OpenAI華人科學家翁荔:人類如何培養出下一代聰明且安全的AI技術|鈦媒體AGI

AI 如何變得更加安全?
鈦媒體App 11月3日消息,華人青年科學家、OpenAI研究副總裁(安全)翁荔(Lilian Weng)近期在2024Bilibili超級科學晚上發表主題為《AI 安全與「培養」之道》的演講。這是其首次在國內發表關於 AI 技術的演講。
翁荔表示,ChatGPT橫空出世以來,AI技術如同搭乘了高速列車,迅速滲透並影響著人類。AI每天都在變化,需要我們用心引導、教育,確保是更好的服務於人類,同時確保安全。而一個既安全又智能的AI,無異於將為我們的生活帶來諸多裨益。
具體來說,隨著AI的智能化和自主化,確保其行為符合人類價值觀變得重要,AI可能因偏見而變得狹隘,或因對抗性攻擊而受到質疑。因此,需要用心引導AI,確保其服務於人類並確保安全,而AI安全是實現其潛在益處的基礎,類似於自動駕駛技術。
從數據層面,提供多樣、全面、正確的數據,可以減少AI的偏見,而依賴於多人標註的數據,以提高AI的準確性;同時,基於強化學習(RL)和基於人類反饋的強化學習(RLHF),通過獎懲機制訓練AI,類似於訓練小狗;此外,使用模型自我評價和詳細的行為規則來提升AI的輸出質量。比如,在文檔寫作和影片音樂製作中,普通人可以通過設定背景、角色思想和關鍵詞來引導AI。
翁荔畢業於北京大學信息管理系,如今該系名為北京大學數字人文實驗室,她是2005 級本科生,是「兜樂」項目的骨幹設計人員,畢業後赴美攻讀博士學位,曾就職於Facebook,如今是OpenAI華人科學家、ChatGPT的貢獻者之一。
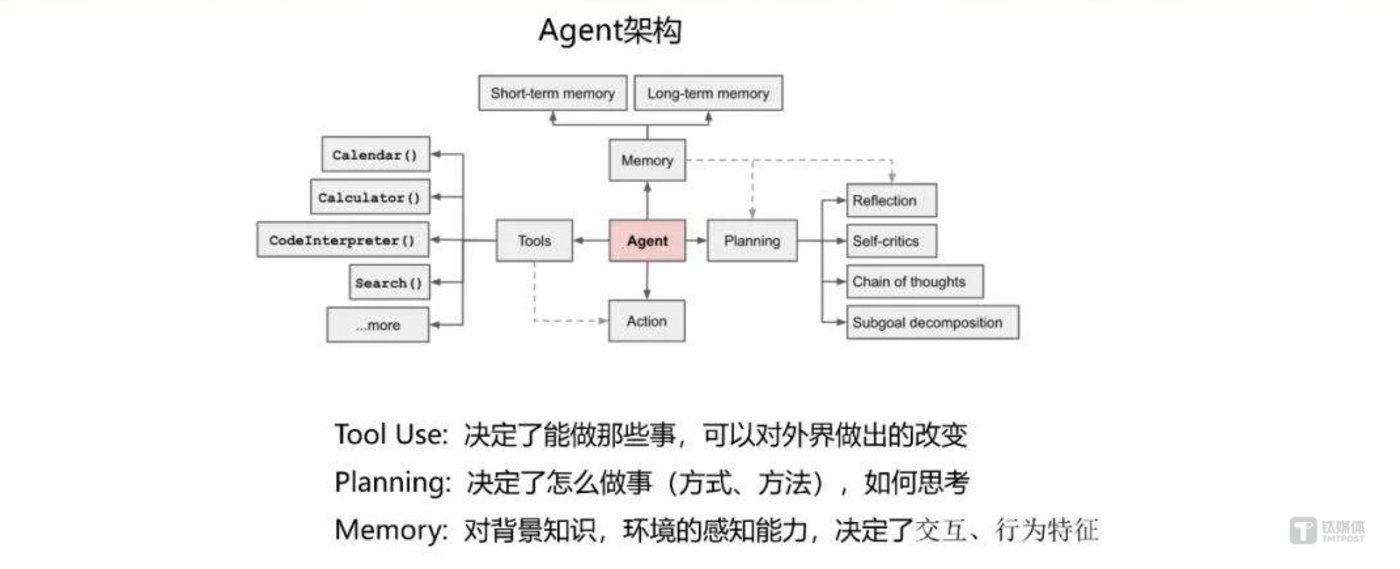
翁荔在2018年加入OpenAI,後來在GPT-4項目中主要參與預訓練、強化學習&對齊、模型安全等方面的工作。她曾提出最著名的Agent公式——Agent=大模型+記憶+主動規劃+工具使用。
翁荔在演講中表示,人類需要教會AI安全基本原則和道德準則,使其成為人類的夥伴。同時,通過思維鏈(CoT)推理和擴展性研究來提升AI的可靠性和監督。
翁荔強調,AI安全需要每個人的參與,社區可以共同影響AI的成長。
「AI的安全不僅僅是研究者的責任,它需要每一個人的參與。AI 技術是一把雙刃劍,它帶來的便利和挑戰並行,我們的參與至關重要。」翁荔稱。
以下是翁荔演講內容,經鈦媒體AGI編輯整理:
大家好,我是翁荔。今天我想與大家探討一個既深刻又有趣的話題,AI安全,以及我們如何像培養下一代一樣,培育出既聰明又安全的人工智能。
繼ChatGPT橫空出世以來,AI技術如同搭乘了高速列車,迅速滲透並影響著我們的日常。
AI每天都在進化,需要我們用心引導與教育,以確保其更好地服務於人類,同時確保安全無虞。一個既安全又智能的AI無疑將為我們的生活帶來諸多裨益。
