鵝廠機器狗登Nature子刊封面:動作敏捷如真狗,能玩定向越野
基爾西 發自 凹非寺
量子位 | 公眾號 QbitAI
騰訊機器狗,登上了Nature子刊封面!

在它的控制下,機器狗的動作和真實世界中的狗越來越像了。
注意看,這裏的兩隻機器狗玩起了「定向越野」,還是帶追逐的那種。

遊戲當中,兩隻機器狗分別要扮演追逐者和逃脫者,逃脫者需要在不被抓到的情況下到達指定位置。
一旦它到達了指定位置,兩隻機器狗就會交換身份,如此來回進行,直到有一隻被抓住。
這個遊戲的一個難點在於有最大速度限制,兩隻機器狗都不能單獨依靠速度取勝,必須規劃出一定策略。
甚至,還有更加困難的障礙賽,戰鬥更加激烈、場面更加精彩。

這場機器人越野大賽的背後,應用的正是這套全新的控制框架。
該框架採取了分層式策略,並運用生成式模型學習了動物的運動方式,訓練數據來自一隻拉布拉多犬。
這套方法讓機器狗不再依賴物理模型或手工設計的獎勵函數,並能像動物一樣理解和適應更多的環境與任務。
像真的狗一樣運動
這隻機器狗名叫MAX,重量為14kg,每條腿上有3個行動器,可提供平均22N·m的持續扭矩,最大能達到30N·m。
MAX的一大亮點,就是實現了對真實世界中狗的模仿。
在室內環境中,MAX掙脫了研究者,然後就開始了自由跑動。

把MAX放到室外,它也能在草地上歡快地奔跑玩耍。

當遇到有障礙的複雜地形時,這種模仿就更加惟妙惟肖了。
向上,MAX可以敏捷飛快地爬上樓梯。

向下,它也能鑽過障礙物,擋在它前面的橫杆沒有被碰到一點。

這一系列的動作背後,都是MAX的控制系統從一隻拉布拉多的動作當中學習到的策略。
利用對真狗的模仿,MAX還能規劃更高級的策略,完成更為複雜的任務,前面展示的追逐大戰就是一個很好的例子。
值得一提的是,除了讓兩隻機器狗相互競技之外,研究人員也通過手柄控制加入到了這場戰鬥。
從畫面中不難看出,真人控制模式下的機器狗(下圖中1號),反而不如純機器方案(2號)來得靈活。

