NeurIPS 2024 | FaceChain團隊新作,開源拓撲對齊人臉表徵模型TopoFR
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇論文已被NeurIPS 2024接收,論文第一作者但俊來自浙江大學&FaceChain社區,共一作者劉洋來自倫敦國王學院&FaceChain社區,通訊作者孫佰貴來自阿里巴巴&FaceChain社區,還有合作作者包括帝國理工學院丹恩健康,FaceChain社區謝昊宇、李思遠,倫敦國王學院羅山。
一、前言
在數字人領域,形象的生成需要依賴於基礎的表徵學習。FaceChain 團隊除了在數字人生成領域持續貢獻之外,在基礎的人臉表徵學習領域也一直在進行深入研究。採用了新一代的 Transformer 人臉表徵模型 TransFace 後,FaceChain 去年也是推出了 10s 直接推理的人物寫真極速生成工作,FaceChain-FACT。繼 TransFace 之後,FaceChain 團隊最近被機器學習頂級國際會議 NeurIPS 2024 接收了一篇人臉表徵學習新作, “TopoFR: A Closer Look at Topology Alignment on Face Recognition”,讓我們一睹為快。

-
論文鏈接:https://arxiv.org/pdf/2410.10587
-
開源代碼:https://github.com/modelscope/facechain/tree/main/face_module/TopoFR
二、背景
1. 人臉識別
卷積神經網絡在自動提取人臉特徵並用於人臉識別任務上已經取得了巨大的成功。訓練基於卷積神經網絡的人臉識別模型的損失函數主要分為以下兩種類型:(1)基於 Metric 的損失函數,例如 Triplet loss, Tuplet loss 以及 Center loss。(2) 基於 Margin 的損失函數,例如 ArcFace, CosFace, CurricularFace 與 AdaFace。
相比於基於 Metric 的損失函數, 基於 Margin 的損失函數能夠鼓勵模型執行更加高效的樣本到類別的比較,因此能夠促進人臉識別模型取得更好的識別精度。其中,ArcFace 成為業界訓練人臉識別模型首選的損失函數。
2. 持續同調
下面介紹一下持續同調與我們方法相關的一些知識。
持續同調是一種計算拓撲學方法,它致力於捕捉 Vietoris-Rips 複形隨著尺度參數
變化而進化的過程中所呈現的拓撲不變性特徵,其主要用於分析複雜點雲的潛在拓撲結構。近年來,持續同調技術在信號處理、影片分析、神經科學、疾病診斷以及表徵學習策略評估等領域表現出了極大的優勢。在機器學習領域,一些研究已經證明了在神經網絡訓練過程中融入樣本的拓撲特徵可以有效地提高模型的性能。
符號:

空間中的距離度量。矩陣表示點雲中各點之間的成對距離矩陣。
表示一個在
表示一個點雲,
Vietoris-Rips 複形:Vietoris-Rips 複形是從度量空間中一組點構建的特殊單純複形,可用於近似表示底層空間的拓撲結構。對於

在尺度

中所有的單純形(即子集),並且點雲中的每個成分滿足一個距離約束:,

,其包含了點雲
處所對應的 Vietoris-Rips 複形為
,我們表示點雲
此外 Vietoris-Rips 複形還滿足一個嵌套關係:

是等價的,因為構建 Vietoris-Rips 複形只需要距離信息。
和
。基於這個關係,我們能夠隨著尺度係數的增加而追蹤單純複形的進化過程。值得注意的是
同調群:同調群是一種代數結構,用於分析不同維度

隨著尺度
增加而呈現的相應變化,可以深入瞭解底層空間的多尺度拓撲信息。
)。通過跟蹤 Vietoris-Rips 複形的拓撲特徵
) 和更高維特徵 (
)、空洞 (
)、環 (
下單純複形的拓撲特徵,例如連通份量 (
持續圖和持續配對:持續圖是笛卡賓面包含與持久圖中標識的拓撲特徵的誕生和消失相對應的單純形

