OpenAI開啟推理算力新Scaling Law,AI PC和CPU的機會來了
夢晨 金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
OpenAI的新模型o1,可謂是開啟了Scaling Law的新篇章——
隨著更多的強化學習(訓練時計算)和更多的思考時間(測試時計算),o1在邏輯推理能力上已經達到了目前天花板級別。
尤其是在北大給出的一項評測中,o1-mini模型的跑分比o1-preview還要高:

這就展示一種新的思路和可能性——
小模型專門加強推理能力,放棄在參數中存儲大量世界知識。
OpenAI科學家趙盛佳給出的解釋是:
o1-mini是高度專業化的模型,只關注少部分能力可以更深入。

但與此同時,也出現了另一個問題:
若是想讓AI同時掌握高階推理能力和大量知識的任務應該怎麼辦?
於是乎,技術的聚光燈再次對焦到了大模型和RAG的組合。
具體而言,向量數據庫讓大模型能夠快速有效地檢索和處理大量的向量數據,為大模型提供了更豐富和準確的信息,從而增強了模型的整體性能和應用範圍。
可以說是讓大模型有了「好記憶」,減少出現答非所問的情況。

而且這一次,小模型專業化的新趨勢還對RAG中的向量數據庫提出了更高的要求:
一方面是小模型存儲的知識少了,對於外部知識存儲和檢索的質量要求就更高。
另一方面是AI應用落地的腳步加快,面對多用戶、高併發的場景,對整個系統的性能也更高。
在此背景下,業界先進企業正將目光投向更強大的分佈式向量數據庫。
向量數據庫代表玩家星環科技就和英特爾強強聯手,對此提出了一種新解法:
用更強性能的數據中心CPU與酷睿™Ultra支持的AI PC組合,加上專門優化過的分佈式向量數據庫,提供更經濟、更通用的方案,有效解決企業部署大模型的瓶頸問題。
分佈式向量數據庫助推RAG加速大模型應用落地
正如我們剛才提到的,RAG的重要組成部分就是外掛的專業知識庫,因此這個知識庫中需得涵蓋能夠精準回答問題所需要的專業知識和規則。
而要構建這個外掛知識庫,常見的方法包括向量數據庫、知識圖譜,甚至也可以直接把ElasticSearch數據接入。
但由於向量數據庫具備對高維向量的檢索能力,能夠跟大模型很好地匹配,效果也較好,所以成為了目前主流的形式。
向量數據庫可以對向量化後的數據進行高效的存儲、處理與管理。
如下圖展示的那樣,數據向量化過程利用了諸如詞向量模型和卷積神經網絡等人工智能技術。

通過Embedding過程,這些技術能夠將文本、圖像、音影片等多種形式的數據轉換成向量形式,並將其存儲在向量數據庫中。
至於向量數據庫的查詢功能,則是通過計算向量間的相似度來實現的。
星環科技所提出的創新成果,便是無涯·問知Infinity Intelligence。
這是一款基於星環大模型底座,結合個人知識庫、企業知識庫、法律法規、財經等多種知識源的企業級垂直領域問答產品,可以實現企業級智能問答。
例如面對「國家大基金三期會投向哪些領域」這樣非常專業的問題,無涯·問知不僅可以輕鬆作答,還能提供相關圖譜、關鍵信息等:

而且還能圖文並茂地展示作答:

上傳本地的影片文件等,無涯·問知「唰唰唰」地就可以做總結:

整體來看,無涯·問知在個人知識庫上,支持用戶一鍵上傳文檔、表格、圖片、音影片等多模態數據,快速實現海量多模知識的檢索與智能問答。
在企業知識庫方面,則是通過管理端構建企業知識庫後,員工可以基於企業知識庫進行問答,知識庫作為企業內部的知識共享平台,促進不同團隊和部門之間的協作和信息交流。
除此之外,無涯·問知內置了各大交易所的交易規則、監管要求等常見的法律法規知識,用戶可針對法律法規的具體條款、監管規則、試行辦法等提出問題,無涯·問知將提供法律風險預警以及應對建議。
它還內置了豐富的上市公司財報和產業鏈圖譜數據,能夠為金融機構提供全面深入的投資研究分析工具。
即便是面對金融、法律等眾多既要求時效性、又要求數據隱私的行業,星環也有無需上雲聯網的無涯問知AI PC版,它可以在配備英特爾® 酷睿™ Ultra的主流個人電腦上,基於集成顯卡和NPU流暢運行。
它不僅具備強大的本地化向量庫,支持多格式、不限長度的文件資料入庫,還支持影、音、圖、文等多模態數據的「知識化」處理,以及「語義化」查詢和應用能力,極大地豐富了知識獲取和應用場景。

