大模型重構生命科學,最大基礎模型面世,解鎖DNA超長序列,參數規模達2100億
生命科學領域,已經率先進入到基礎模型時代!
今年,化學盧保獎授予了AlphaFold,AI+Science受到空前的關注。人們驚歎於,僅僅是一個蛋白質結構預測模型,就能釋放出如此巨大的行業潛力。
就在當下,在第三屆中國生物計算大會上,全球規模最大的生命科學基礎模型橫空出世——
xTrimo V3,參數規模高達2100億,覆蓋蛋白質、DNA、RNA、細胞等七大主流模態。背後玩家正是來自李彥宏孵化創辦的百圖生科。

與應用於其他行業的基礎模型有所不同,他們解碼的是生命語言,而非自然語言,意味著不僅能處理複雜的生物序列,為藥物研發、精準醫療等領域助力;還能開啟更多的前沿突破,比如在基因進化、合成生物學、設計/創造生命等方面創造價值……
這樣一個與我們每個人都息息相關的時代課題,如今竟然先於其他垂直領域,迎來了首個千億基礎模型。
並且,正像當時OpenAI推出提供免費Token一樣,它也限時提供免費Tokens,今年年底之前成功註冊的用戶,即可獲得2000 credits。
什麼概念呢?這相當於用戶可以有機會完成1300萬氨基酸Tokens的微調訓練任務。
來看看究竟這個微觀世界的基礎模型到底是怎麼一回事?
大模型時代下的生命語言解碼
在第三屆生物計算大會上,大模型是整場大會出現的關鍵詞,而大模型在生命科學領域應用的範式,也成為各個領域專家的共識——
生命科學領域有著明顯的特點,實驗驗證過的有標籤的數據很貴很少,已有的數據又是不同場景,很難用來直接訓練任務模型。但它卻擁有著海量未標註數據,像基因組數據,蛋白質序列等,這些數據非常適合用來做預訓練基礎大模型。
大模型基於這些數據預訓練之後,再結合少數標註過生物實驗室數據,學習到對生命系統深層次表徵,進而完成像蛋白質結構預測、基因序列分類等下遊任務。
而百圖生科xTrimo系列模型,正是其中最具代表性的範式實踐。
此次大會上,百圖生科xTrimo系列模型全面升級到V3版本,有著三大技術亮點值得關注。
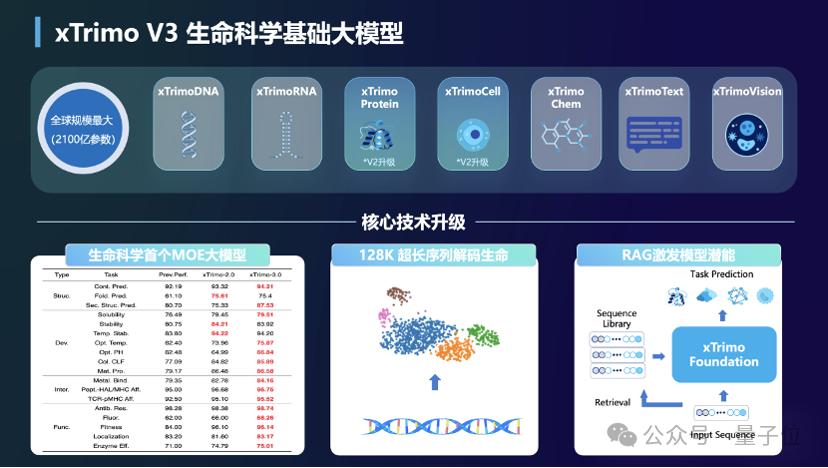
首先從大模型基礎屬性維度來看,這是目前全球規模最大的生命科學基礎大模型,總體參數規模達到了2100億。
參數規模越大,意味著蘊含更廣泛的知識和擁有更強的泛化能力,因此在各種關鍵問題和任務的解決上有更強的性能和準確性。
換句話說,大模型時代Scaling Laws,其實在生命科學領域也同樣奏效。
截至目前,xTrimo基礎大模型平台在200個任務模型達到SOTA水平,並利用這些任務模型實現了從頭設計全新蛋白質、靶點發現等創新生物項目的突破。

該平台已助力開發了20餘種前沿抗體和酶,實現10餘個創新靶點及靶點組合的挖掘,並都經過實驗驗證,進入到臨床前研發等後續階段。
再從應用維度來看,此次基礎大模型的發佈是個模態全家桶,這是解決行業問題的新利器。
此次發佈的xTrimo V3,覆蓋DNA、RNA、蛋白質、細胞、小分子、生物視覺和生物知識文本等生命科學7個主流模態。
