換掉Transformer,7B開源模型立刻登頂!任意長序列都能處理
明敏 發自 凹非寺
量子位 | 公眾號 QbitAI
只是換掉Transformer架構,立馬性能全方位提升,問鼎同規模開源模型!
(注意力機制不存在了)
這就是最新Falcon Mamba 7B模型。

它採用Mamba狀態空間語言模型架構來處理各種文本生成任務。
通過取消傳統注意力機制,有效提升了模型處理長序列時計算效率低下的問題。
它可以處理無限長序列,但內存需求不增加。
無論上下文多長,生成每個token的時間基本一樣。
由此,Falcon Mamba模型性能全方位提升,打敗一眾Transformer架構模型,如Llama-3.1(8B)、Mistral(7B)以及Falcon-2(11B)。

如上成果由阿聯酋艾巴紮比技術創新研究所(TII)帶來,他們正是Falcon模型的開發團隊。
該系列共包含四個模型:基礎版本、指令微調版本、4bit版本和指令微調4bit版本。
最新模型遵循TII Falcon License 2.0開放協議,它在Apache 2.0協議下。
圍觀網民直呼:遊戲規則要改變了!

全球首個開源SSLM
在性能上,Falcon Mamba 7B全方位超越一眾開源模型。

Mamba是一種狀態空間模型(SSM,State Space Model)。它結合了RNN和CNN的特點,通過引入一種選擇機制,它允許模型根據當前的輸入有選擇地傳播或忘記信息,從而提高處理文本信息的效率。
同時,它設計了一種硬件感知的並行算法,以遞歸模式運行,避免了GPU內存層級之間IO訪問,提高計算效率。
最後它還簡化了架構,將SSM架構和Transformer中的MLP塊結合為單一的塊。
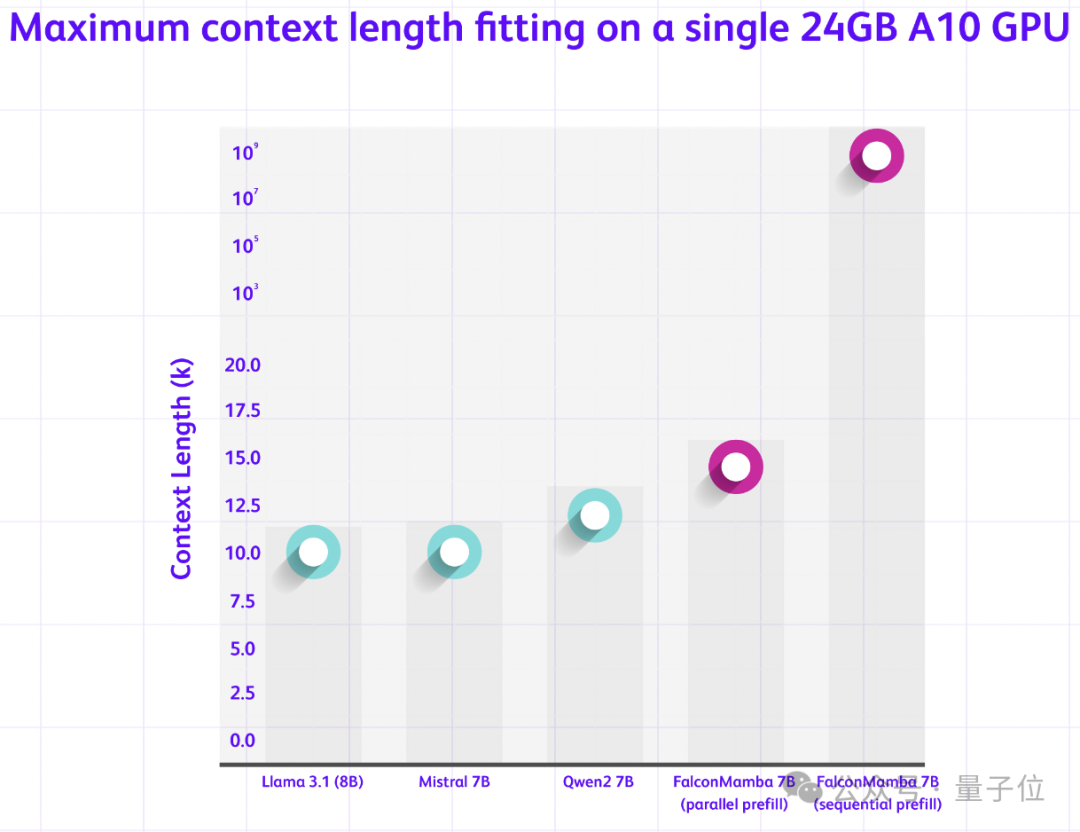
從Transformer換到Mamba,能夠讓Falcon模型可以處理任意長序列,但無需增加內存。尤其適合單個A10 24GB GPU。
研究還討論了兩種不同的處理序列方法。
並行預填充方法適用於GPU並行處理,對內存需求較高;順序填充方法適用於SSM模型,可以處理任意長度序列,從而不會受到內存限制。
為了確保大規模訓練穩定,Falcon Mamba模型使用了額外的RMS標準化層。
RMS標準化層能夠簡化LayerNorm的計算過程,可減少計算量。
模型使用了5500GT數據訓練,這些數據主要來自RefedWeb數據集以及公開數據。訓練過程基本勻速,在訓練後期增加了一小部分高質量策劃數據,這有助於模型在最後階段的優化。
在H100上,批大小為1、提示詞長度為1-130k生成token的測試中,Falcon Mamba能夠在生成新token時保持穩定的吞吐量,這意味著它的性能不受文本長度影響,可以穩定處理長序列,不會出現性能下降情況。


Falcon Mamba支持多種Hugging Face API,包括AutoModelForCausalLM、pipline。
還推出了一個指令調優版本,通過額外50億個token進行微調,可以讓模型準確性更高。
在Hugging Face、GitHub上都可訪問最新模型~
參考鏈接:
https://huggingface.co/blog/falconmamba#hardware-performance



















