圖像偽造照妖鏡:北大發佈多模態 LLM 圖像篡改檢測定位框架 FakeShield
北京大學的研究人員開發了一種新型多模態框架 FakeShield,能夠檢測圖像偽造、定位篡改區域,並提供基於像素和圖像語義錯誤的合理解釋,可以提高圖像偽造檢測的可解釋性和泛化能力。

隨著生成式人工智能(AIGC)的迅猛發展,圖像編輯與合成技術變得愈加成熟與普及。這一趨勢為圖像內容創作帶來了便捷的同時,也顯著增加了篡改檢測的難度。
用戶能夠通過 Photoshop、DeepFake、AIGC 等工具對圖像進行高質量編輯,且往往不留任何痕跡。在此背景下,如何準確檢測並定位篡改區域,成為了學術界與工業界的關注重點。
儘管現有的圖像篡改檢測與定位(IFDL)算法在網絡結構和訓練策略上取得了一定進展,但仍存在幾個主要問題:
-
1. 大多數方法採用黑箱模型,僅輸出真實性概率,缺乏詳細的檢測解釋,導致用戶對結果的信任度降低。
-
2. 現有算法通常針對特定篡改技術,缺乏應對多樣化篡改手段的能力,降低了實用性。
為瞭解決這些問題,如圖 1 所示,北京大學與華南理工大學的研究團隊提出了一種全新的任務:可解釋的圖像偽造檢測與定位(e-IFDL),並設計了一個新穎的多模態偽造檢測定位框架:FakeShield。

論文地址:https://arxiv.org/ abs / 2410.02761
項目主頁:https://zhipeixu.github.io/ projects / FakeShield/
GitHub 地址:https://github.com/ zhipeixu / FakeShield
結合多模態大語言模型的視覺和語言理解能力,實現在檢測圖像真實性,生成篡改區域掩膜的同時,提供詳細解釋,進而增強了檢測定位過程的透明性與泛化性。
 圖 1:(a) 傳統 IFDL 方法,(b) 可解釋的 IFDL 方法
圖 1:(a) 傳統 IFDL 方法,(b) 可解釋的 IFDL 方法為瞭解決現有 IFDL 方法的不足,FakeShield 提出了以下主要貢獻:
-
1. 提出了首個多模態大模型框架用於圖像篡改檢測與定位,不僅實現了檢測與定位過程的解耦,還提供了合理的判斷依據,解決了現有方法的黑箱問題。
-
2. 利用 GPT-4o 豐富現有 IFDL 數據集,構建了多模態篡改描述數據集(MMTD-Set),通過關注不同篡改特徵,生成「圖像-掩膜-描述」三元組,提高了模型的分析能力。
-
3. 設計了基於領域標籤引導的解釋性篡改檢測模塊(DTE-FDM),在單一模型中檢測多種篡改類型,緩解了數據域衝突問題。同時,通過多模態篡改定位模塊(MFLM),對齊視覺和語言特徵,實現精準的篡改區域定位。
基於上述創新,FakeShield 不僅提升了篡改檢測定位的準確性和解釋性,還顯著增強了模型的適應性和實用性,為圖像篡改檢測領域提供了一種全面而高效的解決方案。
MMTD-Set 數據集
如圖 2 所示,我們根據篡改方法,將篡改圖片分為 PhotoShop、DeepFake、AIGC-Editing 三個數據域。基於現有的 IFDL 數據集,我們利用 GPT-4o 生成對於篡改圖像的分析與描述,構建「圖像-掩膜-描述」三元組,以支持模型的多模態訓練。另外,針對不同篡改類型,我們設計了特定的描述提示,引導 GPT 關注不同的像素偽影和語義錯誤。
 圖 2:MMTD-Set 數據集構建過程
圖 2:MMTD-Set 數據集構建過程在 MMTD-Set 的構建過程中,prompt 設計是關鍵環節,旨在確保 GPT-4o 能準確生成與篡改圖像相關的高質量描述。在輸入編輯後的圖像及其二值掩膜時,prompt 的設計圍繞兩個主要方面展開:篡改區域的定位和可見細節的捕捉。
