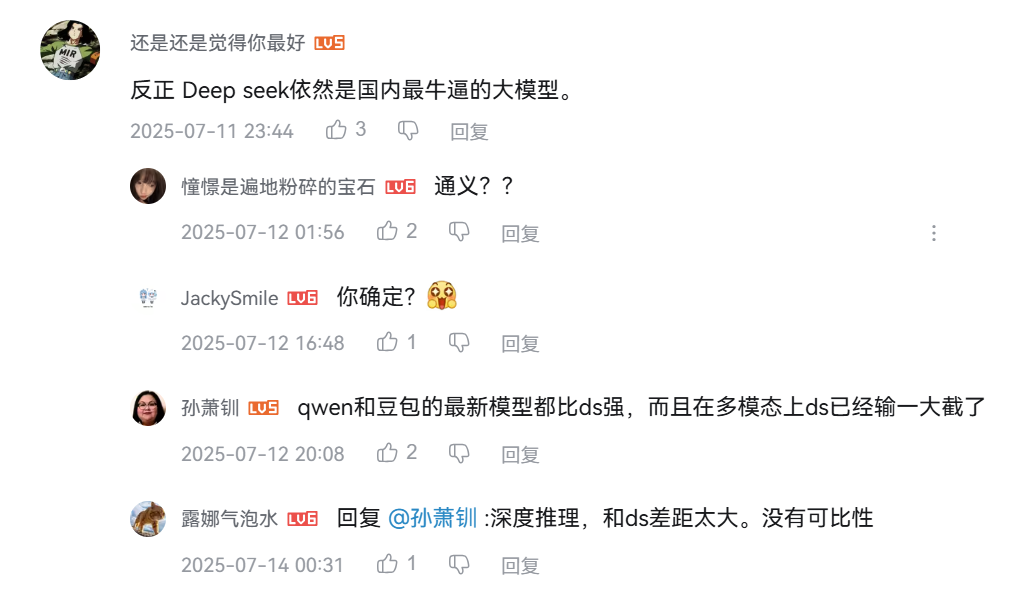
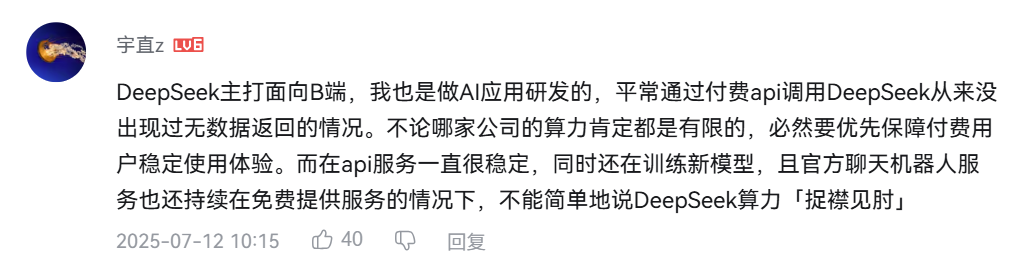

也有網民指出用開源模型的數據和閉源比不公平,加上 DeepSeek 第三方託管平台多,官方平台網頁的使用量並不能對標模型的能力。

五、最後一句
從上文中可以看到大模型行業在計算資源、商業模式和技術發展之間的複雜平衡。
DeepSeek 選擇了一條獨特的道路:通過犧牲用戶體驗來最大化研發資源,通過開源策略擴大全球影響力。而 Anthropic 則在資源限制下努力優化效率,提供更好的用戶體驗。

Grok4 剛剛推出, GPT5、Gemini3 快要推出的「小道消息」各網瘋傳,大模型行業的競爭愈演愈烈。
價格戰只是表象,真正的較量在於如何在有限資源下實現技術突破,以及如何在商業成功與技術理想之間找到平衡。
>/ 本期作者:Tashi & JackCui
>/ JackCui:AI領域從業者,畢業於東北大學,大廠算法工程師,熱愛技術分享。