Google DeepMind 最新研究:搞掂這三個任務?人類不行,AI 也不行
文 | 學術頭條
人工智能(AI)並非完美的推理者,即使是當前大熱的語言模型(LMs),也同樣會表現出與人類類似的錯誤傾向,尤其是出現顯著的「內容效應」(Content effects)——
人們在處理與已有知識或信念相符的信息時,推理更加準確和自信,而在處理與這些知識或信念相悖的信息時,推理可能會出現偏差或錯誤。
這一結論來自 Google DeepMind 團隊近期發表的一篇研究論文。

人類存在兩種推理系統,「直覺系統」和「理性系統」,且在推理過程中容易受到已有知識和經驗的影響。例如,當面對合乎邏輯但不合常理的命題時,人們往往會錯誤地判定其無效。
有趣的是,該研究顯示,大型 Transformer 語言模型也可以表現出類似人類的這種行為,既可以展示出直覺性偏見,也可以在提示下表現出一致的邏輯推理。這意味著,語言模型也能模擬人類的雙系統行為,也會表現出「經驗主義」錯誤。
在這項工作中,研究團隊對比了 LMs 和人類分別在自然語言推斷(NLI)、判斷三段論(Syllogisms)的邏輯有效性和 Wason 選擇任務三種推理任務上的表現。
 圖 | 三種推理任務操作內容
圖 | 三種推理任務操作內容結果發現,在三種推理任務中,LMs 和人類的表現均受語義內容合理性和可信度的影響。
這一發現揭示了當前 AI 系統在推理能力上的局限性。儘管這些模型在處理自然語言方面表現出色,但在涉及複雜邏輯推理時,仍需謹慎使用。
任務一:自然語言推理
自然語言推斷(NLI)是指模型需要判斷兩個句子之間的邏輯關係(如蘊涵、矛盾或中性)。研究表明,語言模型在這類任務中容易受到內容效應的影響,即當句子的語義內容合理且可信時,模型更容易將無效的論證誤判為有效。這一現像在 AI 領域被稱為「語義偏見」,也是人類在推理過程中常見的錯誤。
研究團隊設計了一系列 NLI 任務,測試人類和 LMs 在處理這些任務時的表現。結果顯示,無論是人類還是 LMs ,當面對語義合理的句子時,都更容易出現錯誤判斷。例如,下面這個例子:
-
輸入:水坑比海大。
-
提問:如果水坑比海大,那麼……
-
選擇:A 「海比水坑大」和 B 「海比水坑小」
雖然前提和結論之間的邏輯關係是錯誤的,但由於前提句子的合理性,LMs 和人類都容易認為 B 這個結論是正確的。通過對比,人類和語言模型在自然語言推斷任務上的錯誤率相近,表明語言模型在某些方面的推理能力已經接近人類水平,而 AI 在理解和處理日常對話時,可能會與人類一樣容易受到內容的誤導。

