Meta首款多模態Llama 3.2開源,1B羊駝寶寶,跑在手機上了
Meta首個理解圖文的多模態Llama 3.2來了!這次,除了11B和90B兩個基礎版本,Meta還推出了僅有1B和3B輕量級版本,適配了Arm處理器,手機、AR眼鏡邊緣設備皆可用。
Llama 3.1超大杯405B剛過去兩個月,全新升級後的Llama 3.2來了!
這次,最大的亮點在於,Llama 3.2成為羊駝家族中,首個支持多模態能力的模型。
Connect大會上,新出爐的Llama 3.2包含了小型(11B)和中型(90B)兩種版本的主要視覺模型。
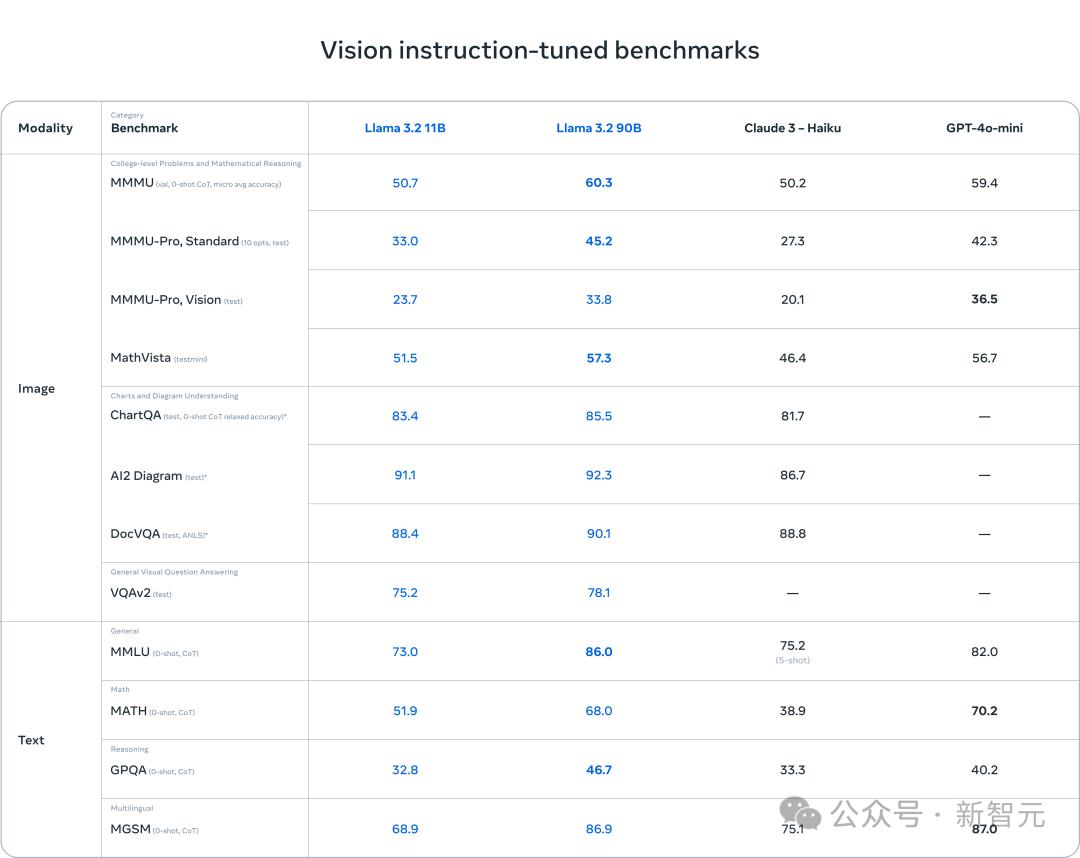
正如Meta所說,這兩款模型能夠直接替代,相對應的文本模型,而且在圖像理解任務上擊敗了閉源Claude 3 Haiku。
甚至,90B版本擊敗了GPT-4o mini。

就連英偉達高級科學家Jim Fan都不禁誇讚,在輕量級模型中,開源社區整體上並不落後!


同時,為了適配邊緣計算和終端設備,Meta還推出了1B和3B兩個輕量級純文本的版本,可支持128K上下文。

別看參數少,1B/3B在總結摘要、指令遵循、重寫等任務上,表現非常出色,而且專為Arm處理器做了優化。
LeCun激動地表示,「可愛的大羊駝寶寶來了」!

