Nature專業戶DeepMind又登封面,開源水印技術SynthID-Text,Gemini已經用上了
機器之心報導
機器之心編輯部
現如今,大型語言模型(LLM)生成的內容已經充斥了整個互聯網,並且這些模型還能模仿各種類似真人的語氣和行文風格,讓人難以分辨眼前的文本究竟來自人類還是 AI。
這樣的問題或許可通過所謂的水印(watermarking)技術來解決。
Google開發的 SynthID 文本水印技術登上了最新一期 Nature 雜誌封面,之前機器之心已經報導過該公司開發的圖像水印技術,參閱《給 AI 生成圖像「加水印」,Google發佈識別工具 SynthID》。

給圖像和文本添加水印具有各不一樣的難點。
在給圖像添加水印時,由於人眼的辨別相近色彩和能力遠不及機器 —— 畢竟在機器「看」來,這些不同顏色本質上只是不同的數值。以下動圖展示了多張加了水印和未加水印的對比圖像。是不是完全看不來水印在哪裡?

但對於以序列形式展示的文本,人類和機器一樣可以分明地看見其中全部信息。那麼該如何給文本添加水印呢?
為了使人工智能生成的文本更易於識別,Google DeepMind 創建了 SynthID-Text,現已通過 Google Responsible Generative AI Toolkit 開源。

論文地址:https://www.nature.com/articles/s41586-024-08025-4
開源地址:https://github.com/TransluceAI
SynthID-Text 是一種可立即投入生產的文本水印方案,可保持文本質量並實現高檢測精度,同時將延遲開銷降至最低。並且,SynthID-Text 不影響 LLM 訓練,僅修改采樣程序;水印檢測計算效率高,無需使用底層 LLM。
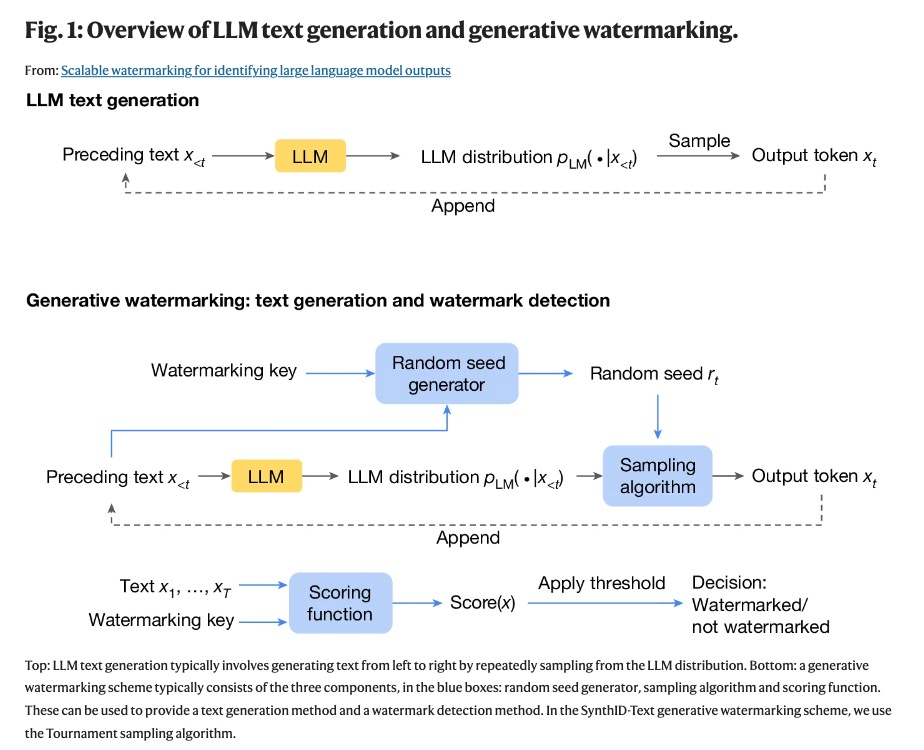
SynthID-Text 建立在以前生成水印組件的基礎上,並引入了一種新型采樣算法,即 Tournament 采樣。SynthID-Text 可以配置為非失真(保留文本質量)或失真(以犧牲文本質量為代價提高水印可檢測性)。在這兩種設置中,SynthID-Text 都提供了更高的檢測率。
簡單舉個例子,對於短語「我最喜歡的熱帶水果是__」,LLM 可能會使用 token「芒果」、「荔枝」、「木瓜」或「榴蓮」來完成句子,並且每個 token 都會給出一個概率分數。當有一系列不同的 token 可供選擇時,SynthID 可以調整每個預測 token 的概率分數,以免影響輸出的質量、準確性和創造力。

Google通過對來自 Gemini 實時互動的近 2000 萬條響應進行了大規模用戶反饋評估,結果表明:非失真 SynthID-Text 可以保持文本質量。因此,SynthID-Text 已被用於為 Gemini 和 Gemini Advanced 添加水印。這證明生成文本水印可以成功實施並擴展到現實世界的生產系統,為數百萬用戶提供服務。
此外,Google還提供了一種將生成水印與投機采樣(speculative sampling)相結合的算法,允許將 SynthID-Text 集成到大規模生產系統中,而額外的計算開銷可以忽略不計。

不過,SynthID-Text 目前僅可以處理短至三句話的文本,以及經過裁剪、解釋或修改的文本,但卻很難處理短文本、被重寫或翻譯的內容,甚至是對事實問題的回答。
Google表示:「SynthID 並不是識別人工智能生成內容的靈丹妙藥,但 SynthID 將是開發更可靠人工智能識別工具的重要組成部分。」
參考鏈接:
https://www.theverge.com/2024/10/23/24277873/google-artificial-intelligence-synthid-watermarking-open-source