這就翻車了?Reflection 70B遭質疑基模為Llama 3,作者:重新訓練
機器之心報導
編輯:杜偉
最近,開源大模型社區再次「熱鬧」了起來,主角是 AI 寫作初創公司 HyperWrite 開發的新模型 Reflection 70B。
它的底層模型建立在 Meta Llama 3.1 70B Instruct 上,並使用原始的 Llama chat 格式,確保了與現有工具和 pipeline 的兼容性。
這個模型橫掃了 MMLU、MATH、IFEval、GSM8K,在每項基準測試上都超過了 GPT-4o,還擊敗了 405B 的 Llama 3.1。

憑藉如此驚豔的效果,Reflection 70B 被冠以開源大模型新王。該模型更是由兩位開發者(HyperWrite CEO Matt Shumer 和 Glaive AI 創始人 Sahil Chaudhary)花了 3 周完成,效率可謂驚人。
Reflection 70B 能不能經受住社區的考驗呢?今天 AI 模型獨立分析機構 Artificial Analysis 進行了獨立評估測試,結果有點出乎意料。
該機構表示,Reflection Llama 3.1 70B 的 MMLU 得分僅與 Llama 3 70B 相同,並且明顯低於 Llama 3.1 70B。
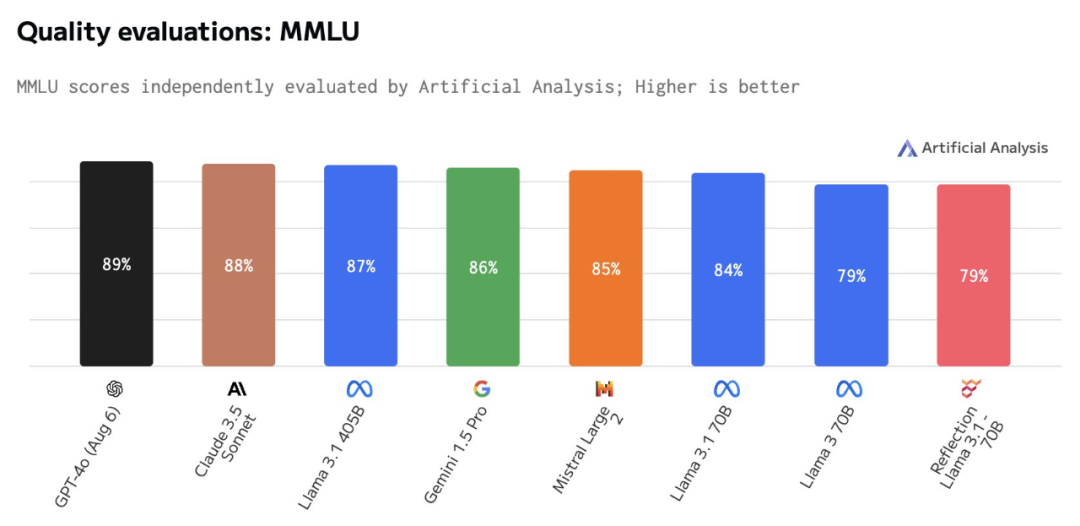
圖源:https://x.com/ArtificialAnlys/status/1832505338991395131
還有科學推理與知識(GPQA)和定量推理(MATH)基準測試的結果,同樣不如 Llama 3.1 70B。
 圖源:https://x.com/ArtificialAnlys/status/1832457791010959539
圖源:https://x.com/ArtificialAnlys/status/1832457791010959539此外,Reddit 上 LocalLLaMA 社區的一個帖子比較了 Reflection 70B 與Llama 3.1、Llama 3 權重的差異,結果顯示,Reflection 模型似乎是使用了經過 LoRA 調整的 Llama 3 而不是 Llama 3.1。