Meta首席技術官對Llama 3.2的發佈,做了兩大亮點總結:
首個既能識別圖像,又能理解文本的多模態模型。最重要的是,能夠媲美閉源模型
超輕量1B/3B模型,解鎖更多終端設備可能性

有網民對此點評道,這可能是改變遊戲規則的進步,邊緣設備AI正在壯大。

01 能力一覽
11B和90B這兩款模型,不僅支持圖像推理場景,包括圖表和圖形在內的文檔級理解、圖像描述以及視覺定位任務,而且還能基於現有圖表進行推理並快速給出回答。
比如,你可以問「去年哪個月銷售業績最好?」,Llama 3.2就會根據現有圖表進行推理,並迅速給出答案。
輕量級的1B和3B模型則可以幫助不僅在多語言文本生成和工具調用能力方面表現出色,而且具有強大的隱私保護,數據永遠不會離開設備。
之所以在本地運行模型備受大家的青睞,主要在於以下兩個主要優勢:
提示詞和響應能夠給人瞬間完成的感覺
應用程序可以清晰地控制哪些查詢留在設備上,哪些可能需要由雲端的更大模型處理

02 性能評估
結果顯示,Llama 3.2視覺模型在圖像識別等任務上,與Claude 3 Haiku和GPT-4o mini不相上下。
3B模型在遵循指令、總結、提示詞重寫和工具使用等任務上,表現優於Gemma 2 2B和Phi 3.5 mini;而1B模型則與Gemma旗鼓相當。

03 視覺模型
作為首批支持視覺任務的Llama模型,Meta為11B和90B型打造了一個全新的模型架構。
在圖像輸入方面,訓練了一組適配器權重,將預訓練的圖像編碼器集成到預訓練的大語言模型中。
具體來說,該適配器:
由一系列交叉注意力層組成,負責將圖像編碼器的表示輸入進大語言模型
通過在文本-圖像對上的訓練,實現圖像表示與語言表徵的對齊
在適配器訓練期間,Meta會對圖像編碼器的參數進行更新,但不會更新大語言模型參數。
也就是說,模型的純文本能力便不會受到任何影響,而開發者也可以將之前部署的Llama 3.1無縫替換成Llama 3.2。
具體的訓練流程如下:
首先,為預訓練的Llama 3.1文本模型添加圖像適配器和編碼器,並在大規模噪聲圖像-文本對數據上進行預訓練。
然後,在中等規模的高質量領域內和知識增強的圖像-文本對數據上,再次進行訓練。
接著,在後訓練階段採用與文本模型類似的方法,通過監督微調、拒絕采樣和直接偏好優化進行多輪對齊。並加入安全緩解數據,保障模型的輸出既安全又實用。
這在期間,模型所使用的高質量微調數據,正是來自合成數據生成技術——使用Llama 3.1模型在領域內圖像的基礎上過濾和增強問題答案,並使用獎勵模型對所有候選答案進行排序。
最終,我們就能得到一系列可以同時接受圖像和文本提示詞的模型,並能夠深入理解和對其組合進行推理。
對此,Meta自豪地表示表示:「這是Llama模型向更豐富的AI智能體能力邁進的又一步」。
得到全新Llama 3.2加持的助手Meta AI,在視覺理解力上非常強。
比如,上傳一張切開的生日蛋糕圖片,並問它製作配方。
Meta AI便會給出手把手教程,從配料到加工方式,一應俱全。