在定位描述中,GPT-4o 需要對篡改區域的絕對位置和相對位置進行清晰表達。絕對位置指篡改區域在整個圖像中的位置,如「圖像的左上角」或「靠近圖像下半部分」。相對位置則要求描述篡改區域與其他物體之間的關係,如「在桌面上方」或「靠近人群」。這種雙重描述的設計可以幫助模型更準確地感知篡改區域在圖像中的位置,確保輸出的掩膜與實際篡改區域一致。
在可見細節的捕捉上,prompt 重點關注多種視覺異常,這些異常反映了篡改過程中可能留下的偽影和邏輯錯誤。
對於 Photoshop 篡改,prompt 重點關注像素級偽影和不自然的邊緣,要求模型檢查光照一致性、像素模糊和解像度變化,同時判斷是否違反物理規律,如缺失的陰影或透視關係不合理。在 DeepFake 數據中,prompt 強調面部細節和語義邏輯,要求模型注意皮膚紋理的連貫性、表情的自然性以及光影的匹配,留意麵部對稱性和眼睛反射的異常。
對於 AIGC 編輯,prompt 聚焦於文字生成和視覺邏輯,要求分析文字拚寫是否正確、排列是否合理,並判斷場景中光影和對象位置的合理性。這種針對不同篡改類型的 prompt 設計確保了 FakeShield 在檢測與解釋上的高效性和準確性。
FakeShield 框架
如圖 3 所示,該框架包括域標籤引導的可解釋偽造檢測模塊(Domain Tag-guided Explainable Forgery Detection Module,DTE-FDM)和多模態偽造定位模塊(Multi-modal Forgery Localization Module,MFLM)兩個關鍵部分。
DTE-FDM 負責圖像偽造檢測與檢測結果分析,利用數據域標籤(domain tag)彌合不同偽造類型數據之間的數據域衝突,引導多模態大語言模型生成檢測結果及判定依據。MFLM 則使用 DTE-FDM 輸出的對於篡改區域的描述作為視覺分割模型的 Prompt,引導其精確定位篡改區域。
 圖 3:FakeShield 框架圖
圖 3:FakeShield 框架圖Domain Tag-guided Explainable Forgery Detection Module(DTE-FDM)
DTE-FDM 模塊負責圖像偽造檢測與檢測結果的分析,通過生成數據域標籤(domain tag)來緩解不同偽造類型數據(如 Photoshop 編輯、DeepFake、AIGC 編輯)之間的數據域衝突。這些標籤引導多模態大語言模型(LLM)聚焦於各類型篡改的特徵,實現針對性檢測與解釋。
在檢測過程中,輸入圖像 I_ori 通過數據域標籤生成器 G_dt 分配特定標籤 T_tag,表明該圖像的偽造類型。接著,圖像經過編碼器 F_enc 和線性投影層 F_proj 轉化為特徵向量 T_img。
這些圖像特徵與指令文本 T_ins 一併輸入 LLM,生成檢測結果 O_det,包括是否篡改、具體的篡改區域描述以及解釋性分析。
具體過程如下:

DTE-FDM 不僅判斷圖像的真實性,還根據不同偽造類型生成詳細的判定依據,包括光照一致性、邊緣偽影、解像度差異等。這種設計確保模型能夠應對多樣化的偽造場景,增強了檢測的準確性和解釋性,使 FakeShield 在應對複雜篡改任務時具有更強的泛化能力與實用性。
Multi-modal Forgery Localization Module(MFLM)
MFLM 模塊負責精準定位圖像中的篡改區域,通過多模態特徵對齊的方式將文本和視覺信息融合,從而生成準確的篡改掩膜。MFLM 的設計旨在解決僅依賴單一模態信息所帶來的定位不準確問題,增強對複雜篡改區域的識別能力。
在 MFLM 中,輸入的圖像 I_ori 經過 Tamper Comprehension Module (TCM) 編碼,將圖像特徵與解釋性文本 O_det 進行對齊。對齊後的嵌入表示通過多層感知機(MLP)投影為特殊的令牌嵌入用於指導分割模型生成篡改區域掩膜,用於指導分割模型生成篡改區域掩膜 M_loc。
