非Transformer架構站起來了!首個純無注意力大模型,超越開源巨頭Llama 3.1
機器之心報導
編輯:杜偉、陳陳
Mamba 架構的大模型又一次向 Transformer 發起了挑戰。
Mamba 架構模型這次終於要「站」起來了?自 2023 年 12 月首次推出以來,Mamba 便成為了 Transformer 的強有力競爭對手。
此後,採用 Mamba 架構的模型不斷出現,比如 Mistral 發佈的首個基於 Mamba 架構的開源大模型 Codestral 7B。
今天,艾巴紮比技術創新研究所(TII)發佈了一個新的開源 Mamba 模型 ——Falcon Mamba 7B。

先來總結一波 Falcon Mamba 7B 的亮點:無需增加內存存儲,就可以處理任意長度的序列,並且能夠在單個 24GB A10 GPU 上運行。
目前可以在 Hugging Face 上查看並使用 Falcon Mamba 7B,這個僅用因果解碼器的模型採用了新穎的 Mamba 狀態空間語言模型(State Space Language Model, SSLM)架構來處理各種文本生成任務。
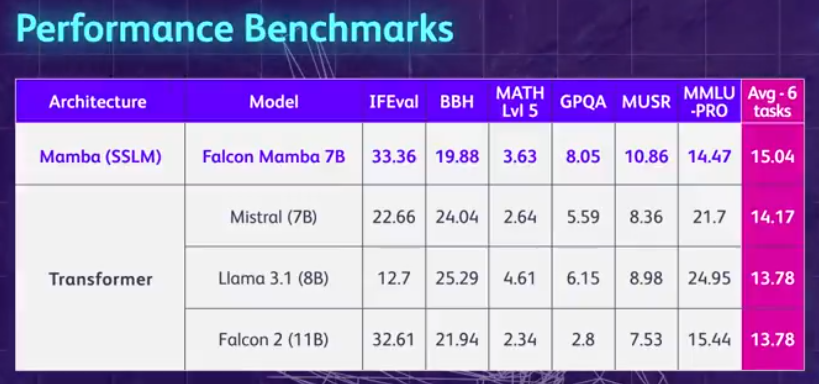
從結果來看,Falcon Mamba 7B 在一些基準上超越同尺寸級別的領先模型,包括 Meta 的 Llama 3 8B、Llama 3.1 8B 和 Mistral 7B。
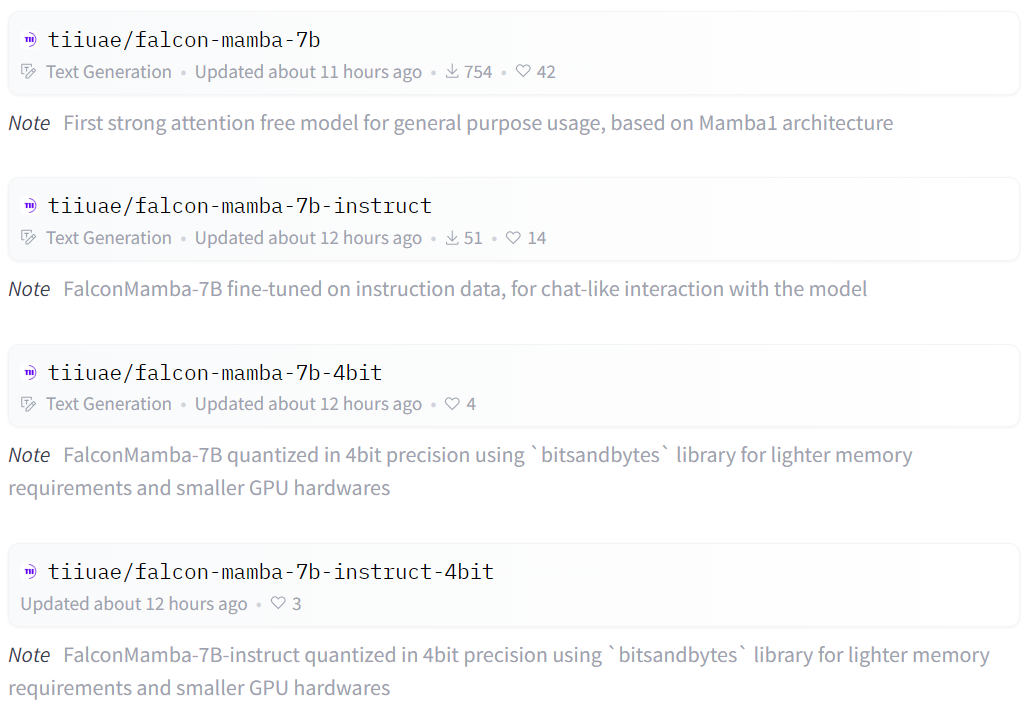
Falcon Mamba 7B 分為四個變體模型,分別是基礎版本、指令微調版本、4bit 版本和指令微調 4bit 版本。
作為一個開源模型, Falcon Mamba 7B 採用了基於 Apache 2.0 的許可證「Falcon License 2.0」,支持研究和應用目的。
Hugging Face 地址:https://huggingface.co/tiiuae/falcon-mamba-7b