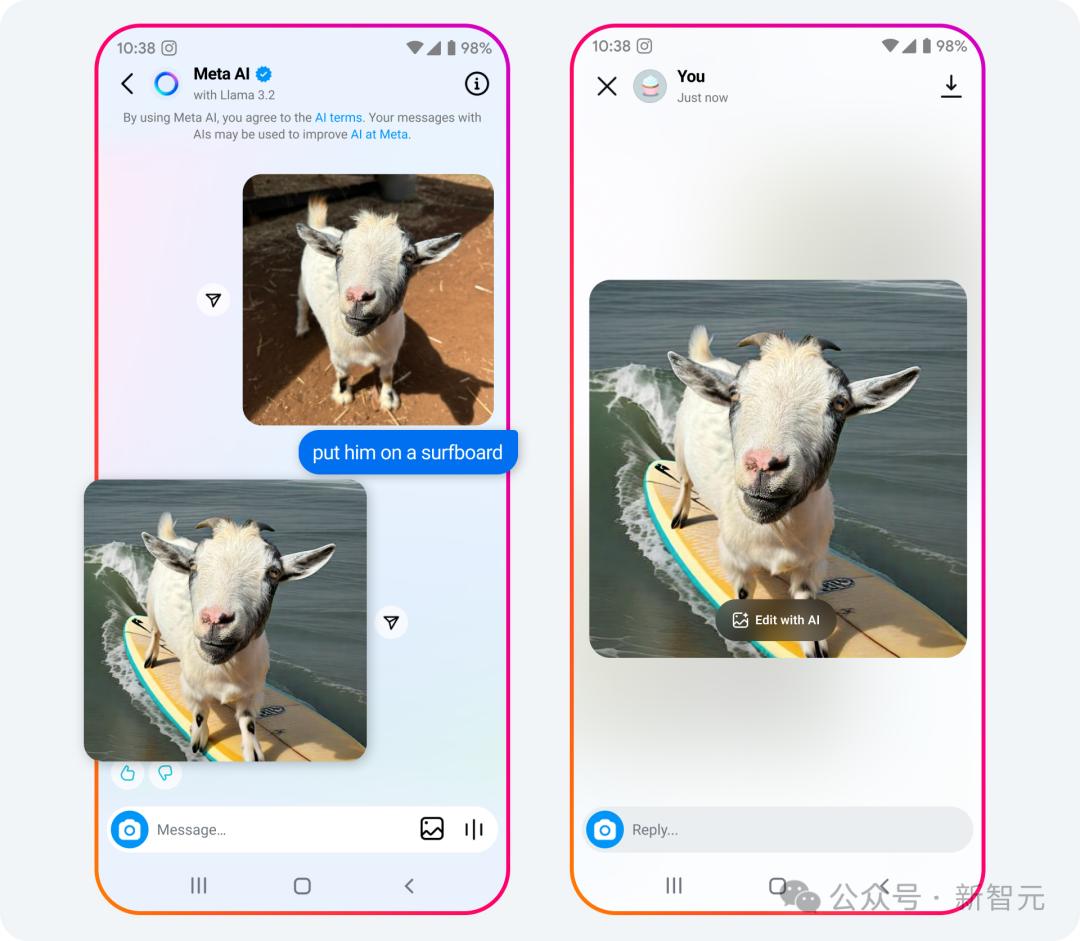
又或者你發給它一張小羊的照片,並要求將其放在衝浪板上。
不一會兒功夫,一隻站在衝浪板上的山羊圖畫好了。
04 輕量模型
通過利用剪枝(pruning)和蒸餾(distillation)這兩種方法,Meta讓全新的1B和3B模型,成為了首批能夠高效地適應設備的、具有高能力的輕量級Llama模型。
剪枝能夠減小Llama的規模,並儘可能地保留知識和性能
在此,Meta採用了從Llama 3.1 80億參數模型進行單次結構化剪枝的方法。也就是,系統地移除網絡的部分內容,並調整權重和梯度的幅度,從而創建一個更小、更高效的大語言模型,同時保留原始網絡的性能。
完成剪枝之後,則需要使用知識蒸餾來恢復模型的性能。
知識蒸餾是讓一個更大的網絡給更小的網絡傳授知識
也就是,較小的模型可以借助教師模型的指導,獲得比從頭開始訓練更好的性能。為此,Meta在預訓練階段融入了來自Llama 3.1 8B和70B模型的logits(模型輸出的原始預測值),並將這些較大模型的輸出則用作token級的目標。

後訓練階段,Meta採用了與Llama 3.1類似的方法——通過在預訓練大語言模型基礎上進行多輪對齊來生成最終的聊天模型。
其中,每一輪都包括監督微調(SFT,Supervised Fine-Tuning)、拒絕采樣(RS,Rejection Sampling)和直接偏好優化(DPO,Direct Preference Optimization)。
在這期間,Meta不僅將模型的上下文長度擴展到了128K token,而且還利用經過仔細篩選的合成數據和高質量的混合數據,對諸如總結、重寫、指令跟隨、語言推理和工具使用等多項能力進行了優化。
為了便於開源社區更好地基於Llama進行創新,Meta還與高通(Qualcomm)、聯發科(Mediatek)和Arm展開了密切合作。
值得一提的是,Meta這次發佈的權重為BFloat16格式。



05 Llama Stack發行版
Llama Stack API是一個標準化接口,用於規範工具鏈組件(如微調、合成數據生成等)以定製Llama大語言模型並構建AI智能體應用。
自從今年7月Meta提出了相關的意見徵求之後,社區反響非常熱烈。
如今,Meta正式推出Llama Stack發行版——可將多個能夠良好協同工作的API提供者打包在一起,為開發者提供單一接入點。
這種簡化且一致的使用體驗,讓開發者能夠在多種環境中使用Llama大語言模型,包括本地環境、雲端、單節點服務器和終端設備。

完整的發佈內容包括:
Llama CLI:用於構建、配置和運行Llama Stack發行版
多種語言的客戶端代碼:包括Python、Node.js、Kotlin和Swift
Docker容器:用於Llama Stack發行版服務器和AI智能體API供應商
多種發行版:
單節點Llama Stack發行版:通過Meta內部實現和Ollama提供
雲端Llama Stack發行版:通過AWS、Databricks、Fireworks和Together提供
設備端Llama Stack發行版:通過PyTorch ExecuTorch在iOS上實現
本地部署Llama Stack發行版:由Dell提供支持

06 系統安全
這次,Meta在模型安全方面主要進行了兩個更新:
1.Llama Guard 3 11B Vision
它支持Llama 3.2的全新圖像理解能力,並能過濾文本+圖像輸入提示詞或對這些提示詞的文本輸出響應。
2. Llama Guard 3 1B
它基於Llama 3.2 1B,並在剪枝和量化處理之後,將模型大小從2,858MB縮減至438MB,使部署效率達到前所未有的高度。

目前,這些新解決方案已經集成到了Meta的參考實現、演示和應用程序中,開源社區可以立即開始使用。
參考資料:
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。



