的索引
的多重集合,其編碼了關於拓撲特徵壽命的信息。具體來說,它總結了每個拓撲特徵的誕生時間b和消失時間d ,其中誕生時間b表示特徵被創建的尺度,而消失時間d指的是特徵被銷毀的尺度。持續配對
中點
三、方法
1. 本文動機
現存的人臉識別工作主要關注於設計更高效的基於 Margin 的損失函數或者更複雜的網絡架構,以此來幫助卷積神經網絡更好地捕捉細膩度的人臉特徵。
近年來,無監督學習和圖神經網絡的成功已經表明了數據結構在提升模型泛化能力中的重要性。大規模人臉識別數據集中天然地蘊含著豐富的數據結構信息,然而,在人臉識別任務中,目前還沒有研究探索過如何挖掘並利用大規模數據集中所蘊含的結構信息來提升人臉識別模型在真實場景中的泛化性能。因此本文致力於將大規模人臉數據集中內在的結構信息注入進隱層空間中,以此來顯著提升人臉識別模型在真實場景中的泛化性能。
我們使用持續同調技術調研了現存的基於卷積神經網絡的人臉識別模型框架數據結構信息的變化趨勢,如圖 1 與圖 2 所示,並得到了以下三個新穎觀測結論:
(i)隨著數據量的增大,輸入空間的拓撲結構變得越來越複雜
(ii)隨著數據量的增大,輸入空間與隱層空間的拓撲結構差異越來越大
(iii)隨著網絡深度的增加,輸入空間與隱層空間的拓撲結構差異越來越小,這也揭示了為什麼越深的神經網絡能夠達到越高的人臉識別精度。

圖 1:我們分別從 MS1MV2 數據集中抽樣了 1000(a)、5000(b)、10000(c)和 100000(d)張人臉圖像,並使用持續同調技術計算它們的持續圖,其中表示第j維同調。持續圖是用來描述空間拓撲結構的數學工具,其中持久圖中的第j維同調代表空間中的第j維空洞。在拓撲理論中,如果空間中高維空洞的數量越多,那麼底層空間的拓撲結構就更越複雜。如圖1(a)-1(d)所示,隨著人臉數據量的增加,輸入空間的持久圖中包含的高維空洞(如
和
)也越來越多。因此,這一實驗現象清晰地表明了輸入空間的拓撲結構也變得越來越複雜。

圖 2:(a) 我們首先使用基於 ResNet-50 架構的 ArcFace 模型對 MS1MV2 訓練集執行推斷,以此來探究數據量與拓撲結構差異之間的關係。在推斷時,batch-size 被分別設置為 256、1024 和 2048,並分別進行了 1000 次迭代。我們使用直方圖來近似這些拓撲結構差異分佈。
(b) 其次,我們使用具有不同 ResNet 架構的 ArcFace 模型在 MS1MV2 訓練集上進行推斷(batch-size=128)以此來研究網絡深度與拓撲結構差異之間的關係。
(c) 此外,我們研究了訓練過程中拓撲結構差異的變化趨勢(批量大小 = 128),發現 i) 直接使用 PH 對齊拓撲結構會導致差異急劇減少至 0,這意味著隱層空間的拓撲結構遭遇了結構崩塌現象;ii) 而我們的 PTSA 策略促進了結構差異的平穩收斂,有效地將輸入空間的結構信息注入進隱層空間。
(d) 直接使用 PH 對齊拓撲結構會導致模型在 IJB-C 測試集中出現顯著差異。我們的 PTSA 策略有效緩解了這種過擬合問題,在 IJB-C 數據集上評估過程中展現出更小的拓撲結構差異。
基於以上的觀測結論,我們可以推斷出,在大規模識別數據集上訓練人臉識別模型時,人臉數據的結構信息將被嚴重破壞,這無疑限制了人臉識別模型在真實應用場景中的泛化能力。
因此,本文研究的問題是,在人臉識別模型訓練過程中,如何在隱層空間有效地保留輸入空間的數據所蘊含的結構信息,以此提升人臉識別模型在真實場景中的泛化性能。
2. 具體策略
2.1 模型的整體架構
針對上述問題,本文從計算拓撲學角度出發,提出了基於拓撲結構對齊的人臉識別新框架 TopoFR,如下圖 3 所示。
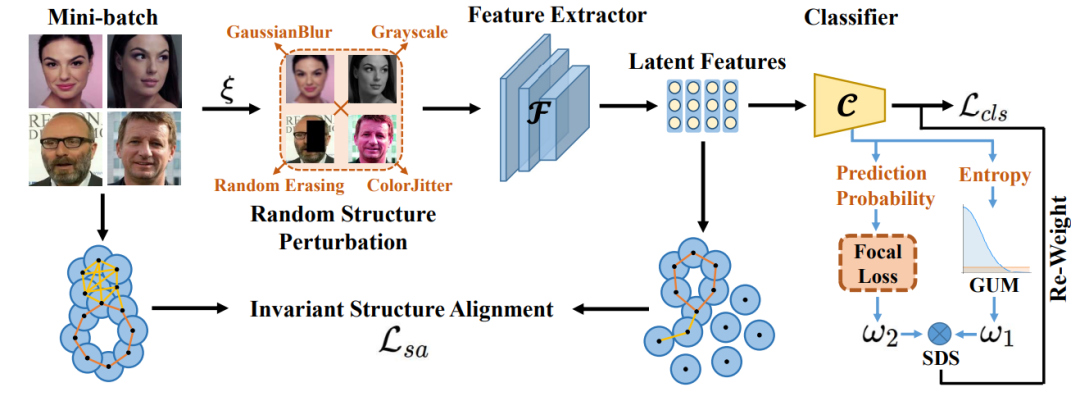
圖 3:所提出的 TopoFR 模型整體架構示意圖。
表示乘法操作。
表示對每個訓練樣本應用 RSP 的概率。
2.2 擾動引導的拓撲結構對齊策略 PTSA
我們發現,直接採用持續同調技術對齊人臉識別模型輸入空間和隱層空間的拓撲結構,難以在隱層空間上本質保留輸入空間的結構信息,進而容易導致模型的隱層空間遭遇結構崩塌現象。為瞭解決這個問題,我們提出了擾動引導的拓撲結構對齊策略 PTSA,其包含了兩個機制:隨機結構擾動 RSP 和 不變性結構對齊 ISA。
隨機結構擾動 RSP
RSP 引入了一個多樣性數據增強集合

