開源版GPT-4o來了,AI大神Karpathy盛讚,67頁技術報告全公開
兩個多月前那個對標GPT-4o的端到端語音模型,終於開源了。大神Karpathy體驗之後表示:nice!
前段時間技驚四座、劍指GPT-4o的實時語音模型Moshi,終於開源了!
自然聊天,情緒豐富,隨意打斷,拒絕呆板和回合製!
大神Karpathy體驗之後也表示:nice~

來自法國的初創團隊Kyutai,於7月初發佈了這個對標GPT-4o的神奇的端到端語音模型。
2個多月後的今天,他們兌現了自己的承諾,將代碼、模型權重和一份超長的技術報告一股腦開源。

論文地址:https://kyutai.org/Moshi.pdf
開源代碼:https://github.com/kyutai-labs/moshi
開放權重:https://huggingface.co/collections/kyutai
在海的那一邊,GPT-4o的語音模式還沒有完全端上來,這邊的模型已經免費送了。
大家可以去官網(moshi.chat)在線免費體驗,相比於平時你問我答的AI語音助手,這種「像人一樣」的聊天方式還是很奇特的。
整個模型的參數量為7.69B,pytorch平台上只有bf16版本,如果在本地跑的話對顯存有一定要求,而candle上提供了8bit版本,mlx上更是有4bit版本可供使用。
 moshiko和moshika表示男聲和女聲兩個版本
moshiko和moshika表示男聲和女聲兩個版本moshi作為一個全雙工口語對話框架,由幾部分組成:首先是Mimi,目前最先進的流式神經音頻編解碼器,能夠以完全流式的方式(延遲80毫秒)處理24 kHz音頻(12.5 Hz表示,帶寬1.1 kbps)。

然後是負責知識儲備、理解和輸出的Transformer部分,包括Helium Temporal Transformer和Depth Transformer。
其中小型的深度Transformer負責對給定時間步長的碼本間依賴性進行建模,而大型(7B參數)時間Transformer對時間依賴性進行建模。
作者還提出了「內心獨白」:在訓練和推理過程中,對文本和音頻進行聯合建模。這使得模型能夠充分利用文本模態傳遞的知識,同時保留語音的能力。
Moshi模擬兩種音頻流:一種來自Moshi自身(模型的輸出),另一種來自用戶(音頻輸入)。

沿著這兩個音頻流,Moshi預測與自己的語音(內心獨白)相對應的文本,極大地提高了生成的質量。
Moshi的理論延遲為160毫秒(Mimi幀大小80毫秒 + 聲學延遲80毫秒),在L4 GPU上的實際總延遲僅有200毫秒。
技術細節
Moshi突破了傳統AI對話模型的限制:延遲、文本信息瓶頸和基於回合的建模。
Moshi使用較小的音頻語言模型增強了文本LLM主幹,模型接收並預測離散的音頻單元,通過理解輸入並直接在音頻域中生成輸出來消除文本的信息瓶頸,同時又可以受益於底層文本LLM的知識和推理能力。
Moshi擴展了之前關於音頻語言模型的工作,引入了第一個多流音頻語言模型,將輸入和輸出音頻流聯合顯式處理為兩個自回歸token流,完全消除了說話者轉向的概念,從而允許在任意動態(重疊和中斷)的自然對話上訓練模型。