最終的結果是,在開了掛(人類控制的機器狗最大限速更高)的情況下,人類仍然以0:2的比數徹底輸給了機器。
除了能讓機器狗靈活運動,該框架最大的優勢就是通用性,可以針對不同的任務場景和機器人形態進行預訓練和知識複用。
未來,團隊還計劃把該系統遷移至人形機器人和多智能體協作的場景。
所以,Robotics X實驗室的研究人員是如何打造出這套方案的呢?
加入生成式模型的分層框架
研究人員設計這套控制框架的核心思路,就是模仿真實動物的運動、感知和策略。
該框架通過構建可預訓練、可重用和可擴展的原始級、環境級和策略級知識,使機器人能夠像動物一樣從更廣泛的視角理解和適應環境與任務。
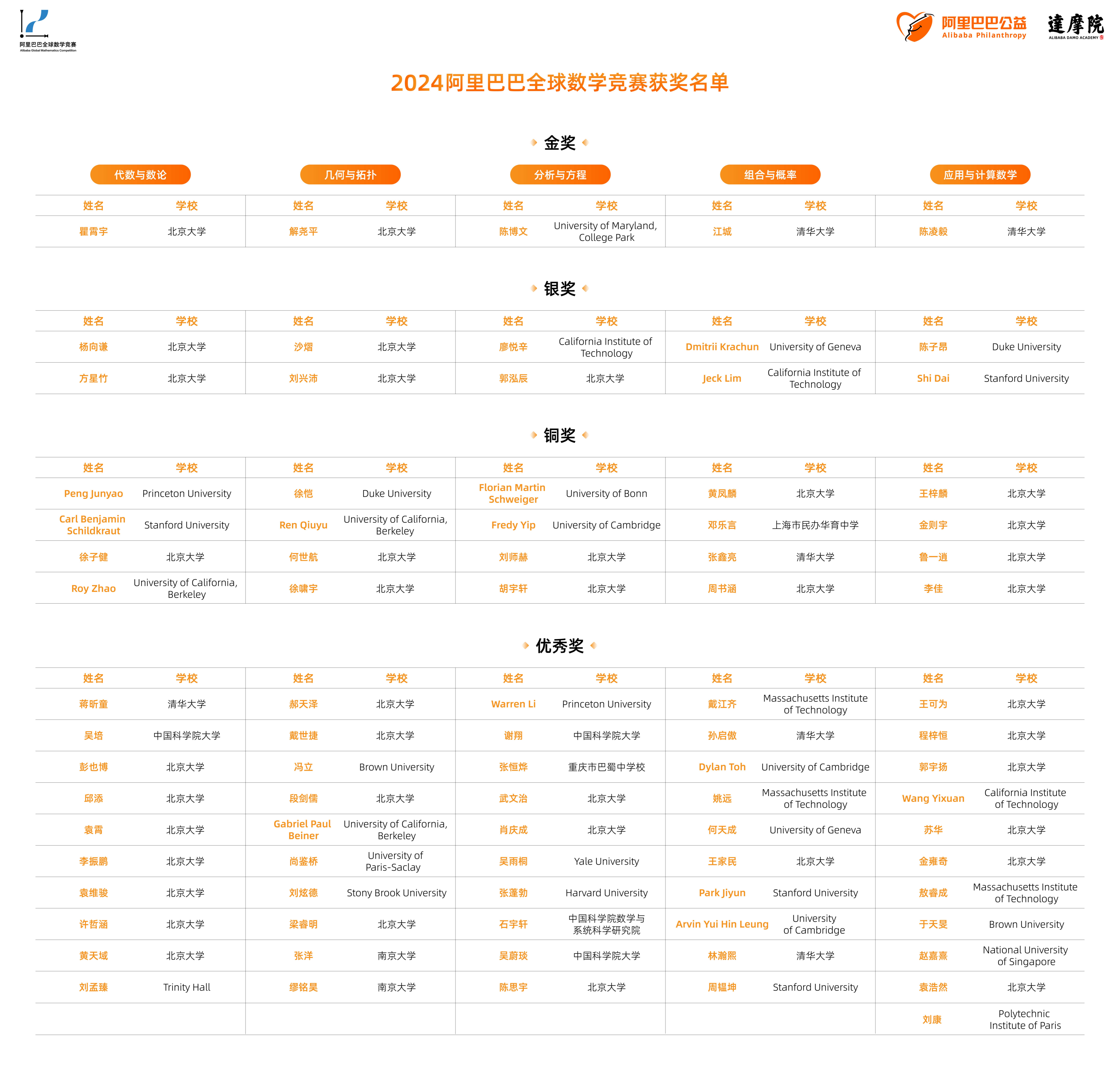
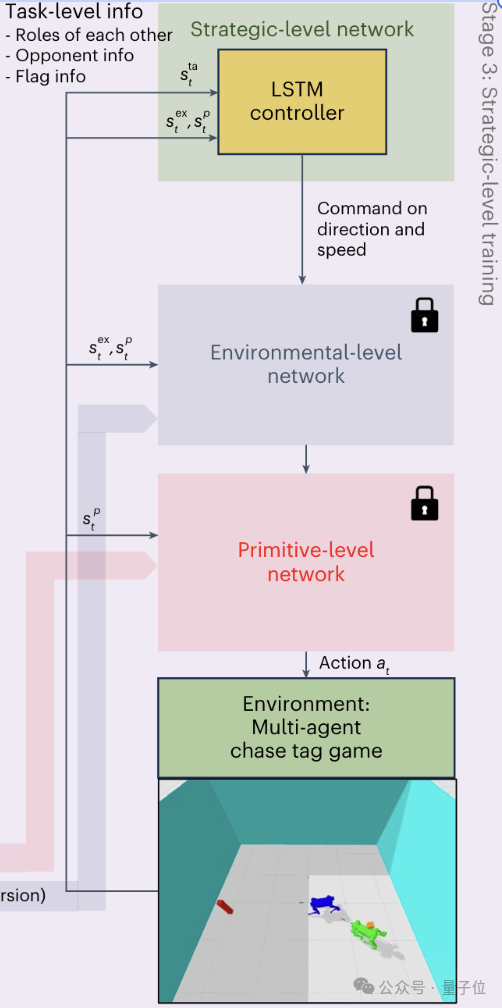
具體實現上,該框架也採用了分層式的控制方式,之中的三個層級——原始運動控製器(PMC)、環境適應控製器(EPMC)和策略控製器(SEPMC)——分別與原始級、環境級和策略級知識形成了對應。
首先,人類會發出一個高級的指令(比如告訴機器競速追逐遊戲的規則和目標),這也是(運行過程)全程唯一需要人參與的地方。
這個高級指令會被SEPMC接收,並根據當前情況(如機器人角色、對手位置等)製定策略,然後生成包括移動方向、速度等信息的導航命令。
導航命令接下來會傳給EPMC,然後結合環境感知信息(如地形高度圖、深度信息等),選擇適當的運動模式,形成一個類別分佈,同時選擇合適的離散潛在表示。
最後,PMC又把這種潛在表示與機器人當前的狀態(如關節位置、速度等)結合,得到電機控制信號,並最終交付執行。
訓練的順序則剛好與之相反——從PMC開始,到SEPMC結束。
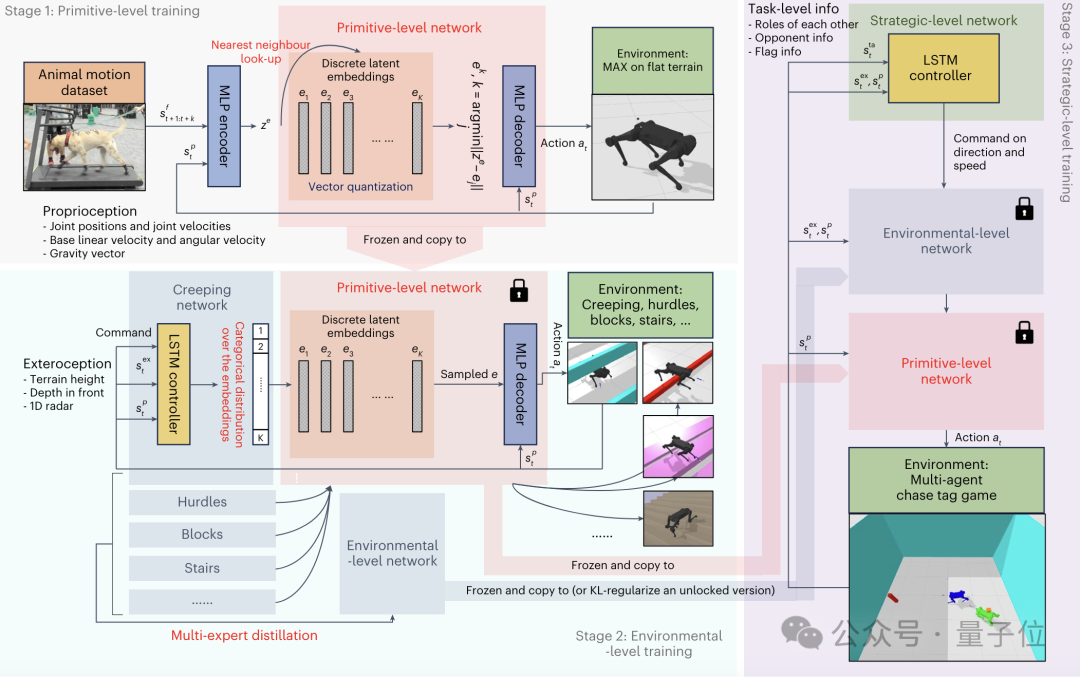
