Meta「分割一切」進化2.0,一鍵跟蹤運動物體,代碼權重數據集全開源,網民:真正的OpenAI
又是發佈即開源!
Meta「分割一切AI」二代SAM2在SIGGRAPH上剛剛亮相。
相較於上一代,它的能力從圖像分割拓展到影片分割。
可實時處理任意長影片,影片中沒見過的對象也能輕鬆分割追蹤。

更關鍵的是,模型代碼、權重以及數據集通通開源!
它和Llama系列一樣遵循Apache 2.0許可協議,並根據BSD-3許可分享評估代碼。
網民yygq:我就問OpenAI尷尬不尷尬。

Meta表示,此次開源的數據集包含51000個真實世界影片和600000個時空掩碼(masklets,spatio-temporal masks),規模遠超此前最大同類數據集。
可在線試玩的demo也同步上線,大家都能來體驗。
在SAM之上加入記憶模塊
相較於SAM一代,SAM2的能力升級主要有:
支持任意長影片實時分割
實現zero-shot泛化
分割和追蹤準確性提升
解決遮擋問題

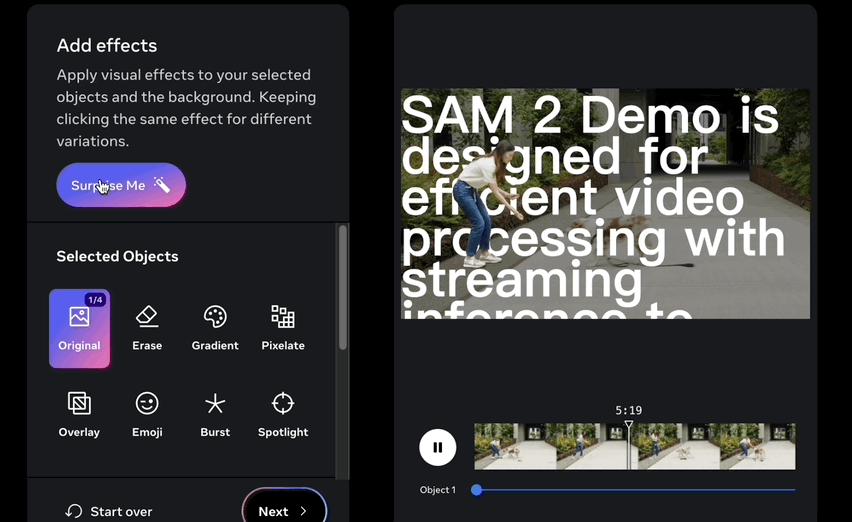
它進行交互式分割的過程主要分為兩步:選擇和細化。
在第一幀中,用戶通過點擊來選擇目標對象,SAM2根據點擊自動將分割傳播到後續幀,形成時空掩碼。
如果SAM2在某些幀中丟失了目標對象,用戶可以通過在新一幀中提供額外的提示來進行校正。
如果在第三幀中需要需要恢復對象,只需在該幀中點擊即可。

SAM2的核心思路是將圖像視作單幀影片,因此可以從SAM直接擴展至影片領域,同時支持圖像和影片輸入。
處理影片唯一的區別在於,模型需要依賴內存來回憶處理過的信息,以便在當前時間步長上準確分割對象。
與圖像分割相比,影片分割中,物體的運動、變形、遮擋和光線等都會發生強烈變化。同時分割影片中的對象需要瞭解實體跨越空間和時間的位置。

