小模型越級挑戰14倍參數大模型,Google開啟Test-Time端新的Scaling Law
西風 發自 凹非寺
量子位 | 公眾號 QbitAI
不必增加模型參數,計算資源相同,小模型性能超過比它大14倍的模型!
GoogleDeepMind最新研究引發熱議,甚至有人表示這可能就是OpenAI即將發佈的新模型草莓所用的方法。

研究團隊探究了在大模型推理時進行計算優化的方法,根據給定的prompt難度,動態地分配測試時(Test-Time)的計算資源。
結果發現這種方法在一些情況下比單純擴展模型參數更經濟有效。

換句話說,在預訓練階段花費更少的計算資源,而在推理階段花費更多,這種策略可能更好。

推理時用額外計算來改進輸出
這項研究的核心問題是——
在一定計算預算內解決prompt問題,不同的計算策略對於不同問題的有效性有顯著差異。我們應如何評估並選擇最適合當前問題的測試時計算策略?這種策略與僅僅使用一個更大的預訓練模型相比,效果如何?

DeepMind研究團隊探究了兩種主要機制來擴展測試時的計算。
一種是針對基於過程的密集驗證器獎勵模型(PRM)進行搜索。
PRM可以在模型生成答案過程中的每個步驟都提供評分,用於引導搜索算法,動態調整搜索策略,通過在生成過程中識別錯誤或低效的路徑,幫助避免在這些路徑上浪費計算資源。
另一種方法是在測試時根據prompt自適應地更新模型的響應分佈。
模型不是一次性生成最終答案,而是逐步修改和改進它之前生成的答案,按順序進行修訂。
以下是並行采樣與順序修訂的比較。並行采樣獨立生成N個答案,而順序修訂則是每個答案依賴於前一次生成的結果,逐步修訂。

通過對這兩種策略的研究,團隊發現不同方法的有效性高度依賴於prompt的難度。

由此,團隊提出了「計算最優」擴展策略,根據prompt難度自適應地分配測試時的計算資源。
他們將問題分為五個難度等級並為每個等級選擇最佳策略。
如下圖左側,可以看到,在修訂場景中,標準的best-of-N方法(生成多個答案後,從中選出最優的一個)與計算最優擴展相比,它們之間的差距逐漸擴大,使得計算最優擴展在使用少4倍的測試計算資源的情況下,能夠超越best-of-N方法。
同樣在PRM搜索環境中,計算最優擴展在初期相比best-of-N有顯著的提升,甚至在一些情況下,以少4倍的計算資源接近或超過best-of-N的表現。
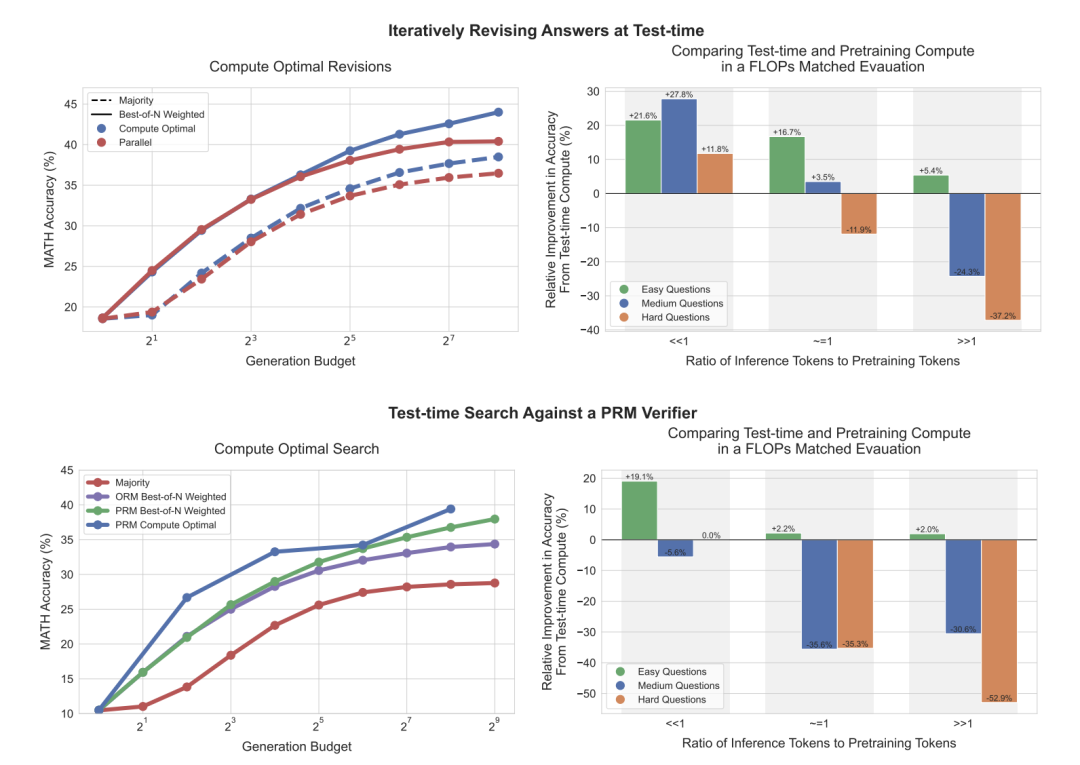
上圖右側比較了在測試階段進行計算最優擴展的PaLM 2-S模型與不使用額外測試計算的預訓練模型之間的表現,後者是一個*大14倍的預訓練模型。
研究人員考慮了在兩種模型中都預期會有𝑋 tokens的預訓練和𝑌 tokens的推理。可以看到,在修訂場景中(右上),當𝑌 << 𝑋時,測試階段的計算通常優於額外的預訓練。
然而,隨著推理與預訓練token比率的增加,在簡單問題上測試階段計算仍然是首選。而在較難的問題上,預訓練在這些情況下更為優越,研究人員在PRM搜索場景中也觀察到了類似的趨勢。
研究還比較了測試時計算與增加預訓練的效果,在計算量匹配的情況下,對簡單和中等難度的問題,額外的測試時計算通常優於增加預訓練。
而對於難度較大的問題,增加預訓練計算更為有效。

總的來說,研究揭示了當前的測試時計算擴展方法可能無法完全替代預訓練的擴展,但已顯示出在某些情況下的優勢。
引發網民熱議
這項研究被網民po出來後,引發熱議。
有網民甚至表示這解釋了OpenAI「草莓」模型的推理方法。

為什麼這麼說?
原來就在昨晚半夜,外媒The Information放出消息,爆料OpenAI新模型草莓計劃未來兩週內發佈,推理能力大幅提高,用戶輸入無需額外的提示詞。
草莓沒有一味追求Scaling Law,與其它模型的最大區別就是會在回答前進行「思考」。
所以草莓響應需要10-20秒。

這位網民猜測,草莓可能就是用了類似GoogleDeepMind這項研究的方法(doge):
如果你不認同,給個替代推理方法解釋!

解釋就解釋:
本文探討了 best-of-n 采樣和蒙地卡羅樹搜索(MCTS)。
草莓可能是一種具有特殊tokens(例如回溯、規劃等)的混合深度模型。它可能會通過人類數據標註員和來自容易驗證領域(如數學/編程)的強化學習進行訓練。

 論文鏈接:https://arxiv.org/pdf/2408.03314
論文鏈接:https://arxiv.org/pdf/2408.03314參考鏈接:
[1]https://x.com/deedydas/status/1833539735853449360
[2]https://x.com/rohanpaul_ai/status/1833648489898594815