在上一版本已有蛋白質和細胞兩大領域基礎之上,拓展到了基因組學、轉錄組學、細胞複雜任務、影像分析和文本分析等領域,從而支持從分子早期研發到生產放大再到後期實驗分析的全流程AI建模需求。
而除了實現整個探索過程的AI賦能,在一些場景下還會誕生全新的解決路徑。這是因為多模態的覆蓋,讓大模型跨模態協作成為了可能。
百圖生科技術副總裁張曉明列舉了靶點發現這一例子。
現在在細胞尺度多模態大模型視角上,靶點發現也有了新探索,可以先對未擾動的細胞進行蛋白質和細胞的兩種模態的表徵,同時擾動action可以基於生物基因註釋的文本模態生成擾動的編碼,在圖模型中預測擾動後表達量的變化以及推薦潛在的靶點,最後再通過細胞生物視覺的模型輔助做細胞功能的驗證。
這是一個包括蛋白、細胞、文本和視覺四個模態的協作典型場景,在效果和效率上都有顯著的提升。
而具體到各個模態的部署,我們也能看到很強的應用屬性,為解決問題而生。
比如首個引入MoE架構的蛋白質大模型,參數達到千億規模。
我們都知道,通用場景下MoE架構有利於垂直細分領域的處理,同樣在蛋白質領域也存在這樣的情況,比如像抗體抗原、蛋白酶等,這樣一來在各種具體下遊任務下,實現更好的性能和準確率。
還有像DNA大模型序列長度躍升至128K,可以更好的捕獲遠端調控信息,實現了超長序列解碼生命的可能性。
這有點類似於通用大模型具備了長文本讀取能力,由此拓展了大模型能力的邊界,更多場景得到釋放,比如總結報告、故事創作,解放人們的生產力。
最後,再從整個行業生態來看,百圖生科已經佔好生命科學AI模型提供商這一生態位——
一邊是專業嚴謹、有著自己獨特語言的科學行業,還有大量的知識空間等待人類去探索。一邊是價值逐漸明晰、勢要重塑一切的大模型範式。百圖生科要做的正是他們的連接器。
此次除了基礎大模型的發佈,他們還建設了個一站式模型平台,相當於生命科學領域的大模型基礎設施。
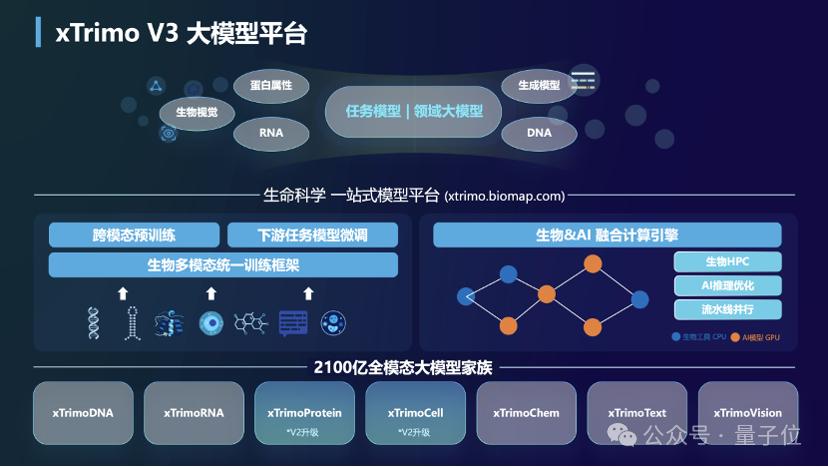
訓練端,他們給出生物多模態的統一訓練框架,從跨模態預訓練、到下遊任務的微調都可以完成。
而在推理端,他們為該領域量身定製地打造了生物與AI融合的計算引擎。
這個值得說道說道。因為在我們日常大模型語境中,可能只需要針對AI模型本身進行推理優化,就能在性能和成本上取得很好的效果。但在生物計算實際應用場景中,模型運行20分鐘,其中推理僅佔1分鐘,其餘時間都用於執行生物計算工具。
因此要打造推理引擎,需要將生物HPC優化和AI模型推理優化都要兼顧到,以及讓他們在流水線上並行運行起來。據介紹,這在多個場景實現十倍以上推理性能的提升。
此外,還配備了系列工具鏈:包含面向多種數據場景和用戶需求的Model Builder模塊,支持模型管理和組裝的Model Hub模塊,以及加速模型調用和物理計算的Model Booster模塊等。
而基於過去四年行業探索經驗,他們也系統梳理出了兩大行業解決方案:藥物研發、生物製造,為合作夥伴提供全方位的AI模型服務,加速大模型的應用。
以藥物研發為例,他們就能客戶定製化構建模型、也能支持像蛋白設計這樣的服務。
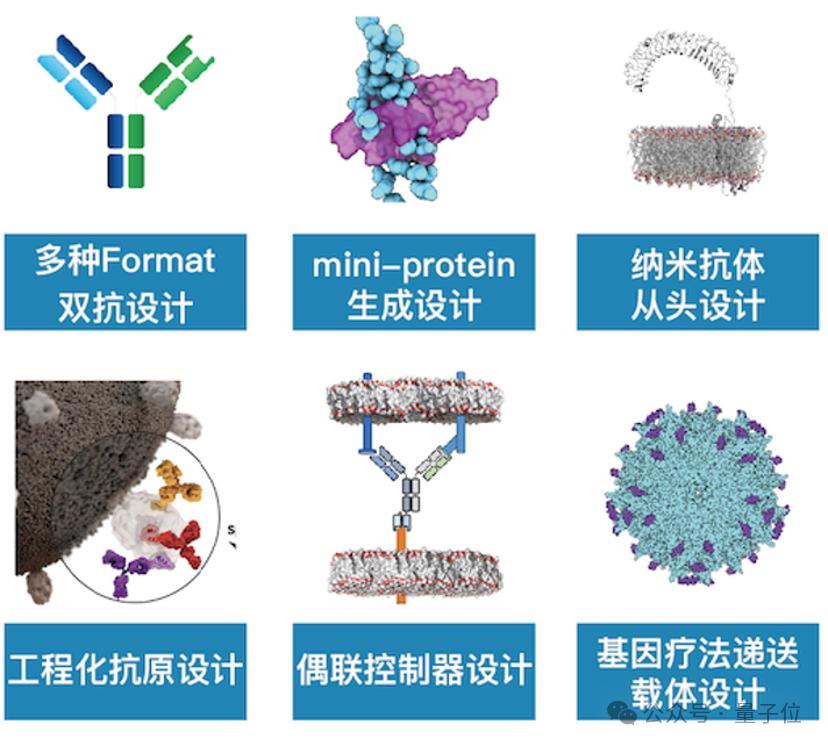