試想一下,一個能洞察你生活習慣的智能家居系統,能根據你的需求自動調節室內溫度和光線,或是一個時刻關注你健康狀況的AI助手,能為你提供量身定製的健康建議。
AI不僅能顯著提升我們的生活質量,還能開闢新的就業領域,提升工作效率。
然而,這一切均建立在AI安全的基礎之上。正如自動駕駛技術一樣,它能極大的提升生活便利性,但是一旦出錯,後果可能不堪設想。
隨著AI應用日益智能化與自主化,如何確保AI的行為符合人類價值觀,真正做到以人為本,成為了AI安全與對齊研究的核心議題。人類在成長過程中會不斷學習進步,但也會遇到成長的煩惱。AI同樣如此,它可能會因為數據偏見而變得狹隘,也可能因為對抗性攻擊而被惡意利用。
悉心教育,也就是AI安全和對其研究,才能使AI成長過程更加順利。
讓我們以健康領域的應用為例,很多疾病研究的數據往往以男性群體為主,這可能導致AI在處理女性的健康問題時風險評估不準確。此外數據本身也有可能存在偏見,比如有研究表明女性心臟病症狀更容易被歸結成焦慮等心理問題而造成診斷遺漏。因此,我們需要通過對AI安全和對其的研究來減少這種偏見。
AI學習的基礎是數據,數據是它的實物,要想讓AI變得聰明可靠,我們必須確保它營養均衡,也就是提供多樣、全面、正確的數據,幫助它能夠正確的理解這個複雜的世界並減少偏差。
在使用人類標註的數據時,我們可以依賴於群體智慧,也就是the wisdom of the crowd,即同一個數據點被多人標註多數票獲勝,這種方法簡單而有效。有意思的是,1907年的一篇自然科學雜誌中的文章,作者追蹤了一場年度展覽會上的一個有趣的競有獎競猜。展覽會上人們選出一頭肥牛,讓大家來猜測牛的重量,最接近真實數據的人將獲得大額的獎金。
作者發現,最中間值往往是最接近真實的the medium value,而這個數估計值也被稱為wax popular。它是拉丁語中the voice of the people,也就是人民的聲音的意思。在這篇將近120年前的科學文章中,作者總結道,我認為這個結果比人們預期的更能證明民主判斷的可信度。這也是最早提到群體智慧如何發生作用的科學文獻。
而至於如何把高質量標註的數據喂給AI,基於人類反饋的強化學習,也就是RLHF技術起到了關鍵作用。
在瞭解RLHF之前,讓我們快速瞭解一下什麼是RL reinforce learning。強化學習是一種機器學習方法,它主要通過獎懲機制來讓模型學會完成任務,而不是依靠直接告訴模型如何去做這些任務。想像一下它就好像你要訓練小狗,如果小狗做對了一個動作,比如坐下你就給它一塊骨頭餅乾,做錯了就不給獎勵。這樣小狗就會因為想吃到更多的餅乾,而學會如何正確的坐下。

同理,AI也在這種獎懲機制中學習,通過不斷的嘗試並得到反饋,找到最佳的行動策略。一個早期的研究表明,強化學習能利用少量人類反饋,快速有效的教會智能體做複雜的動作,比如學會如何後空翻。
同樣的方法也可以用於訓練大語言模型。當我們看到,針對同一問題的不同AI回答時,我們可以告訴模型,哪一個回答更好、更正確、更符合人類價值觀。這樣我們就像家長糾正孩子一樣,能夠調節AI的學習過程。
