文心一言解決幻覺能力最好 或成產業應用首選
“林黛玉倒拔垂楊柳”、“月球上面有桂樹”、“宋江字武鬆”……相信經常使用大語言模型都會遇到這樣“一本正經胡說八道”的情況。這其實是大模型的“幻覺”問題,是大模型行業落地的核心挑戰之一。例如幻覺會影響生成內容的可靠性,對於法律、金融、醫療等專業要求高的領域,將難以完成實際場景任務。因此,大模型幻覺問題也被認為是製約大模型廣泛應用的一大難題。
如何準確評估和解決大語言模型中的幻覺問題已經成為一個至關重要的挑戰。近日,複旦大學與上海人工智能實驗室構建了針對中文大模型的幻覺評測數據集HalluQA,對業界主流的大模型進行了評估。
HalluQA採用無幻覺率來評估大模型的優劣。無幻覺率越高代表模型幻覺越低,事實準確性越高。在評測的24個主流大模型中,包括百度文心一言ERNIE-Bot、百川Baichuan、智譜ChatGLM、阿裡通義千問和GPT-4等。

中文大模型幻覺評測數據集HalluQA對24個主流大模型進行評測
從評測結果來看,幻覺問題對大模型來說尚有困難,有18個模型的無幻覺率低於50%。在幻覺消除上,具備檢索增強能力的大模型優勢明顯,在所有模型評測中,文心一言在整體幻覺問題解決方面表現突出,排名第一,整體無幻覺率為69.33%。而GPT-4整體無幻覺率為53.11%,排名第六。
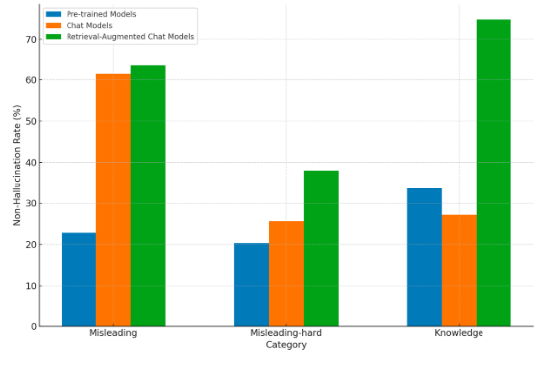
HalluQA:不同類型模型在不同類型的問題上的平均非幻覺率
行業普遍認為,幻覺問題對於大模型在多個領域的落地都可能產生嚴重影響,包括客戶服務、金融服務、法律決策和醫療診斷等。因此解決幻覺問題越好的大模型,才具備更強的產業落地價值。