重要的事情說兩遍!Prompt「複讀機」,顯著提高LLM推理能力

新智元報導
編輯:alan
【新智元導讀】儘管大模型能力非凡,但干細活的時候還是比不上人類。為了提高LLM的理解和推理能力,Prompt「複讀機」誕生了。
眾所周知,人類的本質是複讀機。
我們遵循複讀機的自我修養:敲黑板,劃重點,重要的事情說三遍。
but,事實上同樣的方法對付AI也有奇效!
有研究證明,在提問的時候故意重覆一遍——也就是複製黏貼,即可顯著提高LLM的推理能力。
 論文地址:https://arxiv.org/pdf/2309.06275
論文地址:https://arxiv.org/pdf/2309.06275看下面的例子:

作者認為,通常情況下,問題中的重點token(比如這裏的tennis balls)無法看到位於它後面的token(上圖)。
相比之下,使用重讀(re-reading,RE2)的方法,允許「tennis balls」在第二遍中看到自己對應的整個問題(How many tennis balls does he have now?),從而達到雙向理解的效果(下圖)。

實驗表明,在14個數據集上的112個實驗中,RE2技術都能帶來一致的性能提升,無論是經過指令調整的模型(如ChatGPT),還是未經調整的模型(如Llama)。
實踐中,RE2作為獨立的技巧,可以與CoT(Let’s think step by step)以及自我一致性方法(self-consistency,SC)一起使用。
下表展示了混合應用多種方法對模型效果的影響。儘管自我一致性聚合了多個答案,但重讀機制仍然有助於大多數場景的改進。

接下來,在GSM8K數據集上(使用ChatGPT)進一步研究輸入問題複雜性對CoT和RE2提示的推理性能的影響。
這裡通過計算真實解釋中存在的推理步驟來衡量問題的複雜性,結果如下圖所示。

隨著問題複雜性的增加,所有提示的表現通常都會下降,但重讀的引入提高了LLM應對各種複雜問題的表現。
此外,作者還計算了各代和輸入問題之間的覆蓋度,證明RE2增加了輸出解釋中的n-gram (n=1,2,3,4) 召回率。
重要的事情說2遍
現有的推理研究主要集中在設計多樣化引導提示,而對輸入階段的理解卻很少受到關注。
事實上,理解是解決問題的第一步,至關重要。
當今大多數LLM都採用單向注意力的decoder-only架構 ,在對問題進行編碼時,單向注意力限制了token的可見性,這可能會損害對問題的全局理解。

怎麼解決這個問題?作者受到人類習慣的啟發,嘗試讓LLM把輸入再讀一遍。
與引導模型在輸出中推理的CoT不同,RE2通過兩次處理問題將焦點轉移到輸入,促進了單向解碼器的雙向編碼,從而增強LLM理解過程。
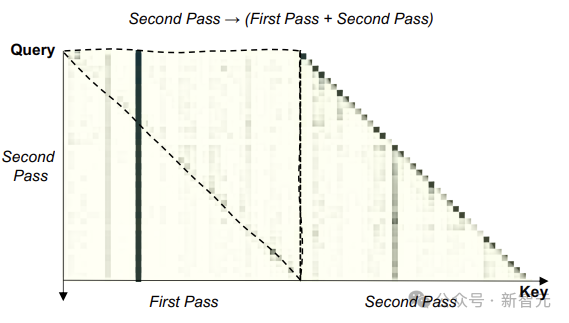 上圖為GSM8K數據集上測試的注意力分佈圖,較暗的單元格表示較高的注意力。
上圖為GSM8K數據集上測試的注意力分佈圖,較暗的單元格表示較高的注意力。上虛線三角形內的區域表明,第二遍輸入中的每個token都明顯關注第一遍中的後續token,證明LLM的重讀有望實現對問題的雙向理解。
從另一個角度考慮,重讀使LLM能夠為輸入編碼分配更多的計算資源,類似於水平增加神經網絡的深度。因此,擁有RE2的LLM對問題有更深入的理解。
普通推理
利用帶有CoT提示的LLM來解決推理任務,可以用公式表述為:

其中,Cx表示提示輸入,來自帶有CoT提示指令的模板,z表示自然語言中的采樣基本原理。
因此, LLM可以將複雜的任務分解為更易於管理的推理步驟,將每個步驟視為整個解決方案鏈的組成部分。
RE2 推理
受到人類重讀策略的啟發,將上面的方程改寫為:

所以RE2在實際應用中就是下面這種格式:

其中{Input Query}是輸入查詢的佔位符,左側部分可以包含其他引發思考的提示。
實驗
由於RE2的簡單性和對輸入階段的重視,它可以與各種LLM和算法無縫集成,包括few-shot、自我一致性、各種引發思考的提示策略等。
為了驗證RE2的有效性和通用性,研究人員在14個數據集上進行了112個實驗,涵蓋算術、常識和符號推理任務。
算術推理
實驗考慮以下七個算術推理基準:
數學應用題的GSM8K基準、具有不同結構的數學應用問題的SVAMP數據集、不同數學應用題的ASDiv數據集、代數應用題的AQuA數據集、三到五年級學生的加法和減法數學應用題、多步驟數學問題數據集,以及單次運算的初等數學應用題數據集。

上表為算術推理基準測試結果。*處表示不使用任何技巧,但效果優於CoT提示的情況。
常識和符號推理
對於常識推理,實驗採用StrategyQA、ARC和CSQA數據集。
StrategyQA數據集包含需要多步驟推理的問題;
ARC數據集(ARC-t)分為兩個集合:挑戰集(ARC-c)和簡單集(ARC-e),前者包含基於檢索和單詞共現算法都錯誤回答的問題;
CSQA數據集由需要各種常識知識的問題組成。
實驗評估兩個符號推理任務:日期理解和Coinflip。日期理解是 BigBench數據集的子集,Coinflip是一個問題數據集,根據問題中給出的步驟,判斷硬幣翻轉後是否仍然正面朝上。

結果表明,除了普通ChatGPT上的某些場景之外,具有簡單重讀策略的RE2,持續增強了LLM的推理性能。
RE2展示了跨各種LLM的多功能性(Text-Davinci-003、ChatGPT、LLaMA-2-13B和LLaMA-2-70B),涵蓋指令微調 (IFT) 和非IFT模型。
作者還對RE2在零樣本和少樣本的任務設置、思維引發的提示方法以及自洽設置方面進行了探索,突出了其通用性。
Prompting
實驗嚴格評估RE2模型在兩種基線提示方法上的性能:Vanilla(不添加特技)和CoT(通過逐步的思維過程來指導模型)。

針對不同的任務,作者在提示中設計了答案格式指令,以規範最終答案的結構,便於精確提取答案。

實驗的解碼策略使用貪婪解碼,溫度設置為0,從而產生確定性輸出。
最後探索一下問題重讀次數對推理性能的影響:

上圖展示了兩個不同的LLM的表現如何隨問題重讀次數的變化而變化。我們可以發現重讀2次使性能提高,之後隨著問題重讀次數增加,性能開始下降。
猜測原因有兩個:i)過度重覆問題可能會起到示範作用,鼓勵LLM重覆問題而不是生成答案,ii)重覆問題會顯著增加推理和預訓練之間的不一致。
參考資料:
https://arxiv.org/pdf/2309.06275



