比如他們就利用親和力模型設計出多個親和力梯度的抗體,並定製AND GATE算法,組合雙抗實現靶向殺傷腫瘤細胞。通過高通量親和力檢測和 100+ 複雜構型雙抗的表達與驗證,最終交付了具有更佳治療窗口的雙抗。
過去四年間,百圖生科的全球用戶已積累超過300家,包括跨國藥企、產業巨頭、大型CRO、明星BioTech、科研機構等,總訂單超20億美元,可以說初步完成了技術和商業驗證的閉環,實現產業的初步積累。
如今有了強大的基礎模型底座,他們的目標行業也指向了更廣泛的領域,包括生物醫藥、生物製造、科研教育等。
這其實也是百圖生科選擇這一生態位的具象展現,那就是鏈接起更多的生態夥伴參與到大模型應用的進程中。
如今生命科學領域大模型正在加速落地應用,但與此同時挑戰也同樣艱巨,需要生態夥伴攜手來解決。
CEO劉維就舉了個例子,其數字化和智能化在很多方面尚未實現。諸多研發工作仍然主要以所見即所得的方式進行——
仍然以專家經驗和人類先驗假設為基礎進行實驗驗證假設,或者以在自然界中發現然後進行實驗改造為主。
而只有越來越多的企業完成大模型的賦能,才能帶動整個行業的數字化智能化。
Foundation Model+Science正在到來
藉著百圖生科生命科學基礎大模型的發佈,也是時候對「大模型如何賦能生命科學領域」做個階段性梳理。
首先,跟其他行業一樣,生命科學領域正迎來全行業的重塑,甚至比其他領域更快。
僅過去一年時間,傳統藥企巨頭擁抱AI,像輝瑞、禮來等全球藥企巨頭任命首席AI官;科技巨頭紛紛出手佈局,諸如GoogleMeta英偉達也早已相關探索。還有像賽諾菲,這種全球TOP10藥企願意砸超10億美金與百圖生科共同打造AI模型。
各種生命科學大模型也紛紛被頂刊所接收,比如像百圖生科此前發佈的單細胞大模型、千億參數蛋白大模型等工作就多次登上Nature子刊封面和學術頂會。相較於其他領域,這麼一個古老的領域的發展速度,直接來了個彎道超車。
而從時間維度來看,計算對生命科學的賦能,經歷從單模態單尺度到多模態多尺度的賦能。而在大模型語境下,就是從「AI+」到「大模型+」的時代,如今AI在生命科學里的創新應用正在迎來「寒武紀爆發」臨界點。
一切以AlphaFold為節點。
傳統依靠實驗室工具和分析手段的方式,價格高昂耗時也長,無法充分發揮數據背後的價值。
隨著AI深度學習的出現,這個問題迎來了轉機。DeepMind從人類已確定的17萬種蛋白質序列庫中訓練學習得到AlphaFold,實現了之前遠超其他所有團隊的準確率,開闢了「先假設-再驗證-最後優化假設」的乾濕實驗循環閉環。
這時候,生命科學領域迎來了他們自己的AI1.0時刻。
不過當時還只是聚焦於單鏈蛋白質單一模態,預測準確率還有大量的提升空間,海量的生物數據還沒有被充分挖掘。
而隨著自監督範式Transformer架構、擴散模型等進展的出現,讓海量各種模態的數據處理、跨模態多尺度協作處理成為了可能,更多潛在的下遊場景被實現,也就是所謂AI2.0時刻。
就像最新的AlphaFold3,實現了從單鏈蛋白質結構預測到所有生命分子的結構和相互作用的跨越。
