AI探索宇宙結構新突破,超精準場級模擬,半秒完成冷暗物質仿真
【導讀】AI開啟模擬宇宙!近日,來自馬基斯·普朗克研究所等機構,利用宇宙學和紅移依賴性對宇宙結構形成進行了場級仿真,LeCun也在第一時間轉發和推薦。
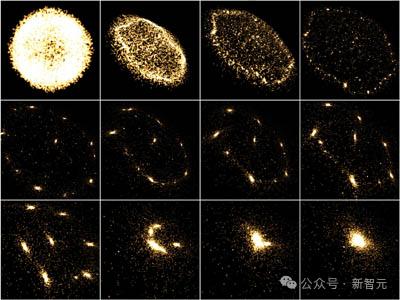
下面的兩組動圖展示了計算機對於宇宙形成的模擬:

其中一行是根據物理定律計算的,而另一行是由人工智能學習後生成的。
你能看出來哪一個結果出自AI之手嗎?
這就是來自馬基斯·普朗克研究所等機構發表的工作:利用宇宙學和紅移依賴性對宇宙結構形成進行場級仿真。
AI終於開始模擬宇宙了!LeCun也在第一時間轉發和推薦:

作者表示:我們現在可以使用人工智能在多個時間步上對大多數宇宙學特性生成宇宙的冷暗物質模擬。
並且,物理學是這個神經網絡設計的核心,它可以看成是PINN(內嵌物理知識神經網絡)的一種實現,其損失函數建模了時間相關的粒子坐標和速度之間的特定關係。

在這項工作中,研究人員提出了一個用於大規模結構的場級模擬器,捕獲宇宙學依賴性和宇宙結構形成的時間演化。
模擬器將線性位移場映射到特定紅移處對應的非線性位移。
模擬器是一個神經網絡,包含對Ω和紅移z處的線性增長因子D(z)的依賴性進行編碼的樣式參數。

研究人員在六維N-body相空間上訓練模型,將粒子速度預測為模型位移輸出的時間導數,顯著提高了訓練效率和模型準確性。
最終,模擬器在測試數據(訓練期間未見過的各種宇宙學和紅移)上實現了良好的精度和性能,在z = 0,k ∼ 1 Mpc/h的尺度上達到了百分比級精度,並在較高紅移下提高了性能。
通過合併樹將預測的結構形成歷史與N體模擬進行比較,可以找到一致的合併事件序列和統計特性。
並且,該模擬器速度極快,在單個GPU上半秒內就能夠預測128的立方個粒子的非線性位移和速度場。
同時又可以通過多GPU並行處理進行良好的擴展,支持任意大尺寸的實現。
模擬宇宙的AI
隨著宇宙學數據分析推向更小的尺度,利用高階統計數據,並實現場級分析和基於模擬的推理方案,為預測非線性宇宙結構形成提供了更準確的方法。——當然也對算力提出了超高要求。

比如利用N點統計的傳統分析方法,需要大量模擬數據集來進行準確的協方差估計。
而基於模擬的推理方法和場級分析,則需要生成許多後期密度場的準確實現,以約束模型參數和初始條件重建。

DESI、Euclid、Vera C. Rubin天文台、SPHEREx和Subaru Prime Focus Spectrograph可以為研究者提供大量最新的星系巡天數據。
為了探明宇宙學參數和初始條件的最佳約束,需要對巡天觀測值進行快速、高度準確的預測。

在這項工作中,作者通過添加紅移依賴性和對多個紅移模擬快照的訓練來擴展場級N體模擬器。
由於本模型的時間依賴性和自可微性,研究者可以有效地獲得N體粒子速度作為輸出粒子位移的時間導數。
可以在訓練期間動態評估這些速度,由此定義一個取決於粒子位置和速度的損失函數,在六維N體相空間上進行訓練。
強製執行「速度必須等於位移時間導數」的物理約束,可以提高訓練效率並提高模型的準確性,特別是對於速度場。
模型結構
作者通過週期模擬框中的坐標x來描述N體粒子。每個粒子都與規則立方晶格上的一個位點q相關聯,因此它在紅移z處的位置定義為:

這裏Ψ是位移場,q是粒子的拉格朗日坐標。在線性Zeldovich近似 (ZA) 中,位移場演變為:

其中 D(z) 是線性增長因子,zi是早期選擇的紅移,以便線性理論可以很好地描述位移場。
隨著引力簇的非線性在後期變得重要,這種線性近似變得不準確,而模擬宇宙結構形成的非微擾方法(如N體模擬)變得必要:

這裏f(z)為線性增長率,H(z) 是哈勃率(Hubble rate),使用粒子速度來模擬星系探測中的紅移空間扭曲。
研究人員設計了場級模擬器,根據目標紅移處的ZA位移場來預測z = 3-0範圍內任何紅移處的非線性粒子位移和速度。
場級模擬器採用U-Net/V-Net設計,使用PyTorch的map2map庫實現和訓練模型。

如上圖所示,模型的輸入具有三個通道,對應於所需紅移處ZA位移的笛卡爾份量,排列在3D網格中。
輸入經過四個ResNet 3×3×3卷積,第一個卷積運算將3個輸入通道轉換為64個內部通道。
在四次卷積操作之後,結果的副本被存儲以供網絡的上采樣端使用,然後使用2×2×2卷積核對結果進行下采樣。
該架構的感受野對應於給定焦點單元兩側的48個網格點。預測單個粒子的位移時,以焦點粒子為中心的大小為97的區域需要通過網絡,對應於拉格朗日體積189.45 Mpc/h。
不過,由於網絡缺少填充區域中所有單元的信息,因此這些區域的粒子位移並不準確,需要從輸出中移除。
網絡有限的感受野也有一個優點:它在線性理論準確的大尺度上保留了ZA場。

以上的操作可以針對固定宇宙學的單個紅移來訓練來自模擬快照的數據。
為了擴展網絡功能,允許網絡學習N體映射作為Ω和紅移的函數,作者對其進行了增強以包含樣式參數 。
在執行任何卷積(包括下采樣/上采樣操作)之前,快照的Ω和D(z)值將傳遞並映射到與卷積核尺寸匹配的內部數組,然後使用這些參數調節網絡權重。
模型訓練
訓練數據
研究人員從一組具有不同宇宙學參數和一組固定快照紅移的模擬中隨機采樣快照,同時訓練樣式參數和網絡參數,使用Quijote Latin超立方體模擬,在邊長1 Gpc/h的空間中使用512個粒子運行。
所有這些模擬的拉格朗日空間解像度均為1.95 Mpc/h,整個數據集包含2000個模擬,每個模擬都有一組獨特的五個ΛCDM宇宙學參數Ω。
研究人員將2000個模擬分為三組:1874個用於訓練,122個用於驗證,4個用於測試。為了鼓勵各向同性,這裏使用數據增強,通過立方體的對稱性隨機變換輸入和目標數據。
損失函數
模型訓練使用的損失函數包含四個項。第一個是粒子位移的平均平方誤差(MSE),比較粒子的模擬器位移預測和真實的N體位移:

第二項是歐拉密度的MSE:
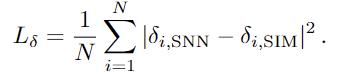
第三項是採用粒子速度的MSE:

最後一項對應於歐拉動量場的MSE損失。這裏將粒子速度分佈到與初始拉格朗日網格具有相同解像度的歐拉矢量場網格並計算,p是網格單元中每粒子質量的歐拉動量。

於是,紅移z處快照的最終損失函數為:

實驗結果
研究人員通過構建模擬器輸出和N體模擬真值的歐拉密度、和動量自功率譜和互功率譜來評估模擬器的準確性。
對於密度場,使用CIC插值方案將粒子分佈到512網格並估計功率譜,下表列出了用於測試本文模擬器的五個模擬宇宙學參數:

模擬器在訓練過程中從未遇到過以上5種測試模擬中的任何一種。
下面測試在訓練數據中的五個固定紅移之間進行插值時的模型性能:

上圖顯示了SNN模擬器的功率譜誤差(比例函數),每條曲線的顏色表示紅移。
歐拉密度誤差僅源於粒子位移的誤差,當紅移z = 0時,新的瞬態模型的隨機性與原始模型的隨機性相當,並且傳遞函數誤差通常比原始模型有所改善。
在上圖的最右列中,可以看到由於模擬器無法完美預測BAO幅度而導致的振盪誤差。不過模擬器的這些錯誤特徵低於1%,並且可能會隨著更多的訓練數據而得到改善。
紅移相關模型的性能與z = 0時的真實空間密度統計數據相當,並且在較高紅移時對於紅移空間和真實空間統計數據的性能明顯更好。
隨著紅移的減小,誤差平滑且單調地增加。這表明模擬器可以在其訓練數據中的少量固定紅移快照之間有效地進行插值,而不會過度擬合,否則我們會在中間看到錯誤的振盪特徵。
參考資料:
https://x.com/cosmo_shirley/status/1825749316134158627
本文來自微信公眾號「新智元」,編輯:alan ,36氪經授權發佈。



