無涯·問知可以算是星環知識平台Transwarp Knowledge Hub中重要的組成部分,其為用戶打通了從人工智能基礎設施建設到大數據、人工智能等研發應用的完整鏈條。
值得一提的是,TKH同樣提供了AI PC版本,基於本地大模型技術,能夠回答用戶各類問題,為用戶帶來文檔總結、知識問答等全新體驗,同時保障用戶隱私數據安全。
AI PC版本星環大模型知識庫提供本地大模型和遠程大模型供選擇,簡單問題可以由本地模型快速處理,而複雜疑難問題則可以提交給雲端大模型進行深入分析。
這種彈性擴展的能力,確保了企業在面對不同挑戰時,都能夠獲得足夠的計算支持。

而這一系列產品之所以能夠做到在雲端和本地都能提供高效的知識管理和智能化工具,離不開星環科技自研的幾個關鍵技術。
首先就是基於星環自研向量數據庫Hippo的向量索引技術,能夠在龐大的數據集中快速精準地召回相關信息,提升了信息檢索的速度和準確性,使模型在處理查詢時更加高效。
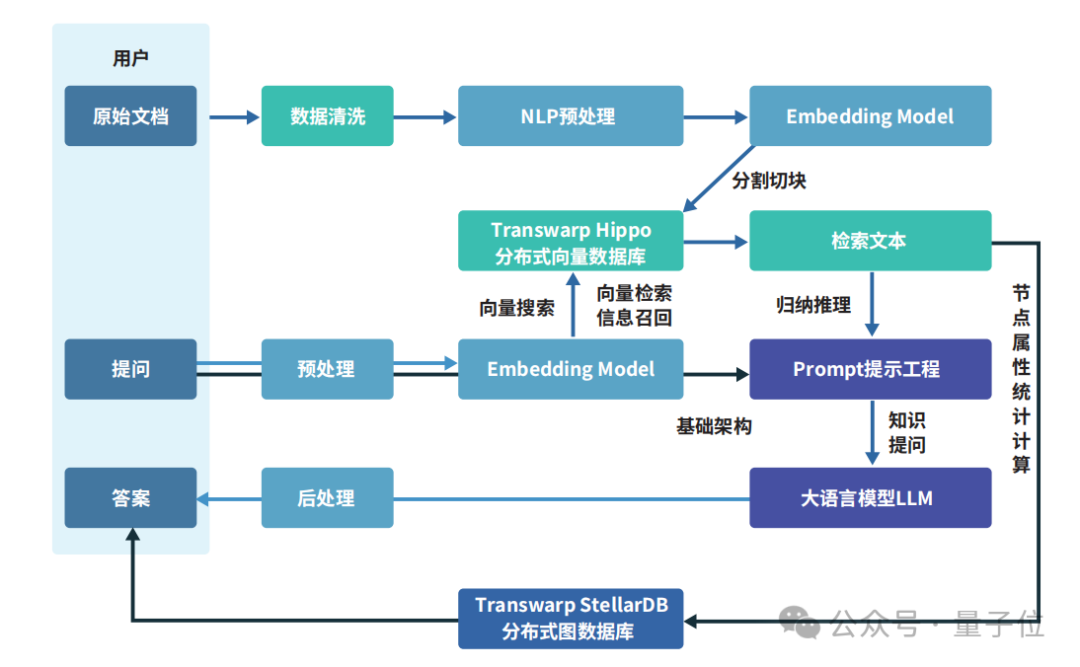
其次是利用了圖計算框架,讓大模型能夠識別實體間的多層次關係,從而進行深度的關聯分析,提供了更為深入和準確的洞察結論。
在數據方面,覆蓋官方資訊、門戶類網站、自媒體財經等1600多個信息源,涵蓋了全市場的各類宏觀、價格指數以及大部分新聞數據。
不僅包括通常渠道可獲取的數據,還包含高可信度、擁有第一手資料的新聞合作商數據,同時也對所有官方政策數據進行實時全覆蓋。
但隨著大模型的發展,數據規模可謂是極速暴增,這就對數據庫和智能問答的性能提出更高要求。
因此,數據壓縮、算力提升也成為了各個大模型玩家發力的關鍵點。
在這方面,星環科技與英特爾深度合作,從端側的AIPC到後端的數據中心和雲,通過軟硬協同優化為大模型的應用落地打造了可行的方案。
CPU助力向量數據庫應用性能大幅提升
向量數據庫搭配CPU,其實本來就已經是行業內現階段的主流共識。
究其原因,向量相似度檢索、高密度向量聚類等都屬於CPU密集型負載。因此,CPU的性能至關重要。
第五代英特爾® 至強® 可擴展處理器,正是帶來了一系列面向AI時代的關鍵特性更新。
首先,它搭載了更大容量的高帶寬內存,有效緩解了向量數據庫中數據密集型工作負載的內存牆問題。
此外,它還集成了英特爾® AMX(高級矩陣擴展)加速引擎,能高效地處理向量數據庫查詢所需的矩陣乘法運算,並在單次運算中處理更大矩陣。
對於雲端部署的版本來說,搭載第五代至強® 處理器後,星環Transwarp Hippo的 整體性能較第三代提升高達2.07倍。
那麼本地AI算力,是否能支撐在AI PC上使用大模型來支持企業應用呢?
星環嘗試後給出了答案:完全夠用。
從AI PC誕生到現在近一年時間,整體AI算力提升了200%多,能耗又降低了50%。
這背後就要歸功於英特爾® 酷睿™ Ultra系列的升級改進了。
在最新的英特爾® 酷睿™ Ultra 處理器 (第二代)200V系列處理器支持下,整個AI PC平台算力最高能達到120 TOPS。
特別是其中搭載的第四代NPU,性能比上一代強大4倍,非常適合在節能的同時運行持續的AI工作負載。