Falcon Mamba 7B 也成為了繼 Falcon 180B、Falcon 40B 和 Falcon 2 之後,TII 開源的第四個模型,並且是首個 Mamba SSLM 架構模型。

首個通用的大型純 Mamba 模型
一直以來,基於 Transformer 的模型一直佔據著生成式 AI 的統治地位,然而,研究人員注意到,Transformer 架構在處理較長的文本信息時可能會遇到困難。
本質上,Transformer 中的注意力機制通過將每個單詞(或 token)與文本中的每個單詞進行比較來理解上下文,它需要更多的計算能力和內存需求來處理不斷增長的上下文窗口。
但是如果不相應地擴展計算資源,模型推理速度就會變慢,超過一定長度的文本就沒法處理了。為了克服這些障礙,狀態空間語言模型 (SSLM) 架構應運而生,該架構通過在處理單詞時不斷更新狀態來工作,已成為一種有前途的替代方案,包括 TII 在內的很多機構都在部署這種架構。
Falcon Mamba 7B 採用了卡內基梅隆大學和普林斯頓大學研究人員最初在 2023 年 12 月的一篇論文中提出的 Mamba SSM 架構。
該架構使用一種選擇機制,允許模型根據輸入動態調整其參數。這樣,模型可以關注或忽略特定輸入,類似於注意力機制在 Transformer 中的工作方式,同時提供處理長文本序列(例如整本書)的能力,而無需額外的內存或計算資源。
TII 指出,該方法使模型適用於企業級機器翻譯、文本摘要、計算機視覺和音頻處理任務以及估計和預測等任務。
訓練數據
Falcon Mamba 7B 訓練數據高達 5500GT ,主要由 RefinedWeb 數據集組成,並添加了來自公共源的高質量技術數據、代碼數據和數學數據。所有數據通過 Falcon-7B/11B 標記器進行 tokenized 操作。
