Google DeepMind 展示 GenRM 技術:微調 LLMs 作為獎勵模型,提升生成式 AI 推理能力
IT之家 9 月 3 日消息,Google DeepMind 團隊於 8 月 27 日在 arxiv 上發表論文,介紹展示了 GenRM 生成式驗證器,創造性提出獎勵模型,從而提升生成式 AI 推理能力。
AI 行業內,目前提高大語言模型(LLMs)的主流做法就是 Best-of-N 模式,即由 LLM 生成的 N 個候選解決方案由驗證器進行排序,並選出最佳方案。
這種基於 LLM 的驗證器通常被訓練成判別分類器來為解決方案打分,但它們無法利用預訓練 LLMs 的文本生成能力。
DeepMind 團隊為了克服這個局限性,嘗試使用下一個 token 預測目標來訓練驗證器,同時進行驗證和解決方案生成。

DeepMind 團隊這種生成式驗證器(GenRM),相比較傳統驗證器,主要包含以下優點:
-
無縫集成指令調整
-
支持思維鏈推理
-
通過多數投票利用額外的推理時間計算
在算法和小學數學推理任務中使用基於 Gemma 的驗證器時,GenRM 的性能優於判別式驗證器和 LLM-as-a-Judge 驗證器,在使用 Best-of-N 解決問題的百分比上提高了 16-64%。

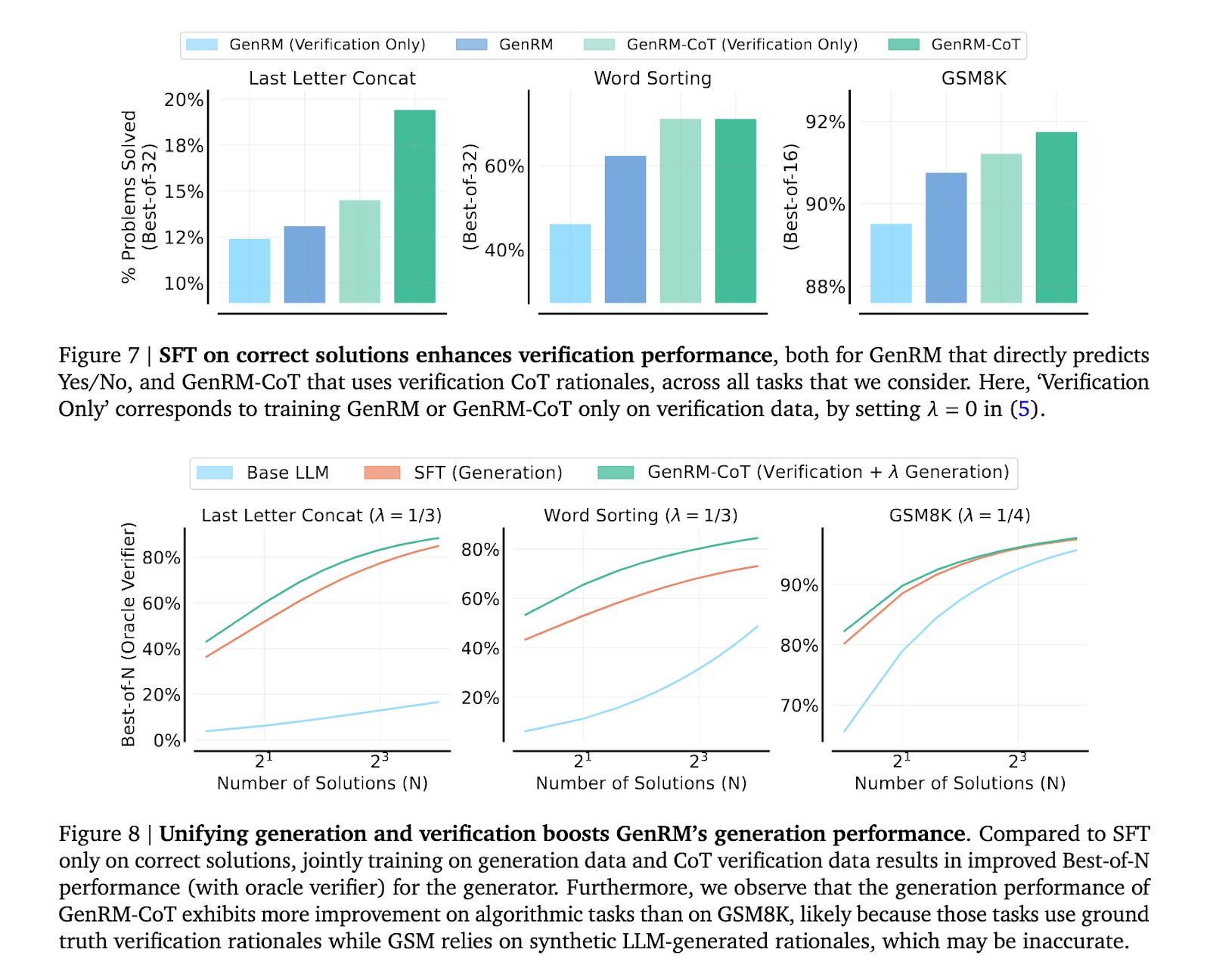
據 Google DeepMind 報導,GenRM 相對於分類獎勵模型的邊標誌著人工智能獎勵系統的關鍵演化,特別是在其容量方面,以防止新模型學成到的欺詐行為。這一進步突出表明,迫切需要完善獎勵模型,使人工智能輸出與社會責任標準保持一致。
IT之家附上參考地址



















