實測OpenAI新模型o1 :做題王者,實戰青銅
今天淩晨,OpenAI發佈了o1系列模型,最大的特點是擅長推理。
模型的能力,一代比一代強,我們的測評,一次比一次難做。測評變成一件「畢恭畢敬」的事情,生怕提不出好問題(難不倒它),在讓它推理之前,我們自己的腦子就快燒沒了。
最重要的原因是:我們想知道,被寄予厚望的新一代模型,有沒有應用到實際生活中的推理能力?以及要如何測出這樣的能力?
秉承著這個想法,我們設計了一套考驗o1-preview綜合能力的「考卷」。
省流版結論如下:它擅長做題、搞研究,更像一個適合待在實驗室的高材生,你現在還不能指望它成為生活里的助手。
熱身:數學與邏輯能力強,速度還不慢
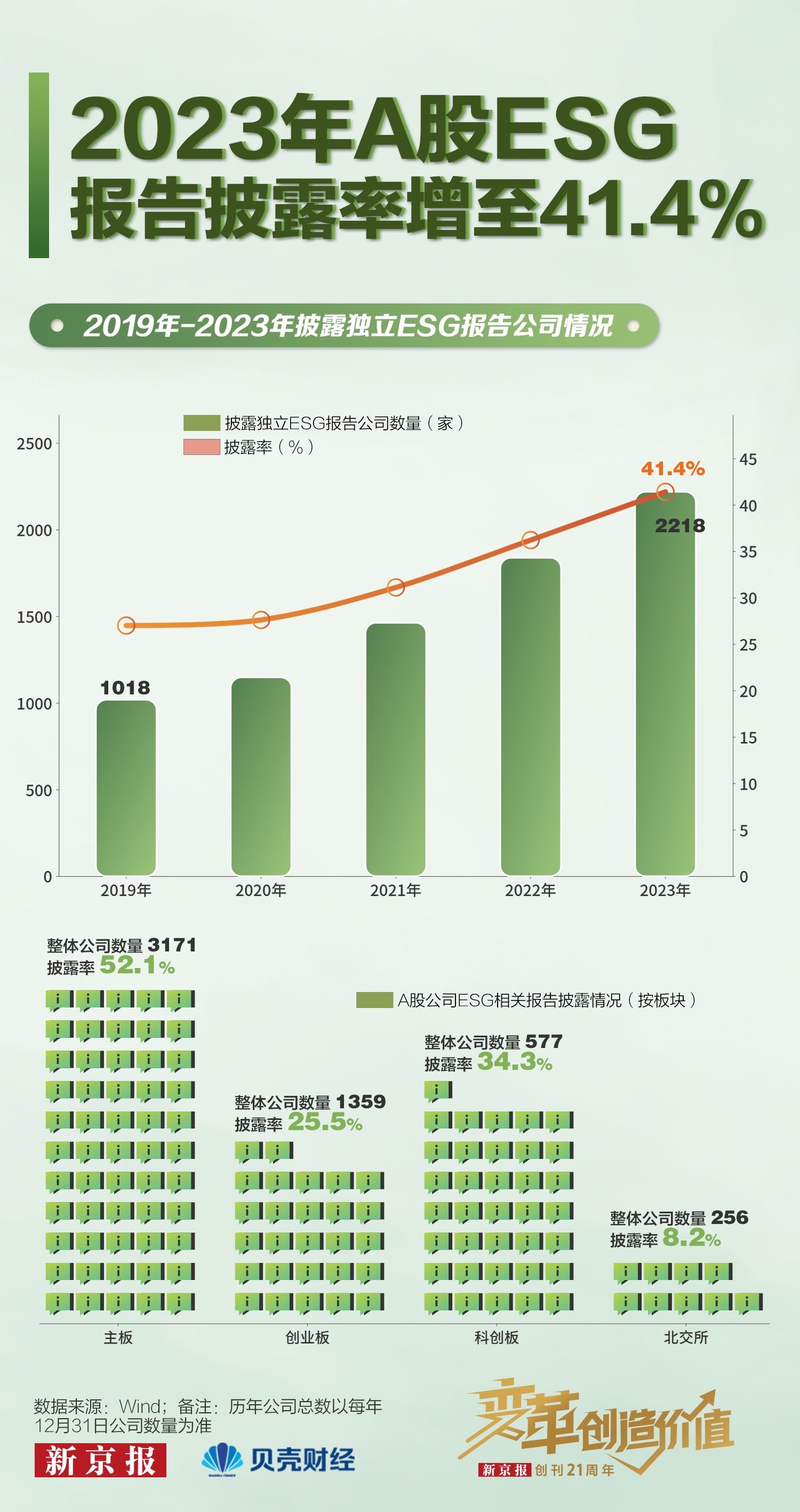
發佈會的數據大家看了很多,尤其是新一代o1在各項任務上的評分,都有超乎以往的表現。比如OpenAI的官方文檔里,特別提到在AIME數學競賽的考試中,o1都能取得不錯的表現。
快速查了一下,這個AIME比賽,考題長這樣:

原題黏貼過去,看看究竟是怎麼個超強表現。o1-preview反應很迅速,上手就開始解題了。

對比一下官方答案,完全正確。反應時間也比預計的快,只是思考過程並不是預設展開。
所以除非手動下拉,否則從用戶的觀感上看,它就是自己捲成一團在跑計算,這是在交互設計上可以提升的地方。
不過,對比AIME官方解答,o1-preview的回答比較冗長——指望靠GPT開掛的中學生朋友,可別照抄,要自己思考呀。
邏輯推理題方面,我們沿用了一些「過往真題」:
愛麗絲有4個兄弟,她還有1個姐妹。愛麗絲的兄弟有多少個姐妹?
你可能會奇怪,這不是很簡單嗎——答案是2,加上愛麗絲自己。
不出意外,o1-preview很快答對了,甚至沒告訴我思考多久,快到有種「就這?幾秒」的感覺。

不過,今年6月,開源AI研究機構LAION發現,GPT-3.5/4、Claude、Gemini、Llama、Mistral都沒能答對這類題目,某種程度上連小學生的推理能力都不如。
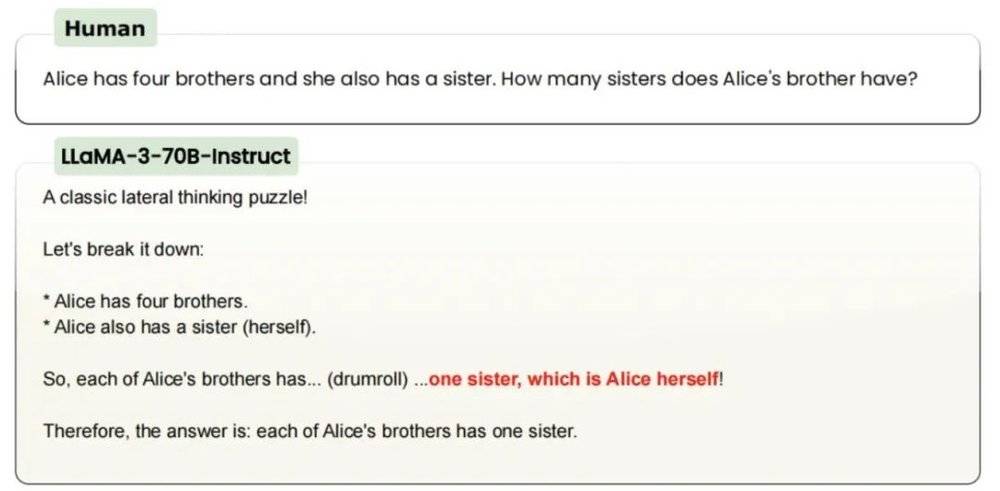
直到現在,GPT-4o也還是答錯了。

可以說,o1-preview的推理能力的確提高了。
進階考驗:情景推理慢於GPT-4o,但更準確
接著是測試LLM模型的經典必考:海龜湯問題。
一名男人發現自己少貼了一張郵票,隨後便去世了。請問發生了什麼事?
海龜湯是一種推理遊戲,出題人給出簡短、模糊的故事背景,由玩家自己主動提問。出題人只會回答「是」和「不是」,然後玩家根據出題人的回答,結合自己的推導,給出故事的真相。
我給了o1-preview五次提問的機會,然後讓o1-preview嘗試推理真相。每一次提問,o1-preview都考慮了十幾秒,層層遞進。

但沒想到,才問了3個問題,o1-preview就迫不及待地給出推理了。

不得不說,非常接近真相。
這道題的標準答案是,男人寄送計時炸彈給仇人,但因為少貼了郵票,炸彈又被退回,結果一爆炸,炸死了自己。
o1-preview的方向是對的,稍微缺乏了一些準確和完整,少了一些細節,但很接近正確答案。非要挑刺的話,可能是沒有遵循我的提示詞指令提問五次。
不過,和AI玩推理遊戲很有意思,可惜目前新模型的額度有限,o1-preview每週可以發30條,o1-mini每週是50條,為了避免浪費寶貴的提問次數,下面的又一道海龜湯題目,我要求o1-preview一次性提8個問題,然後根據我的回答直接給出答案。
這次它的表現相當令人驚訝:o1-preview只思考了10秒,提出的問題全部直擊要害,真相呼之慾出。

比較搞笑的地方是,大家可以點開看看o1-preview這短短的十秒里都想了什麼——我的同事忍不住「抽水」:這AI戲也太多了吧。

等我一次性回答「是」和「不是」後,o1-preview又花了13秒給出答案,基本就是標準答案。

以後再玩這種推理遊戲,要嚴防死守有人掏出手機,用AI作弊。
相同的問題給到GPT-4o,長處是一如既往,夠快,幾乎是實時的,但思維更跳脫。

答案嘛,稍微有偏離,而且看上去對自己的答案不是很自信的樣子。
壓軸大題:自作主張教人剁手,上得廳堂下不了廚房
普通用戶最關心的,肯定不是新模型的「卷面能力」,誰閑著沒事情會突發奇想,打開手機算個雞兔同籠啊?
比「卷面能力」更有用的,是處理生活實際問題,而且不是應用題,是正經八百生活中會碰到的計算問題。
眼下,多地都在派發電子消費補貼,國家對各類消費電子產品,最高可以補貼2000元。