與其他 Falcon 系列模型類似,Falcon Mamba 7B 採用多階段訓練策略進行訓練,上下文長度從 2048 增加到了 8192。此外,受到課程學習概念的啟發,TII 在整個訓練階段精心選擇了混合數據,充分考慮了數據的多樣性和複雜性。
在最後的訓練階段,TII 使用了一小部分高質量精選數據(即來自 Fineweb-edu 的樣本),以進一步提升性能。
訓練過程、超參數
Falcon Mamba 7B 的大部分訓練是在 256 個 H100 80GB GPU 上完成的,採用了 3D 並行(TP=1、PP=1、DP=256)與 ZeRO 相結合的策略。下圖為模型超參數細節,包括精度、優化器、最大學習率、權重衰減和 batch 大小。
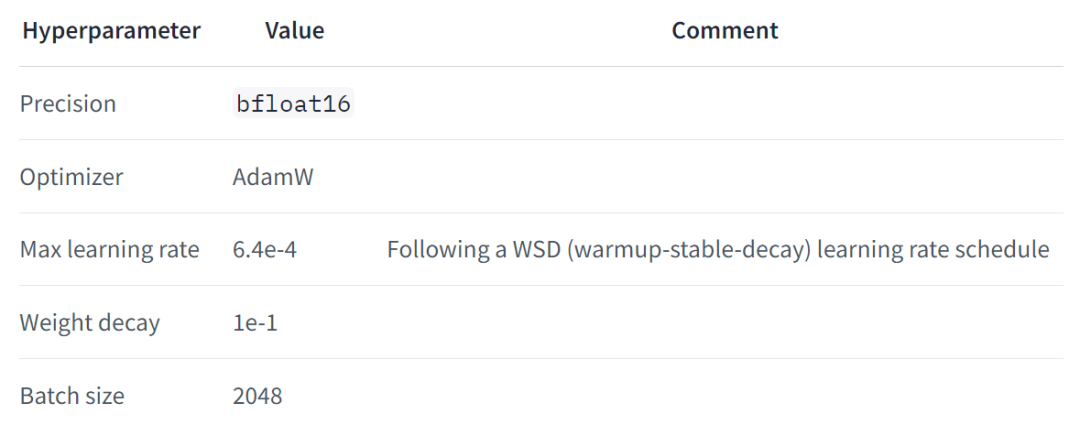
具體而言,Falcon Mamba 7B 經過了 AdamW 優化器、WSD(預熱 – 穩定 – 衰減)學習率計劃的訓練, 並且在前 50 GT 的訓練過程中,batch 大小從 b_min=128 增加到了 b_max=2048。
在穩定階段,TII 使用了最大學習率 η_max=6.4×10^−4,然後使用超過 500GT 的指數計劃將其衰減到最小值
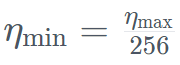
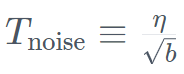
保持恒定。
。同時,TII 在加速階段採用了 BatchScaling 以重新調整學習率 η,使得 Adam 噪聲溫度
整個模型訓練花費了大約兩個月時間。
模型評估
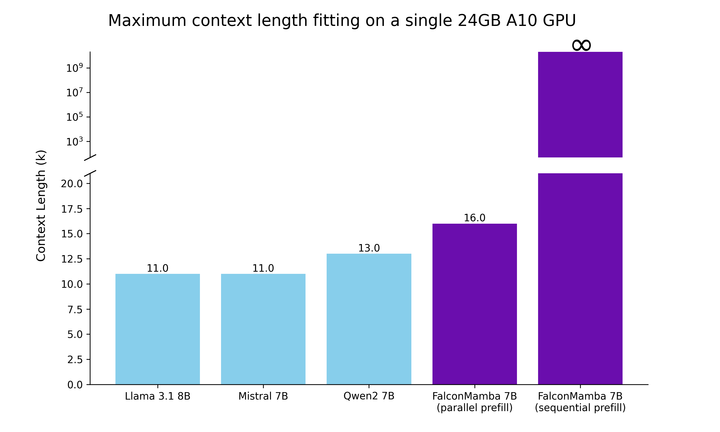
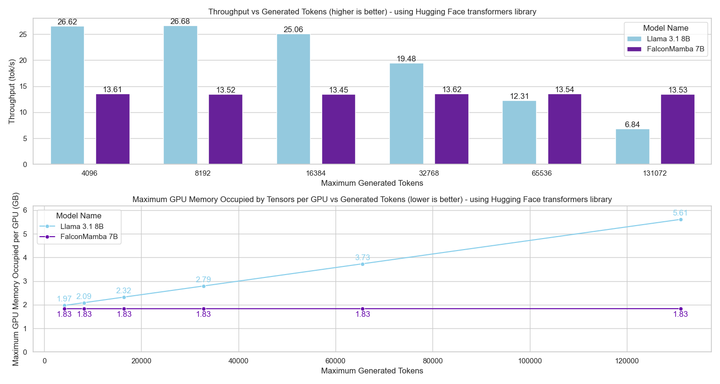
為了瞭解 Falcon Mamba 7B 與同尺寸級別領先的 Transformer 模型相比如何,該研究進行了一項測試,以確定使用單個 24GB A10GPU 時模型可以處理的最大上下文長度。