貼主還提供了以上模型權重比較結果的代碼來源。
from transformers import AutoModelForCausalLM, AutoTokenizerimport torchimport matplotlib.pyplot as pltimport seaborn as snsbase_model_name = "meta-llama/Meta-Llama-3-70B-Instruct"chat_model_name = "mattshumer/Reflection-Llama-3.1-70B"base_model = AutoModelForCausalLM.from_pretrained(base_model_name, torch_dtype=torch.bfloat16)chat_model = AutoModelForCausalLM.from_pretrained(chat_model_name, torch_dtype=torch.bfloat16)def calculate_weight_diff(base_weight, chat_weight):return torch.abs(base_weight - chat_weight).mean().item()def calculate_layer_diffs(base_model, chat_model):layer_diffs = []for base_layer, chat_layer in zip(base_model.model.layers, chat_model.model.layers):layer_diff = {'input_layernorm': calculate_weight_diff(base_layer.input_layernorm.weight, chat_layer.input_layernorm.weight),# 'mlp_down_proj': calculate_weight_diff(base_layer.mlp.down_proj.weight, chat_layer.mlp.down_proj.weight),# 'mlp_gate_proj': calculate_weight_diff(base_layer.mlp.gate_proj.weight, chat_layer.mlp.gate_proj.weight),# 'mlp_up_proj': calculate_weight_diff(base_layer.mlp.up_proj.weight, chat_layer.mlp.up_proj.weight),'post_attention_layernorm': calculate_weight_diff(base_layer.post_attention_layernorm.weight, chat_layer.post_attention_layernorm.weight),'self_attn_q_proj': calculate_weight_diff(base_layer.self_attn.q_proj.weight, chat_layer.self_attn.q_proj.weight),'self_attn_k_proj': calculate_weight_diff(base_layer.self_attn.k_proj.weight, chat_layer.self_attn.k_proj.weight),'self_attn_v_proj': calculate_weight_diff(base_layer.self_attn.v_proj.weight, chat_layer.self_attn.v_proj.weight),'self_attn_o_proj': calculate_weight_diff(base_layer.self_attn.o_proj.weight, chat_layer.self_attn.o_proj.weight)}layer_diffs.append(layer_diff)return layer_diffsdef visualize_layer_diffs(layer_diffs):num_layers = len(layer_diffs)num_components = len(layer_diffs[0])fig, axs = plt.subplots(1, num_components, figsize=(24, 8))fig.suptitle(f"{base_model_name} <> {chat_model_name}", fontsize=16)for i, component in enumerate(layer_diffs[0].keys()):component_diffs = [[layer_diff[component]] for layer_diff in layer_diffs]sns.heatmap(component_diffs, annot=True, fmt=".6f", cmap="YlGnBu", ax=axs[i], cbar_kws={"shrink": 0.8})axs[i].set_title(component)axs[i].set_xlabel("Layer")axs[i].set_ylabel("Difference")axs[i].set_xticks([])axs[i].set_yticks(range(num_layers))axs[i].set_yticklabels(range(num_layers))axs[i].invert_yaxis()plt.tight_layout()plt.show()layer_diffs = calculate_layer_diffs(base_model, chat_model)visualize_layer_diffs(layer_diffs)
還有人貼出了 Matt Shumer 在 Hugging Face 對 Reflection 70B 配置文件名稱的更改,可以看到從 Llama 3 70B Instruct 到 Llama 3.1 70B Instruct 的變化。

這樣的事實擺在眼前,似乎讓人不得不信。各路網民也開始發聲附和,有人表示自己從一開始就懷疑它是 Llama 3,當用德語問模型一些事情時,它卻用英語回答。這種行為對於 Llama 3 非常常見。

還有人奇怪為什麼 Reflection 70B 模型一開始就得到了如此多的炒作和關注,畢竟第一個談論它是「頂級開源模型」的人是開發者本人(Matt)。而且更確切地說,模型是微調的。

更有人開始質疑開發者(Matt),認為他只是這家公司(GlaiveAI)的利益相關者,試圖通過炒作來增加價值,實際上卻對這項技術一無所知。

在被質疑 Reflection 70B 的基礎模型可能是 Llama 3 而非 Llama 3.1 70B 時,Matt Shumer 坐不住了,現身進行了澄清,並表示是 Hugging Face 權重出現了問題。

就在幾個小時前,Matt Shumer 稱已經重新上傳了權重,但仍然存在問題。同時他們開始重新訓練模型並上傳,從而消除任何可能出現的問題,應該很快就會完成。

當被問到為何需要重新訓練時,Matt Shumer 表示本不需要這樣做,但已經嘗試了所有方法。無論做什麼,Hugging Face 上 Reflection 70B 模型都會出現問題,導致離預期中的性能差得遠。

當然 Matt Shumer 還面臨更多質疑,比如對 GlaiveAI 的投資情況、為什麼 Hugging Face 上的基礎模型為 Llama 3 而不是 Llama 3.1 以及基準中有關 LORAing 的問題。

Matt Shumer 一一進行瞭解釋。(以下標引用)
1. 我是一個超級小的投資者(1000 美元),只是一次支持性的投資,因為我認為 Sahil Chaudhary 很棒。
2. 至於為什麼基礎模型是 Llama 3,我們不知道。這就是為什麼我們從頭開始再訓練,應該很快完成。
3. 那些嘗試了 Playground 並擁有早期訪問權限的用戶獲得了與託管 API 截然不同的體驗,我們需要弄清楚這一點。
4. 不確定什麼是 LORAing,但我們檢查了汙染,將在下週與 405B(或更早)一起發佈數據集,到時候可以查看。
至於重新訓練後的 Reflection 70B 表現如何?我們拭目以待。
參考鏈接:
Reflection-Llama-3.1-70B is actually Llama-3.
byu/realmaywell inLocalLLaMA