南加大提出全新「通用時間序列」基礎模型TimeDiT,基於擴散模型創新物理約束機制
通過結合去噪擴散模型和Transformer架構,TimeDiT可以有效處理時間序列的多通道、多解像度和缺失值問題,並能整合物理知識,提高時間序列分析的準確性和適用性。
隨著近年來在文本和影片數據上構建基礎模型的進展,學術界對時間序列的基礎模型也表現出濃厚的興趣。
時間序列分析在許多關鍵領域中具有重要性,能夠影響從科學研究到經濟決策的廣泛應用。
例如,在自然科學中,氣候數據的分析直接關係到全球變暖的預測和資源管理;在社會科學中,時間序列數據有助於理解社會行為的演變;在醫療健康領域,病人的生命體徵和治療進程記錄依賴於時間序列分析。隨著全球可持續發展目標的推進,能源和環境監控等領域的時間序列數據也越來越受到重視。
然而,儘管已經有許多模型專門針對特定的時間序列任務取得了顯著的成果,現有的模型仍面臨諸多挑戰。
首先,現實世界中的時間序列數據往往含有缺失值,並且來自不同領域的數據通常具有多通道和多解像度的特性。這些問題使得現有模型在處理數據不完整性和複雜性時表現不佳,難以有效地進行預測、補全和異常檢測。
此外,現有模型在整合物理知識方面存在明顯局限。許多真實的時間序列數據背後遵循著嚴格的物理定律,例如偏微分方程(PDEs),這些定律能夠為數據建模提供重要的先驗知識。
然而,已有的時間序列基礎模型難以將這些物理知識直接融入預測或數據生成過程,從而限制了其在科學和工程等物理領域中的適用性。
為了應對這些挑戰,南加州大學的研究人員提出了一種通用的時間序列基礎模型TimeDiT:通過結合去噪擴散模型和Transformer架構,TimeDiT能夠處理數據中的多通道、多解像度和缺失值等問題,同時通過創新的物理約束機制,TimeDiT能將物理知識無縫整合到時間序列生成和預測過程中。
 論文鏈接:https://arxiv.org/pdf/2409.02322
論文鏈接:https://arxiv.org/pdf/2409.02322這種靈活性不僅提高了模型應對複雜時間序列任務的能力,還使其能夠在需要嚴格物理約束的領域(如氣候建模和工程模擬)中表現出色。
背景與挑戰
時間序列數據與文本和圖像等數據有著根本的區別,因此直接將大型語言模型(如GPT-4、LLaMA等)的成功經驗移植到時間序列領域並不現實。
時間序列數據的特殊性質使得該領域面臨一系列獨特的挑戰,例如:
1. 通道維度不一致:在不同領域中,時間序列可能會有不同數量的通道。而這一現像在文本和圖像數據上並不常見。這對通用模型設計提出了更高的要求,要求一個模型能夠靈活處理不同通道數的多變量數據。
2. 缺失值問題:在實際應用中,時間序列數據往往存在大量缺失值,如何在這些不完整數據上實現有效的預測和補全是另一個難題。
3. 多解像度問題:同一時間序列數據的不同維度采樣頻率可能各不相同,這種多解像度特性增加了模型在處理時的複雜度。
4. 自回歸生成方式的局限性:傳統的時間序列模型通常採用自回歸生成方式,即使是基於Transformer架構的模型亦然。這意味著數據是按順序生成的,這種方式在整合外部知識(如以偏微分方程形式表達的物理定律)時存在局限性。
模型創新
為瞭解決這些問題,本文提出了一種全新的時間序列基礎模型——TimeDiT,即時間擴散Transformer模型。該模型結合了Transformer架構和去噪擴散模型,既能捕捉時間序列中的長短期依賴,又能生成高質量的時間序列樣本,與此同時又克服了傳統自回歸模型在生成過程中容易累積誤差的問題。
TimeDiT模型通過以下幾個方面的創新來應對時間序列數據的挑戰:
擴散模型的引入
傳統時間序列模型通常採用自回歸生成方式,即逐步生成序列的未來值,這種方式的局限性在於其對模型的依賴較大,容易導致預測誤差的累積。部分已有的工作通過獨立預測不同時間窗口的結果來規避這一問題。然而這又使得模型一定程度上喪失了捕捉相鄰時間信號間的依賴關係的能力。而擴散模型則採用了一個去噪的逆向過程,從噪聲逐步生成數據,這種方法避免了自回歸生成方式中常見的誤差累積問題,又使得模型能夠在每一步的去噪過程中根據附近時間片的預測值修正自身。
