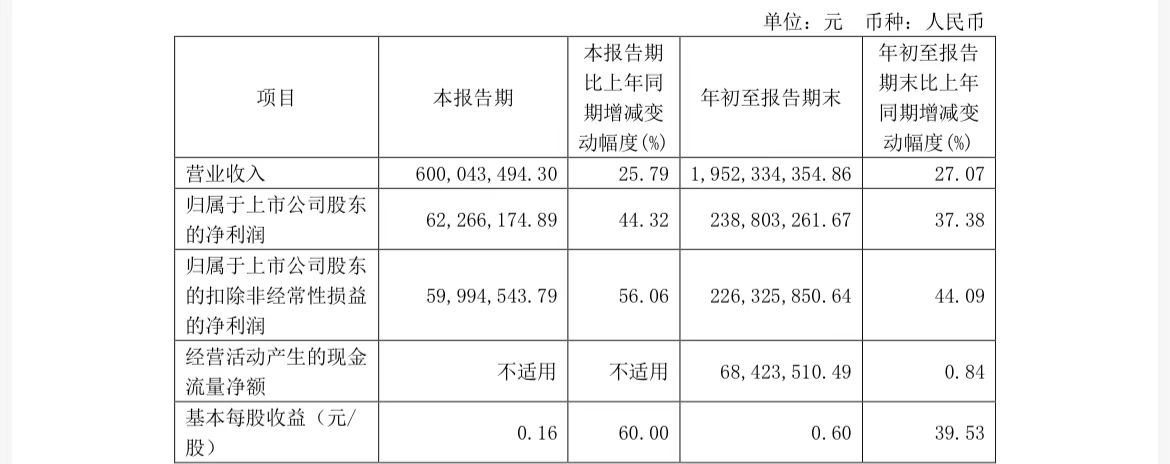
支持中英雙語及 40 種方言任意混說,中國電信 TeleAI 星辰語音大模型升級
IT之家 11 月 3 日消息,中國電信人工智能研究院(TeleAI)在今年 5 月發佈業內首個支持 30 種方言自由混說的語音識別大模型 —— 星辰超多方言語音識別大模型。
時隔不到半年,TeleAI 星辰語音大模型的多方言能力再次升級,攻克了湛江話、宜賓話、洛陽話、煙台話等方言,將方言種類從 30 種提升至 40 種,並引入對英文的識別。
與傳統的有標註訓練方法相比,TeleAI 通過預訓練語音識別模型,利用海量無標註數據進行預訓練,再通過少量有標註數據進行微調。
由於方言語音數據普遍存在無標註數據多而有標註數據少的特點,這種「預訓練 + 微調」的模型方案與方言場景的需求能夠高度契合。

TeleAI 還在模型結構和成本優化上進行了創新,實現對人工標註數據的需求量大幅降低約 50 倍,且保障模型效果與有監督訓練的方言模型水平相當。
IT之家附 GitHub 開源地址:https://github.com/Tele-AI/TeleSpeech-ASR
廣告聲明:文內含有的對外跳轉鏈接(包括不限於超鏈接、二維碼、口令等形式),用於傳遞更多信息,節省甄選時間,結果僅供參考,IT之家所有文章均包含本聲明。