其次,大模型賦能生命科學不僅在降本增效,還在於創新創造。
大模型對千行百業的賦能核心就在於降本增效,同樣在生命科學領域,大模型可以快速處理和分析大量的生物數據,幫助科研人員更高效地篩選潛在藥物靶點、設計藥物分子以及預測藥物效果,從而在一定程度上降低研發成本、提高研發效率。
不過這隻是大模型所帶來的最基本價值。創新創造才是大模型賦能生命科學的核心價值。
生命科學的技術壁壘很大程度上源於生命本質信息的高度複雜性,而這些信息往往隱藏在生命語言中。因此相比於常規自然語言模型,生命科學大模型往往肩負著更為重大的使命,那就是深入到生物進化、基因序列等生命領域的核心挑戰。大模型就是像是一把鑰匙,打開了一扇通往生命奧秘深處的新大門。
而一旦實現生物數據和序列的解碼,就給當前一些重大難題的解決帶來了可能性。比如精準醫療/個性化醫療。
而在基因組學、遺傳病預測和精準醫療等領域,信息的準確性至關重要。但傳統的方法常常將DNA切割成較小的片段進行分析,導致關鍵信息的丟失。
但現在百圖生科模型所實現的DNA超長序列,就能完整保留所有基因信息。這讓精準的基因分析成為可能,有助於製定出最適合患者個體的治療方案。
例如,在癌症治療中,完整的基因序列信息可以幫助確定癌細胞中特定的基因突變,從而為靶向治療提供精確的靶點,提高治療效果。
大模型帶來的除了數據處理能力,還有強大的泛化能力,給行業問題解決帶來全新的思路。
生命語言遠比自然語言複雜,模態之間存在清晰的轉化和層級關係。比如DNA、RNA、蛋白質之間的中心法則;細胞圖像,細胞組學,細胞基因表達,功能註釋文本之間對於細胞的聯合表徵;從單細胞、多細胞到構成組織。
因此大模型能做的就不僅對現有生物數據的簡單解析,更重要的是能夠推斷未知問題。
比如預測生物結構背後的功能——
可以預測某種新型蛋白質的功能,進而為設計全新的藥物或者生物技術提供可能,而這是傳統研究方法很難做到的創新突破。
還有像藥物發現,以往的研發可能更多地依賴於既有經驗和有限的實驗結果,但大模型可以通過對大量生命數據的學習和分析,提出以前未曾想到的藥物靶點或者研發方向。
而擁有了預見生命科學未知領域的 「慧眼」之後,也就為合成生物學,或者更為廣泛的生物製造,帶來了可能性。
比如在酶的設計和菌種改造方面,AI模型通過學習現有的生物數據,生成新的酶序列,並預測其催化功能。通過這種方式加速了生物製造中的酶催化過程,顯著提高了生產效率,並降低了製造成本。
再往前一步,整個工業製造領域,包括農業、食品、化工、材料、能源等行業都能被賦能覆蓋。
從理解生命到預測生命再到設計、創造生命,這也是大模型為生命科學帶來創新創造價值的重要體現。
它從根本上改變了生命科學的研究路徑和思維方式,推動生命科學朝著更深入、更具賽前分析性的方向發展。
相對於其他行業,在生命科學領域的應用價值更大、前景更高,也就更是一件長期主義的事情了。
這需要生態合作,共同推動產業發展。更需要像百圖生科這樣的玩家站出來提供基礎服務。
現在,百圖生科,邁出了第一步。
本文來自微信公眾號「量子位」,作者:賽小生,36氪經授權發佈。



