通道對齊策略
為了應對不同領域中通道數量的變化,TimeDiT模型設計了一個通道對齊策略,使得模型能夠靈活處理不同輸入數據的維度變化。
綜合掩碼機制
TimeDiT模型使用了一種新穎的掩碼機制,通過不同的掩碼方案來處理多解像度、缺失值等問題,確保模型能夠在各種數據條件下保持穩定的性能。這種掩碼機制包括隨機掩碼(random position mask)、分段掩碼(stride mask)、步幅掩碼(block mask)等,能夠適應不同的時間序列任務。
無微調模型編輯策略
TimeDiT模型還提出了一種創新的無須微調的模型編輯策略,允許在采樣過程中無縫整合外部知識(如物理定律),而不需要更新模型的參數。這種策略使得TimeDiT模型能夠根據偏微分方程(PDEs)等領域知識,在生成數據的過程中顯式約束生成的樣本,使其符合已知的物理規律。
模型架構與實現
TimeDiT模型的架構設計圍繞擴散過程展開,擴散過程可以看作是一個馬高夫鏈,在前向過程中逐步向數據中加入高斯噪聲,最終破壞數據的原始結構。然後,模型在逆向過程中通過逐步去噪的方式重建原始數據。
TimeDiT的Transformer架構通過注意力機制來捕捉時間序列中的時間依賴關係,同時依靠擴散模型生成高質量的樣本。在采樣階段,TimeDiT模型還設計了一種基於物理知識的能量先驗,通過偏微分方程(PDEs)來約束模型生成的時間序列樣本,使其符合物理定律。
模型的標準化訓練流程通過掩碼機制實現,能夠同時處理預測、數據補全、異常檢測等任務。在訓練階段,TimeDiT模型通過重建被掩蓋的時間序列片段來進行自監督學習。在推理階段,模型根據具體任務選擇不同的掩碼策略,以便更好地適應下遊任務的需求。
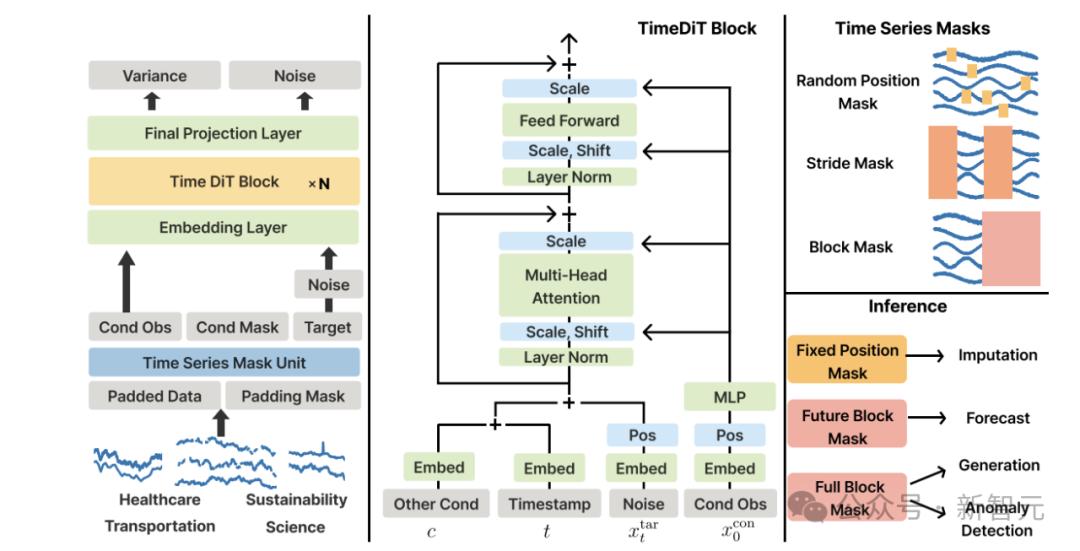
圖1 TimeDiT架構。左圖:TimeDiT框架包含來自不同領域的多解像度、多變量時間序列數據,並能夠利用掩碼策略處理缺失值問題;中間:TimeDiT模塊的結構;右上方:由時間序列掩碼單元生成的掩碼的示意圖;右下方:TimeDiT在推理過程中處理下遊任務時使用的掩碼
此外,在TimeDiT架構中,物理知識的整合是一大亮點,特別是在生成高質量時間序列數據時,物理信息通過物理約束的擴散過程得到體現。通過引入偏微分方程(PDEs)作為物理先驗,TimeDiT在推理階段可以顯式的將物理定律融入擴散生成過程,確保生成的時間序列符合真實世界的物理規律。
具體而言,TimeDiT使用能量函數來量化生成數據與物理模型之間的偏差,通過優化該能量函數,使生成的數據更加符合物理約束。這一過程通過朗之萬動力學進行采樣調整,結合物理先驗和數據驅動模型,從而在生成過程中迭代優化,使生成的樣本不僅符合數據分佈,還滿足物理定律。算法1中詳細提供了偽代碼
這種物理引導的擴散策略顯著提升了TimeDiT在科學和工程領域中的應用潛力,尤其是在氣候與海洋學等複雜物理現象的建模中,展現了較強的泛化能力和適用性。
 算法1 TimeDiT中基於物理知識的采樣過程
算法1 TimeDiT中基於物理知識的采樣過程實驗驗證與結果分析
為了驗證TimeDiT模型的有效性,本文進行了大量的實驗。在TimeDiT模型的實驗結果中,針對缺失值(missing value)和多解像度數據(multi-resolution)的處理表現尤為突出(見圖2)。傳統的時間序列模型在應對這些複雜的現實問題時往往表現不佳,而TimeDiT通過其創新性的掩碼機制,展現了卓越的適應能力。
對於含有缺失值的預測任務,TimeDiT在不同缺失率條件下的表現優於現有的最先進模型。當缺失率從5%增加至50%時,TimeDiT依然保持較低的CRPSsum分數,顯示出其對缺失數據的強大魯棒性。與其他模型相比,隨著缺失率的增加,TimeDiT的性能優勢愈加明顯,表明其在面對更具挑戰性的缺失數據條件下依然能夠有效補全缺失值。
在處理多解像度時間序列數據時,TimeDiT同樣表現優異。實驗結果表明,隨著數據的采樣解像度從2種增加至6種,TimeDiT在處理多解像度數據時依然能維持明顯的性能優勢,充分說明其能夠有效整合不同采樣頻率的數據,進行高質量的預測。