官方發佈很簡單,但實際用起來就不是了。只能以舊換新?有什麼地址限制?哪裡領券?有沒有最低消費?
來,讓o1-preview過來幫我算一下,到底可以薅到多少羊毛。
比較遺憾的是,o1-preview的知識庫截止到去年十月,對新政策沒辦法實時反應。
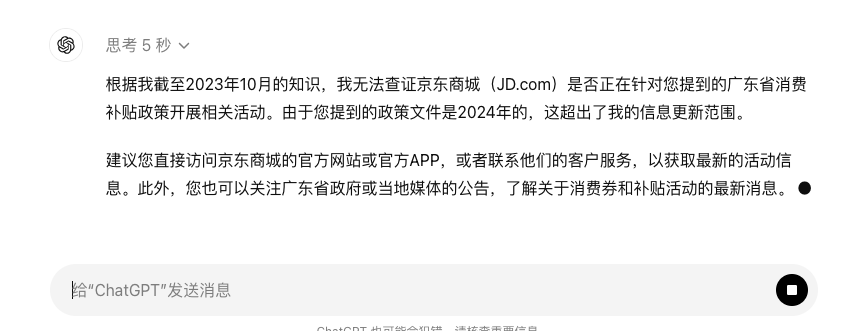
行吧,那就先手動錄入一下,在輸入廣東省官方給的細節之後,它反應速度非常快,直接「自作主張」地把各種常見優惠都算進去了。

但都是「假設」,做不得數。在蒐集了一些實際優惠政策之後,我們手動錄入prompt:
我需要買一台新電腦,現在有一萬左右的預算,想買一台最新款的MacBook Air。現在京東有優惠活動。條件如下:
1. 政府補貼,按照標價減免20%,2000元封頂
2. 蘋果自己有滿7000減1400元的優惠
3. 蘋果電腦可以以舊換新,但需要根據舊機品相定價。詳細的品相信息已經列在下面

因為不能瀏覽網頁,它自己設定價格為9499元,但不一定反映出實際上電商的掛牌價。
另外則是舊機價格的判斷,京東給出的報價是3300元。
 京東估價
京東估價同樣的舊機,多跑幾次提示詞,每次o1-preview都會給不同的報價,僅供參考,其中3400元是和京東報價最接近的一次。
 o1-preview估價
o1-preview估價更關鍵的是,這些寫在提示詞里的信息都要我們自己去找和整理,AI沒能節省多少時間。
買東西時算優惠價,就是日常生活里最實際的數學場景了,誰能忘記被雙十一支配的恐懼。
而且算優惠的難點在於更廣泛的推理:單純的加減,犯不著找一個AI來做,電商平台自己會幫用戶算好,購物車里一勾就是了。
真正燒腦的,就是「規劃」一個最優惠的路線,這涉及很多問題:同一時期哪家電商在做優惠?用戶是否具備參與優惠活動的資格?外部補貼的能否作用在這家電商?例如這次的國家補貼,是要看用戶領取資格的,在京東用了就不能在天貓用。
甚至,一些線下店也參與補貼活動,但是前提是在線上領取之後去線下使用。
說實話,這種繁瑣場景特別需要一個助理,需要的是一個腦筋靈活的真·智能助手,而不是一個僵板的做題家。
「考試」總結:做題雖好,仍要走入現實
不管是我們自己做的測評,還是許多網民都已經有的測評,甚至包括官方的演示文檔,都有非常強烈的「做題」感。
做數學題、做閱讀理解題、做填空題。
這世界還是變成了大家想要的樣子:新的模型降臨人間,第一件事是做題。
做題當然是很好的摸底模型能力的方式,然而做題的毛病也非常明顯:很真空,不知道這麼強的做題能力,到底有什麼用。
甚至在自媒體賽博禪心的技術面測評中,API端口的表現也不太令人滿意,進一步限制了實際應用。他認為這次更新,比較像是工程上的優化,而非底層能力的迭代。
像極了專四專六級考高分,出國卻依然寸步難行、開不了口的我(不是)。

老實說,這是一個用戶預期的問題,切記:OpenAI眼中的推理,並不只是計算能力。
計算的確是「推理」里重要的一部分,但不是全部,尤其是當談到真正介入實際應用的推理能力,計算就僅僅是非常小的一部分。
這也是為什麼在這次的官方文檔里,有一個小節在解釋「思維鏈」:通過模擬人類的思維過程,幫助模型逐步分解複雜問題。
這項能力的提升,在o1-preview應對數學和推理題的過程中,都得到了體現。
只是,要說它能全面模仿人類的思維過程,暫時還稱不上:人類不僅會拆分步驟來思考,更會綜合性、全局性地來思考。
走向AGI的道路,已有曙光,但仍然漫長。
本文來自微信公眾號:APPSO (ID:appsolution),作者:APPSO