所以Meta主要做了三部分工作:
設計一個可提示的視覺分割任務
在SAM基礎上設計新模型
構建SA-V數據集

首先,團隊設計了一個視覺分割任務,將圖像分割任務推廣到影片領域。
SAM被訓練成以圖像中的輸入點、框或掩碼來定義目標並預測分割掩碼(segmentation mask)。
然後訓練SAM在影片的任意幀中接受prompt來定義要預測的時空掩碼(masklet)。
SAM2根據輸入提示對當前幀上的掩碼進行即時預測,並進行臨時傳播,在所有幀上都可生成目標對象的掩碼。
一旦預測到初始掩碼,就可以通過任何幀中向SAM2提供額外提示來進行迭代改進,它可以根據需要重覆多次,直到獲取到所有掩碼。
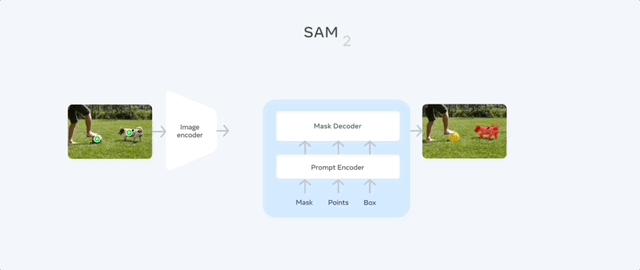
通過引入流式記憶(streaming memory),模型可以實時處理影片,還能更加準確分割和跟蹤目標對象。
它由記憶編碼器、記憶庫和記憶注意力模塊組成。讓模型一次只處理一幀圖像,利用先前幀信息輔助當前幀的分割任務。
分割圖像時,內存組件為空,模型和SAM類似。分割影片時,記憶組件能夠存儲對象信息以及先前的交互信息,從而使得SAM2可以在整個影片中進行掩碼預測。
如果在其他幀上有了額外提示,SAM2可以根據目標對象的存儲記憶進行糾錯。
記憶編碼器根據當前預測創建記憶,記憶庫保留有關影片目標對像過去預測的信息。記憶注意力機制通過條件化當前幀特徵,並根據過去幀的特徵調整以產生嵌入,然後將其傳遞到掩碼解碼器以生成該幀的掩碼預測,後續幀不斷重覆此操作。

這種設計也允許模型可以處理任意時長的影片,不僅對於SA-V數據集的註釋收集很重要,也對於機器人等領域應有有影響。
如果被分割對象比較模糊,SAM2還會輸出多個有效掩碼。比如用戶點擊了單車的輪胎,模型可以將此理解為多種掩碼,可能是指輪胎、可能是指單車全部,並輸出多個預測。
在影片中,如果在一幀圖像中僅有輪胎可見,那麼可能需要分割的是輪胎;如果影片後續幀中很多都出現了單車,那麼可能需要分割的是單車。
如果還是不能判斷用戶到底想分割哪個部分,模型會按照置信度進行選擇。
此外,影片中還容易出現分割對象被遮擋的情況。為瞭解決這個新情況,SAM2還增加了一個額外的模型輸出「遮擋頭」(occlusion head),用來預測對像是否出現在當前幀上。

此外,在數據集方面。
SA-V中包含的影片數量是現有最大同類數據集的4.5倍,註釋量則是53倍。

為了收集到如此多的數據,研究團隊構建了一個數據引擎。人工會利用SAM2在影片中註釋時空掩碼,然後將新的註釋用來更新SAM2。多次重覆這一循環,就能不斷迭代數據集和模型。
和SAM相似,研究團隊不對註釋的時空掩碼進行語義約束,而是更加關注完整的物體。
這一方法讓收集影片對象分割掩碼速度也大幅提升,比SAM快8.4倍。
解決過度分割、超越SOTA
對比來看,使用SAM2可以很好解決過度分割的問題。

實驗數據顯示,和半監督SOTA方法比較,SAM2各項性能都表現不錯。

不過研究團隊也表示,SAM2還有不足,比如可能會跟丟對象。如果相機視角變化大、在比較擁擠的場景里,就容易出現這類情況。所以他們設計了實時交互的模式,支持手動修正。

以及目標對象移動過快,可能會細節上有缺失。

最後,模型不僅開源支持免費使用,並已在Amazon SageMaker 等平台上託管。
值得一提的是,有人發現論文中提到SAM2訓練是在256塊A100上耗時108小時完成,對比SAM1則花了68小時。
從圖像分割擴展到影片領域,成本如此低?

參考鏈接:
[1]https://ai.meta.com/blog/segment-anything-2/
[2]https://x.com/swyx/status/1818074658299855262
本文來自微信公眾號「量子位」,作者:明敏,36氪經授權發佈。