這些實驗結果表明,TimeDiT不僅在理想化數據集上表現出色,更能應對現實中常見的複雜問題,如缺失數據和多解像度采樣,這使其在實際應用中的潛力大大提升。

圖2 針對含有缺失值和多解像度數據的實驗。從實驗結果中,我們可以看出TimeDiT表現出色,顯著優於其他模型。並且缺失值的比重越大、解像度的種類越多,TimeDiT的優勢越明顯
此外,TimeDiT模型在物理約束下的時間序列生成實驗也取得了優異的表現。通過引入偏微分方程(PDEs)作為能量先驗,TimeDiT模型能夠生成符合物理規律的高質量樣本,在多個物理領域的數據集上均超越了現有的基線模型(見圖3)。
除了以上的實驗結果,本文也在常用的基準數據(benchmark data)上對TimeDiT與其他先進的時間序列模型進行了對比實驗,包括預測、數據補全、異常檢測等任務。實驗數據來自交通、電力、金融等領域,涵蓋了多種具有挑戰性的時間序列任務。
在這些實驗中,TimeDiT模型在多個任務上都取得了最先進的結果,表現出極高的泛化能力和適應性。
1. 預測任務:在時間序列的概率預測任務中(圖4),TimeDiT模型在電力和交通數據集上實現了新的最優CRPSsum評分,表明其在處理複雜多變量時間序列數據上的出色性能。
2. 數據補全任務:對於缺失值補全任務(圖5),TimeDiT模型的創新掩碼機制使得它能夠有效應對缺失率較高的數據集,實驗結果顯示,TimeDiT在多個數據集上均實現了最優的均方誤差(MSE)和平均絕對誤差(MAE)。
3. 異常檢測任務:TimeDiT模型還在工業監控數據的異常檢測任務中(圖6)表現突出,通過頻譜殘差預處理方法,有效避免了模型對異常數據點的過擬合。
 圖3 基於物理知識的時間序列生成任務
圖3 基於物理知識的時間序列生成任務 圖4 時間序列預測任務
圖4 時間序列預測任務 圖5:時間序列補全任務
圖5:時間序列補全任務 圖6 時間序列異常檢測任務
圖6 時間序列異常檢測任務模型優勢與局限
TimeDiT模型的主要優勢在於其靈活性和廣泛的適應性。它不僅能夠處理各種具有不同分佈的時間序列數據,還能夠通過無微調的模型編輯策略整合外部知識,如物理規律等,使其在科學和工程領域的應用具有巨大的潛力。
實驗結果表明,TimeDiT模型在處理預測、補全、異常檢測等任務時,都表現出了強大的性能和魯棒性。
然而,TimeDiT模型也有一定的局限性。首先,本文主要在常見的序列長度上進行實驗,尚未深入研究該模型在處理超長時間序列時的表現。
其次,雖然模型能夠通過掩碼機制處理多通道和多解像度問題,但在高維多變量時間序列上的擴展性仍有待進一步提高。
此外,儘管模型能夠整合物理知識,但不同類型外部信息對模型性能的具體影響還需要進一步的研究。
未來工作展望
未來的工作可以從以下幾個方向進一步提升TimeDiT模型的能力:
1. 擴展性增強:進一步提升模型的擴展性,處理更高維度和更加複雜的時間序列數據,尤其是在應對實際應用中的超長序列時的表現。
2. 多模態數據融合:研究如何無縫整合多模態數據源,如文本、圖像等信息,以提升模型在多任務場景下的表現。
3. 超長時間序列處理:探索如何提高模型處理超長時間序列的能力,以滿足諸如氣候變化、金融市場等領域的需求。
結論
TimeDiT模型通過創新性地結合擴散模型與Transformer架構,為時間序列分析領域提供了一種通用的基礎模型。它不僅能夠有效應對真實世界中常見的多解像度、缺失值等問題,還能在采樣過程中整合物理學知識,使生成的時間序列符合已知的物理規律。
實驗結果表明,TimeDiT在多個時間序列任務上取得了最先進的結果,展示了其在廣泛應用場景中的潛力。未來的研究可以進一步提升模型的擴展性和多模態融合能力,使其能夠在更多的實際應用中發揮作用。
參考資料:
https://arxiv.org/pdf/2409.02322
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。



