在軟件層面,英特爾和星環合作,還對數據庫底層做了性能優化。
通過水平擴展架構、基於CPU的向量化指令優化、多元芯片加速等技術,有助於分佈式向量數據庫發揮並行檢索能力,為海量、多維向量處理提供強大算力支持。
經過優化後的Transwarp Hippo實現了海量、高維度向量數據處理,並具備低時延、高精確度等優勢。
同時提升了Transwarp Hippo了服務器節點的性能密度,在性能提升的同時,具備更高的每瓦性能,有助於節省單位性能的能耗支出,最終體現為降低總體擁有成本 (TCO)。
存算融合趨勢明顯,CPU大有可為
隨著OpenAI o1系列為代表的大模型不斷革新算法,大模型推理時的算力消耗正在飛速攀升,對支撐大模型運轉的基礎設施平台提出了更高的要求。
特別是對於需要頻繁訪問外部知識庫的大模型應用,存儲與計算深度融合儼然成為當務之急。
在這一技術變革大潮中,CPU成為其中關鍵角色之一。
此外,英特爾基於CPU的解決方案還為用戶帶來了更具成本優勢的選擇。由於通用CPU擁有成熟、完善的供應鏈體系和生態支持,企業用戶可以獲得穩定可靠的算力供給。
同時,英特爾® 至強® 和酷睿™ 處理器能同時覆蓋端側和雲側的算力需求,為不同的應用場景提供強大的支持。
展望未來,存算一體化的趨勢將愈發明顯。
從大模型應用的角度看,知識檢索和AI推理將不再涇渭分明,而是深度交織、彼此強化。
在這樣一個智能融合的未來圖景中,CPU作為連接存儲、網絡和各類加速器的橋樑,其地位將變得舉足輕重。
為了科普CPU在AI推理新時代的玩法,量子位開設了《最「in」AI》專欄,將從技術科普、行業案例、實戰優化等多個角度全面解讀。
我們希望通過這個專欄,讓更多的人瞭解CPU在AI推理加速,甚至是整個AI平台或全流程加速上的實踐成果,重點就是如何更好地利用CPU來提升大模型應用的性能和效率。



