整個過程如下:

其中,S_enc 和 S_dec 分別為圖像的編碼器與解碼器,Extract (⋅) 為提取嵌入的操作,通過上述步驟,MFLM 利用文本描述和圖像特徵的對齊生成準確的二值掩膜。
此外,MFLM 使用了 LoRA 微調技術,對模型進行輕量化優化,提高了處理效率並降低了計算成本。與單一模態分割方法相比,這種多模態交互的設計使得 MFLM 能夠應對更加複雜的篡改場景,如光照不一致、透視錯誤和對象拚接,從而顯著提升篡改區域的定位準確性。
實驗結果
我們對 FakeShield 與多種 IFDL 方法和多模態大語言模型(MLLM)在檢測、解釋和定位方面的性能進行了全面對比。為了確保結果的公平性,所有 IFDL 方法均在與 FakeShield 相同的數據集上進行了訓練和測試。
這一比較覆蓋了 Photoshop、DeepFake 以及 AIGC 編輯等多種篡改場景,全面評估了各模型在多模態信息融合和複雜篡改檢測中的表現。
檢測性能對比
我們與 MVSS-Net,CAT-Net 等其他先進的 IFDL 方法進行了檢測性能的對比,結果如表 1 所示。實驗結果表明,FakeShield 在 Photoshop、DeepFake 和 AIGC 編輯等數據集上的檢測準確率(ACC)和 F1 分數均顯著優於其他方法。通過引入域標籤引導策略(domain-tag guidance),FakeShield 能夠有效處理多種篡改類型,增強跨領域的泛化能力。
 表 1:FakeShield 與主流 IFDL 方法的定位性能比較
表 1:FakeShield 與主流 IFDL 方法的定位性能比較解釋性能對比
我們通過與預訓練的多模態大語言模型(M-LLMs)在 Photoshop、DeepFake 和 AIGC 編輯數據集上的表現進行對比,評估了 FakeShield 的解釋能力,結果如表 2 所示。
我們採用餘弦語義相似度(CSS)作為衡量指標,FakeShield 在各項測試中均取得了最高分數,展現了其生成準確且詳細篡改區域描述的能力。這表明,FakeShield 能夠在複雜的篡改場景中生成與真實情況高度一致的解釋性描述,大幅提升了模型在檢測過程中的可解釋性與透明度。
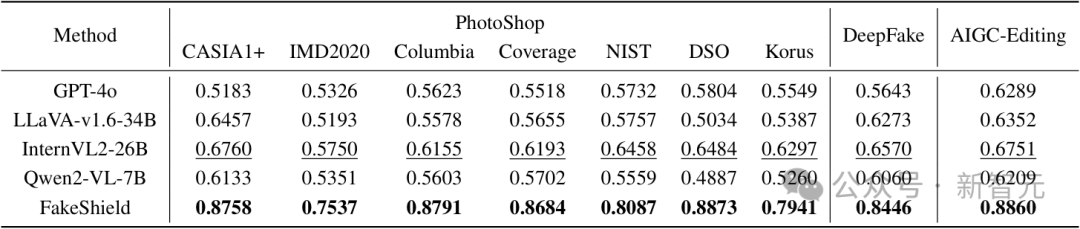 表 2:FakeShield 與主流通用 MLLM 方法的解釋性能比較
表 2:FakeShield 與主流通用 MLLM 方法的解釋性能比較定位性能對比
我們通過與其他先進的 IFDL 方法在 Photoshop 和 AIGC 編輯等數據集上的表現進行對比,評估了 FakeShield 在篡改區域定位方面的能力,結果如表 3 所示。實驗結果表明,FakeShield 在大多數測試集中均取得了最高的 IoU 和 F1 分數。
 表 3:FakeShield 與主流 IFDL 方法的定位性能比較
表 3:FakeShield 與主流 IFDL 方法的定位性能比較另外,圖 4 的主觀結果對比也表明,FakeShield 能夠生成更加清晰且精確的篡改區域分割,準確捕捉邊界,而其他方法如 PSCC-Net 則容易產生模糊且過於寬泛的預測。
 圖 4:FakeShield 與主流 IFDL 方法的定位性能的定性比較
圖 4:FakeShield 與主流 IFDL 方法的定位性能的定性比較參考資料:
-
https://arxiv.org/abs/2410.02761
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。


