第一階段PMC的訓練,也就是原始級訓練,是為了建立基礎的運動能力。
該階段的訓練數據來自對一隻訓練有素的中型拉布拉多犬的運動捕捉。
通過指導狗狗完成各種動作,作者收集了大約半小時的不同步態(如行走、奔跑、跳躍、坐下等)的運動序列,以每秒120幀的頻率采樣。
狗狗在捕捉過程中遵循直線、方形、圓形等不同的路徑軌跡。此外,作者還專門收集了約9分鐘的上下樓梯的運動數據。
為了彌合動物和機器人的骨骼結構差異,作者使用逆運動學方法將狗狗的關節運動數據重定向到機器人關節。
通過進一步的人工調整,最終得到了與四足機器人兼容的參考運動數據。
 △資料圖,不代表訓練數據來源
△資料圖,不代表訓練數據來源基於這些數據,作者使用了生成式模型VQ-VAE編碼器來壓縮和表示動物的運動模式,構建了PMC的離散潛在空間。
通過向量量化技術,這些連續的潛在表示離散化為預定義的離散嵌入向量,解碼器則基於選定的離散嵌入和當前機器人狀態生成具體的運動控制信號。
在VQ-VAE的基礎上,PMC的訓練目標,是最小化生成的運動軌跡與參考軌跡之間的偏差。
同時,作者引入了優先級采樣機制,根據不同運動模式的難易程度動態調整其在訓練中的權重,確保網絡對所有參考數據都能很好地擬合。
通過不斷迭代和優化,PMC逐步學習到一組能夠有效表達複雜動物運動的離散表徵,直至收斂。
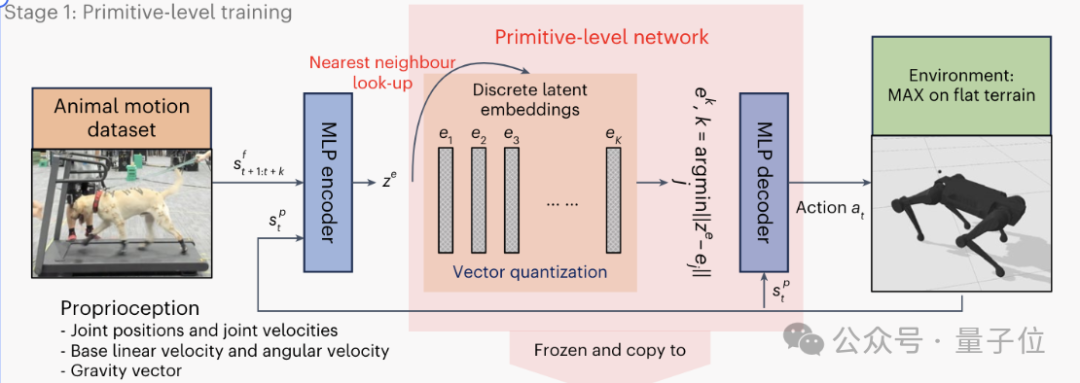
PMC階段的結果,為EPMC生成更高級別的運動控制信息提供了基礎。
EPMC在PMC的基礎上引入了環境感知模塊,接收來自視覺、雷達等傳感器的信息,使得策略網絡能夠根據當前環境狀態動態調整運動模式。
EPMC的核心是一個概率生成網絡,根據當前的感知信息和指令信號,在PMC提供的離散潛在空間上生成一個概率分佈。
這個分佈決定了應該激活哪些原始運動模式,以最好地適應當前環境和任務。