Helium
首先介紹負責文本部分的Helium,這裏採用了一些比較通用的設計。
比如,在注意力層、前饋層和輸出線性層的輸入處使用RMS歸一化;使用旋轉位置嵌入(RoPE)、4,096 個token的上下文長度和 FlashAttention來進行高效訓練;使用門控線性單元,SiLU作為門控函數。
Helium的分詞器基於SentencePiece的一元模型,包含32,000個主要針對英語的元素。
作者將所有數字拆分為單個數字,並使用字節退避來確保分詞器不會丟失信息。使用AdamW優化器訓練模型,先採用固定學習率,然後進行餘弦學習率衰減。
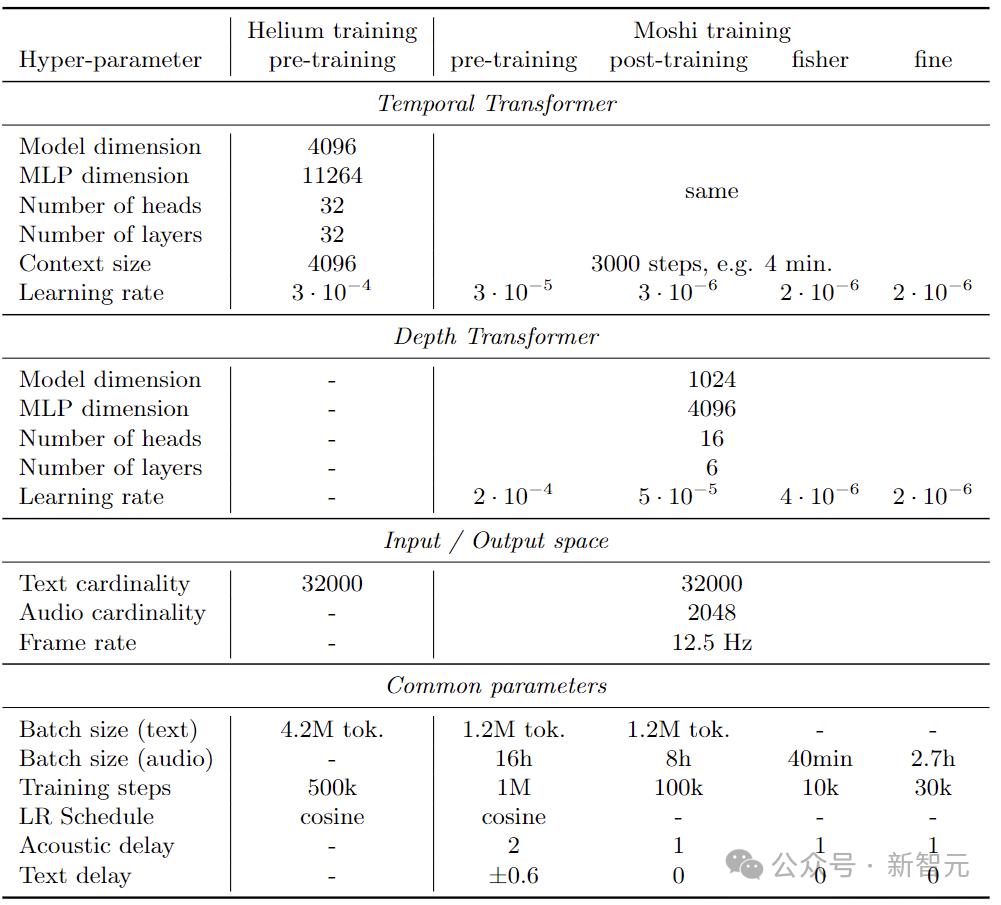
 7B Helium語言模型和Moshi架構訓練的超參數
7B Helium語言模型和Moshi架構訓練的超參數研究人員在公共英語數據的2.1T token上對模型進行了預訓練。
訓練數據包括域奇百科、Stack Exchange和大量科學文章,還依賴網絡爬取(特別是來自CommonCrawl的數據)來擴展數據集,並通過重覆數據刪除、語言識別和質量過濾等操作獲得高質量的訓練集。
Mimi
Mimi使用殘差矢量量化 (RVQ) 將音頻轉換為Moshi預測的離散token,並通過蒸餾將非因果的高級語義信息傳輸到因果模型生成的token中,從而允許對語義進行流式編碼和解碼。

Mimi架構的靈感來自SoundStream和Encodec,編碼器通過級聯殘差卷積塊將單通道波形投射到潛在表示。所有卷積都是因果的,因此該自動編碼器可以以流方式運行。
通過4個步幅為(4、5、6、8)的卷積塊 ,以及步幅為2的1D卷積,Mimi的編碼器將24kHz波形投影為每秒12.5幀、維度為512的潛在表示,而解碼器採用轉置卷積將潛在表示投射回24kHz音頻。
為了提高Mimi將語音編碼為緊湊表示的能力,研究人員在模型中添加了Transformer模塊,分別位於量化之前和之後。
每個Transformer塊包含8層、8個頭、使用RoPE位置編碼、250幀(20 秒)的有限上下文、模型維度512、MLP維度2048。使用 LayerScale來保證穩定訓練,對角線值初始化為0.01。兩個Transformer都使用因果屏蔽,保留了整個架構與流式推理的兼容性。
Moshi
Moshi作為一種用於音頻語言建模的新架構,將Helium與較小的Transformer模型相結合,以分層和流式傳輸的方式預測音頻token。
這種無條件音頻語言模型,提供了優於非流模型的清晰度和音頻質量,同時以流方式生成音頻。作者進一步擴展了這種架構,以並行模擬多個音頻流,從而可以在概念上和實踐上簡單地處理具有任意動態的全雙工對話。

在上圖的整體架構中,RQ Transformer將長度為K·S的扁平序列分解為大型時間Transformer的S個時間步長,生成上下文嵌入,用於在K個步驟上調節較小的深度Transformer。
與使用單個模型對展平序列進行建模相比,這允許通過增加S來縮放到更長的序列,或者通過增加K來縮放到更高的深度。
架構中的深度Transformer有6層,維度為1024,16個注意力頭。與之前的工作不同,作者在深度Transformer中為線性層、投影層和全連接層使用每個索引的不同參數。

事實上,不同的子序列可能需要不同的轉換。鑒於該Transformer的尺寸較小,這對訓練和推理時間都沒有影響,但上表結果顯示這種深度參數化是有益的。
內心獨白
內心獨白是一種用於音頻語言模型訓練和推理的新方法,它通過在音頻token之前預測時間對齊的文本token,顯著提高了生成語音的事實性和語言質量。
Moshi允許推理來自用戶音頻和Moshi音頻的非語言信息,但這與Moshi在其語音輸出中生成文本並不矛盾。根據過去的觀察,從粗到細的生成(從語義到聲學token)對於生成一致的語音至關重要。

作者利用這種層次結構,使用文本token作為語義token的每個時間步前綴。實驗表明,這不僅極大地提高了生成語音的長度和質量,還展示了單個延遲超參數如何允許從ASR模型切換到湯臣S模型,而不會改變損失、架構或訓練數據。
參考資料:
https://x.com/kyutai_labs/status/1836427396959932492
本文來自微信公眾號「新智元」,作者:alan,36氪經授權發佈。



