,灰度化
運算來對其進行擾動:
,RSP 會隨機挑選一個數據增強
。對於每一個訓練樣本
以及顏色增強
,高斯模糊
,其中包含了四個常見的數據增強運算:隨機擦除

其次,擾動後的樣本
將正式送入網絡進行有監督訓練,這極大地增加隱層特徵空間的拓撲結構多樣性。我們採用 ArcFace Loss 作為基礎分類損失函數:
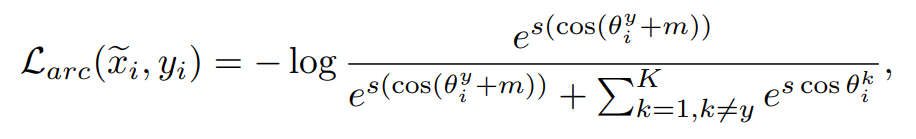
不變性結構對齊 ISA
在網絡訓練過程中,我們分別構建出原始輸入空間與擾動特徵空間


。理想地,不管輸入的人臉圖像怎樣被幹擾,其編碼在隱層空間中的位置應該保持不變。因此,我們提出對齊原始輸入空間和擾動特徵空間的拓撲結構,不變性結構對齊機制所對應的損失函數如下所示:
和持續配對
。並利用持續同調技術求解出其對應的持續圖
和
的 Vietoris-Rips 複形

2.3 結構破壞性估計 SDE
在實際的人臉識別場景中,訓練集通過會包含一些低質量的人臉圖像,這也被稱為困難樣本。這些困難樣本在隱層空間中很容易被編碼到靠近決策邊界附近的異常位置,嚴重破壞了隱層空間的拓撲結構,並會影響輸入空間和隱層空間拓撲結構的對齊。
為瞭解決這個問題,我們提出了結構破壞性估計策略 SDE 來精準地識別出這些困難樣本,並鼓勵模型在訓練階段重點學習這些樣本,逐漸引導起回歸到合理的空間位置上。
預測不確定性
困難樣本通常分佈在決策邊界附近,因此也有著較大的預測不確定性 (即分類器處的預測分佈熵較大) ,這也是其容易被錯誤分類的原因。為精準地篩選出這些困難樣本,我們提出利用高斯 – 均勻混合分佈概率模型來建模這些樣本的預測不確定性,其利用分類器處的預測熵作為概率分佈的變量:

其中,均勻分佈

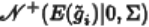
建模了簡單樣本。因此,某個樣本屬於困難樣本(即由於較大的預測不確定性)的後驗概率可以被計算為:

當分類器的預測分佈十分接近於均勻分佈時,那麼樣本屬於困難樣本的概率將十分接近於 1。
結構破壞性分數 SDS
相比於正確分類樣本,錯誤分類樣本有著更大的困難性,並且對隱層空間的拓撲結構損害更大。受 Focal Loss 設計思想的啟發,我們在衡量樣本對空間結構破壞性大小時綜合考慮了預測不確定性與預測精度,並設計出概率感知的打分機製
來自適應地為每個樣本計算結構破壞性分數 SDS:
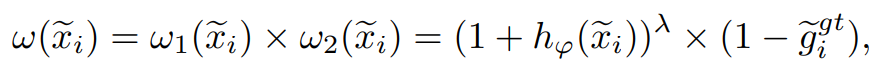
為鼓勵模型在訓練階段重點關注那些對拓撲結構破壞較大的困難樣本,我們將結構破壞性分數 SDS 加權至最終的分類損失函數上:

在訓練過程中,最小化
將帶來兩個好處:
(i)最小化
能夠有效減輕困難樣本對隱層空間結構的破壞,這有利於結構信息的保留以及清晰決策邊界的構建。
將鼓勵模型從多樣化的訓練樣本中捕捉出更有泛化性的人臉特徵。(ii)最小化結構破壞性分數 SDS
2.4 模型優化
TopoFR 模型整體的目標函數如下所示:
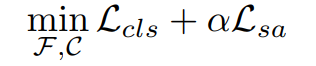
四、關鍵實驗及分析
1.1 訓練數據集與測試基準
我們分別採用 MS1MV2 (5.8M 圖像,85K 類別),Glint360K (17M 圖像,360K 類別) 以及 WebFace42M (42.5M 圖像,2M 類別) 作為我們模型的訓練集。
利用 LFW, AgeDB-30, CFP-FP, IJB-C 以及 IJB-B 等多個人臉識別測試基準來評估我們模型的識別與泛化性能。
1.2 在 LFW, CFP-FP, AgeDB-30, IJB-C 以及 IJB-B 測試基準上的實驗結果
我們可以觀察到,TopoFR 在這些簡單的基準上的性能幾乎達到了飽和,並顯著高於對比方法。此外,TopoFR 在不同 ResNet 框架下都取得了 SOTA 性能。值得一提的是,我們基於 ResNet-50 架構的 TopoFR 模型甚至超越了大部分基於 ResNet-100 的競爭者模型。

1.3 高斯 – 均勻混合分佈概率模型的有效性
為驗證高斯 – 均勻混合分佈概率模型在挖掘困難樣本方面的有效性,我們展示了模型訓練過程中利用分類器預測熵所估計的高斯分佈密度函數,如下圖 4 所示。
結果表明,被錯誤分類的困難樣本通常有著較小的高斯密度(即有著較高的高斯 – 均勻混合分佈後驗概率),因此能夠被高斯 – 均勻混合分佈概率模型輕易探測出來。提得一提的是,即使部分被錯誤分類的困難樣本有著較小的熵(即有著較大的高斯密度和較低的後驗概率),它們的結構性破壞分數
所修正。
也能被 Focal Loss

圖 4:模型訓練過程中所估計的高斯密度(藍色曲線)。綠色標記
和黑色標記
分別表示正確分類樣本和錯誤分類樣本的熵。
1.4 擾動引導的拓撲結構對齊策略的泛化性能
為表明此拓撲結構對齊策略 PTSA 在保持數據結構信息方面的一流泛化性能,我們在 IJB-C 測試集上調查了 TopoFR 模型與其變體 TopoFR-A 在輸入空間與隱層空間上的拓撲結構差異,如下圖 5 所示。值得一提的是,變體 TopoFR-A 直接利用持續同調技術來對齊兩個空間的拓撲結構。
所得到的可視化統計結果明顯地表明了我們所提出的擾動引導的拓撲結構對齊策略 PTSA 在保留數據結構信息方面的有效性和泛化性。
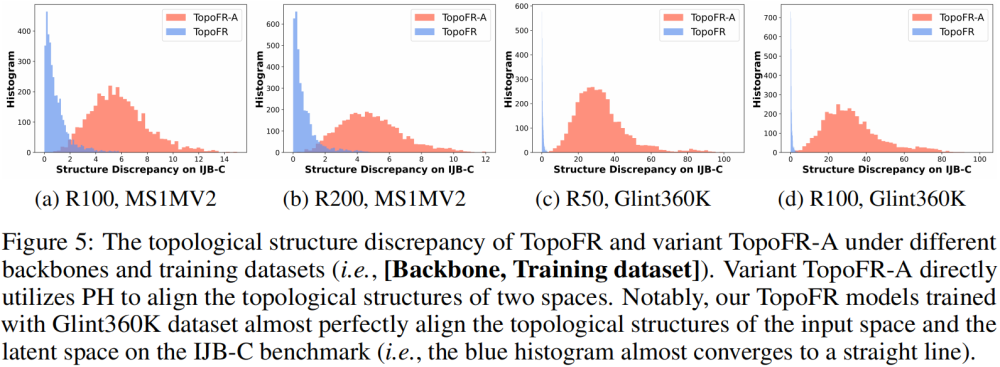
圖 5:TopoFR 和變體 TopoFR-A 在不同網絡主幹架構和訓練數據集上的拓撲結構差異 [網絡主幹架構,訓練數據集]。變體 TopoFR-A 直接利用持續同調技術對齊兩個空間的拓撲結構。值得注意的是,我們使用 Glint360K 數據集訓練的 TopoFR 模型在 IJB-C 測試集上幾乎完美地對齊了輸入空間和隱層空間的拓撲結構(即藍色直方圖幾乎收斂為一條直線)。
五、結論
本文提出了一種人臉識別新框架 TopoFR,其有效地將隱藏在輸入空間中的結構信息編碼到隱層空間,極大地提升了人臉識別模型在真實場景中的泛化性能。一系列在主流的人臉識別基準上的實驗結果表明了我們 TopoFR 模型的 SOTA 性能。



