EPMC的訓練,通過最小化環境適應和任務完成的損失函數來實現,逐步學習優化運動策略,提高機器人的適應能力和魯棒性。
最後的SEPMC訓練階段進一步提升了機器人的認知和規劃能力,使其能夠在多智能體交互環境中製定和執行高層策略。
SEPMC在EPMC的基礎上,根據當前的遊戲狀態(如自身和對手位置等)和歷史交互記錄,生成高層的策略決策(如追逐、躲避)。
MAX機器人玩的追逐式定向越野遊戲,也正是SEPMC的訓練方式。
在該階段,作者採用了先進的多智能體強化學習算法PFSP,通過自我博弈不斷提升機器人的策略水平。
訓練過程中,當前策略不斷與歷史上的強對手進行對抗,迫使其學習更加魯棒和高效的策略。
得益於前兩個階段打下的堅實基礎,這種複雜策略的學習是非常高效的,即使在稀疏獎勵的情況下也能快速收斂。
值得一提的是,這樣的多智能體方案當中,還可以引入一些模擬人類的智能體,從而實現機器間或人機間的協作配合。
以上的訓練過程都是在仿真環境中完成,然後以零樣本遷移到真實環境。
在仿真中,物理參數可以自由控制,作者隨機化了大量物理參數(包括負載、地形變化等),通過強化學習得到的策略必須能夠應對這些變化,得到穩定和通用的控制能力。
另外,作者在控制框架中的每一層都使用了LSTM,使得各個層級都具備一定的時序記憶和規劃能力。
傳感器方面,目前作者主要驗證了使用Motion Capture系統,或僅基於Depth Camera的視覺感知可以完成一系列複雜的任務。
為了處理更加開放和複雜的環境,作者未來將進一步整合LiDAR、Audio等感知輸入,進行多模態理解,更好的應對環境。
論文地址:
https://www.nature.com/articles/s42256-024-00861-3
項目主頁:
https://tencent-roboticsx.github.io/lifelike-agility-and-play/