結果顯示,Falcon Mamba 能夠比當前的 Transformer 模型適應更大的序列,同時理論上能夠適應無限的上下文長度。
接下來,研究者使用批處理大小為 1 ,硬件採用 H100 GPU 的設置中測量模型生成吞吐量。結果如下圖所示,Falcon Mamba 以恒定的吞吐量生成所有 token,並且 CUDA 峰值內存沒有任何增加。對於 Transformer 模型,峰值內存會增加,生成速度會隨著生成的 token 數量的增加而減慢。
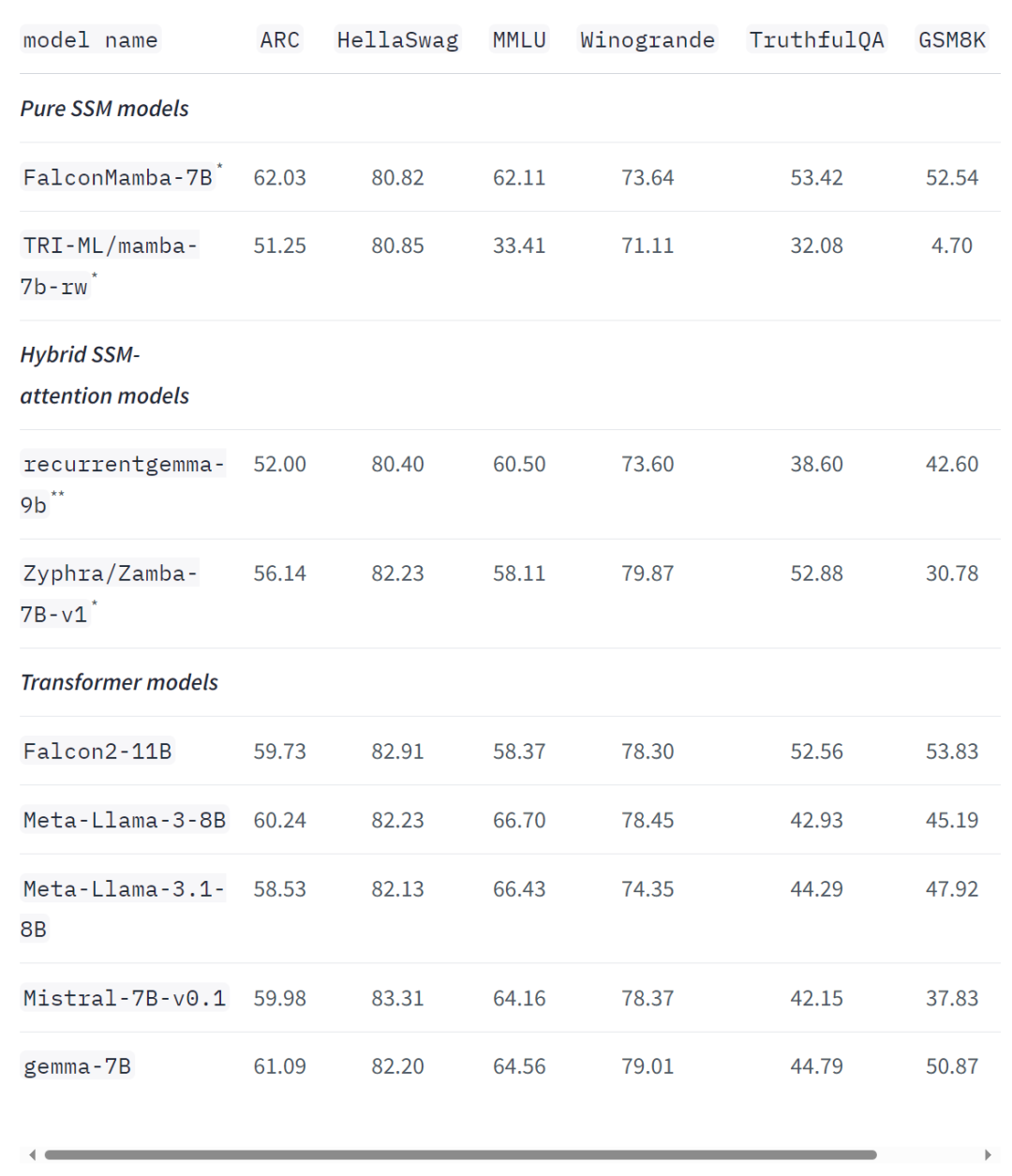
即使在標準的行業基準測試中,新模型的性能也優於或接近於流行的 transformer 模型以及純狀態空間模型和混合狀態空間模型。
例如,在 Arc、TruthfulQA 和 GSM8K 基準測試中,Falcon Mamba 7B 的得分分別為 62.03%,53.42% 和 52.54%,超過了 Llama 3 8 B, Llama 3.1 8B, Gemma 7B 和 Mistral 7B。然而,在 MMLU 和 Hellaswag 基準測試中,Falcon Mamba 7B 遠遠落後於這些模型。

TII 首席研究員 Hakim Hacid 在一份聲明中表示:Falcon Mamba 7B 的發佈代表著該機構向前邁出的重大一步,它激發了新的觀點,並進一步推動了對智能系統的探索。在 TII,他們正在突破 SSLM 和 transformer 模型的界限,以激發生成式 AI 的進一步創新。
目前,TII 的 Falcon 系列語言模型下載量已超過 4500 萬次 —— 成為阿聯酋最成功的 LLM 版本之一。
Falcon Mamba 7B 論文即將放出,大家可以等一等。
參考鏈接:
https://huggingface.co/blog/falconmamba
Falcon Mamba 7B’s powerful new AI architecture offers alternative to transformer models