圖|NLI 任務的詳細結果。人類(左)和所有模型都表現出了相對較高的性能,而且在符合信念的推斷和違背信念的推斷,甚至是無意義推斷之間,準確率的差異相對較小。
任務二:三段論的邏輯有效性判斷
三段論是一種經典的邏輯推理形式,通常由兩個前提和一個結論組成。例如:「所有人都是會死的,蘇格拉底是人,所以蘇格拉底會死。」研究發現,語言模型在判斷三段論的邏輯有效性時,常常會受到語義內容的影響。儘管語言模型在處理自然語言方面表現優異,但在嚴格的邏輯推理任務中,仍然容易犯與人類相似的錯誤。
為了驗證這一點,研究人員設計了多個三段論推理任務,並對比了人類和 LMs 的表現。例如,以下是一個典型的三段論任務:
-
前提 1:所有槍都是武器。
-
前提 2:所有武器都是危險的物品。
-
結論:所有槍都是危險的物品。
在這種情況下,前提和結論的語義內容非常合理,因此 LMs 和人類都很容易判斷這個結論是正確的。然而,當語義內容不再合理時,例如:
-
前提 1:所有危險的物品都是武器。
-
前提 2:所有武器都是槍。
-
結論:所有危險的物品都是槍。
儘管邏輯上是錯誤的,但由於前提句子的合理性,LMs 和人類有時仍會錯誤地認為結論是正確的。
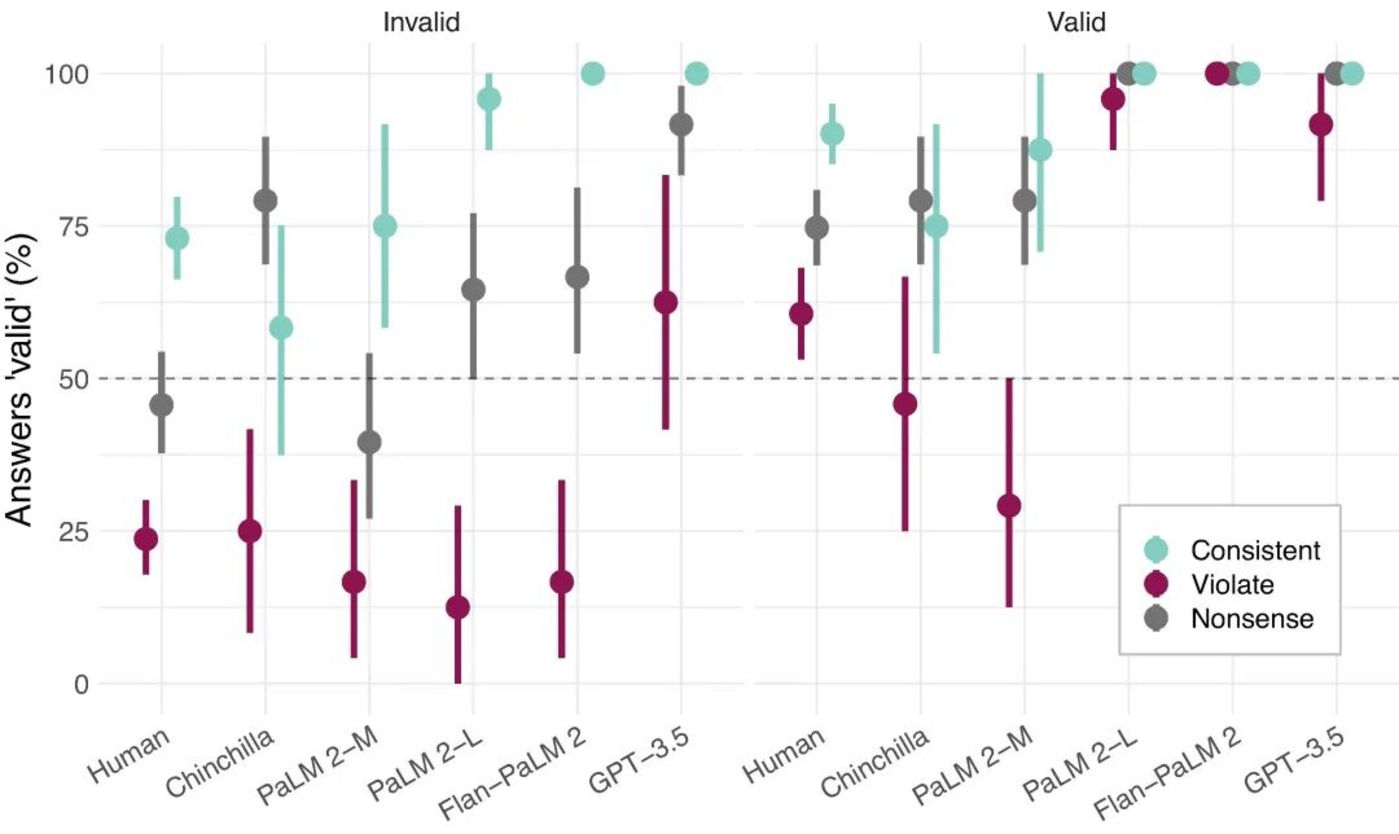
圖|三段論邏輯任務詳細結果。人類和模型都表現出明顯的內容效應 ,如果結論與預期一致(青色),會有很強的偏向性認為論證有效;如果結論違背預期(紫色),則有一定的偏向性認為論證無效 。
任務三:Wason 選擇
Wason 選擇任務是一個經典的邏輯推理任務,旨在測試個體對條件語句的理解和驗證能力。在實驗中,參與者會看到四張卡片,每張卡片上有一個字母或數字,例如「D」、「F」、「3」和「7」。任務是確定哪些卡片需要翻面,從而驗證「如果一張卡片正面是 D,那麼背面是 3」這一規則。
研究發現,語言模型和人類在這一任務和前面兩個任務一樣,錯誤率相近,且都容易選擇沒有信息價值的卡片,例如,選擇「3」,而不是「7」。出現這種錯誤是因為人類和 LMs 都傾向於選擇與前提條件直接相關的卡片,而不是那些能真正驗證規則的卡片。
然而,當任務的規則涉及到社會相關的內容(如飲酒年齡和飲料類型)時,模型和人類的表現都會有所改善。例如:
-
規則:如果一個人喝酒,他必須超過 18 歲。
-
卡片內容:喝啤酒、喝可樂、16 歲、20 歲。

圖|Wason 選擇任務詳細結果。每個語言模型都在現實規則上顯示出一定的優勢。
在這種情況下,人類和 LMs 更容易選擇正確的卡片,即「喝啤酒」和「16 歲」。這表明,在日常生活中,AI 與人類一樣,會在熟悉的情境中表現得更好。
不足與展望
總的來說,研究團隊認為,當下的語言模型在推理任務方面與人類表現相差不多,甚至犯錯的方式也如出一轍,特別是在涉及語義內容的推理任務中。雖然顯露出了語言模型的局限性,但同時也為未來改進 AI 推理能力提供了方向。
然而,這項研究也存在一定的局限性。
首先,研究團隊僅考慮了少數幾個任務,這限制了對人類和語言模型在不同任務中的內容效應的全面理解。要完全理解它們的相似性和差異性,還需要在更廣泛的任務範圍內進行進一步驗證。
另外,語言模型接受的語言數據訓練量遠遠超過任何人類,這使得難以確定這些效應是否會在更接近人類語言數據規模的情況下出現。
研究人員建議,未來的研究可以探索如何通過因果操縱模型訓練來減少內容偏見,並評估這些偏見是否在更類似人類數據規模的訓練中仍會出現。
此外,研究教育因素對模型推理能力的影響,以及不同訓練特徵如何影響內容效應的出現,也將有助於進一步理解語言模型和人類在推理過程中的相似性和差異,使其在更廣泛的應用場景中發揮更大的作用。
論文鏈接:https://academic.oup.com/pnasnexus/article/3/7/pgae233/7712372



