此外,我們還可以使用模型本身作為輸出I輸出質量的評分者。比如在entropic發表的constitutional AI中,模型就通過對自己行為的自我評價進行改進。或者像OpenAI最近發表的對齊強化學習中,我們可以製定非常詳細的行為規則來告訴AI,比如如何何時拒絕用戶的請求,如何表達同理心等等。然後我們在RL的獎勵機制中,非常精準的來給予相應的評分和獎勵。這個過程中,一個更加強大的AI有能力更精準的判斷他是否有在遵循人類的價值觀和行為準則。
總之,強化學習技術就像一把鑰匙,幫助我們打開AI高質量學習和發展的大門。在培養AI更懂我們的過程中,普通人也能發揮重要的作用。
在文檔寫作,我們可以採用兩個小技巧。首先設定詳細的背景和角色,就像導演為演員準備劇本一樣,讓AI在豐富的情境中捕捉我們的意圖。其次,精心挑選關鍵詞,構建邏輯清晰的文檔結構,使文檔既美觀又實用。
在影片音樂製作領域,我們可以通過使用專業術語來引導AI比如黃金分割構圖或和弦進行將創意轉化為現實。同時別忘了感情的投入,因為這是賦予靈作品靈魂的關鍵。
簡而言之,通過細緻的指導和情感的融入,我們可以幫助AI創作出既豐富又富有感染力的作品。
在西遊記中,孫悟空有緊箍咒約束行為,我們應該給AI模型也帶上緊箍咒,也就是教會AI安全基本準則約束和道德標準,讓其遵守行為規範。以人類利益為先,成為我們貼心的夥伴,而不是冰冷的機器。
讓AI學習基本原則和道德準則,可以使模型在面對複雜問題時運用推理得出正確的結論。
比如在OpenAI最近發表的o1-preview模型中,我們通過思維鏈推理,加強了模型的魯棒性,Robust使得模型可以更好的抵抗越獄攻擊。
擴展性監督在AI對其研究中也非常重要。隨著AI模型擴大,需要結合自動化工具和人類監督,有效的監督其行為,確保它朝著正確的方向發展。在一組研究中,我們用監督學習訓練語言模型,對網絡文本摘要進行批評。比如提高提供這個摘要非常準確,或者這個摘要遺漏了要點等等。評論相比對照組,我們發現有AI幫助的標註員比沒有幫助的能多。找出摘要中約50%的問題,而且多數批評都參考了模型提供的內容。總之,給AI設定標準並進行有效監督,可以提升它對人們的幫助。
其實,AI的安全不僅僅是研究者的責任,它需要每一個人的參與。
以B站為例,這個充滿活力的社區聚集了眾多AI愛好者和創作者,我們在這裏分享見解、討論問題,甚至監督AI的表現,共同影響著AI的成長。
我們每個人都應該成為AI的大家長,不僅監督和反饋AI的表現,還參與塑造一個安全可信的AI 世界。
AI技術是一個雙刃劍,它帶來了便利與挑戰並行,我們的參與至關重要。讓我們攜手培養出一個既聰明又負責的AI夥伴。感謝大家的聆聽,希望今天的分享能激發大家對於安全的熱情和興趣。也感謝B站提供這個平台,讓我們共同為AI的未來貢獻力量。
謝謝。
(本文正選於鈦媒體App,作者|林誌佳,編輯|胡潤峰)