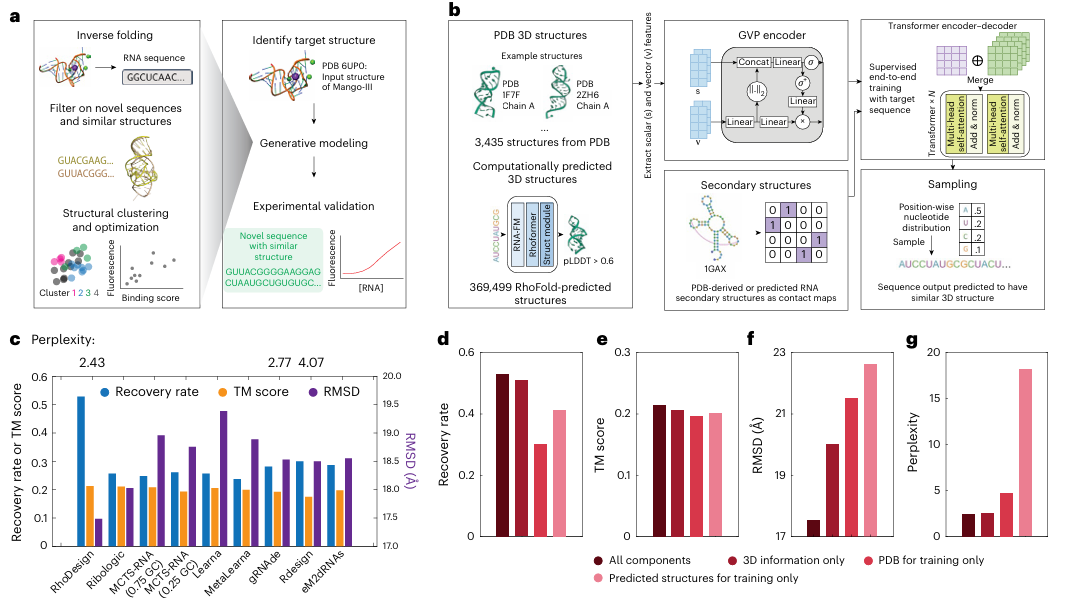
預見·科技 | 國產視頻生成模型加速迭代 可一鍵創作影視級高清視頻
封面新聞記者 孟梅 歐陽宏宇
自文本生成、文生圖等多模態大模型後,廠商們紛紛開始湧向視頻生成大模型。
9月19日,在杭州雲棲大會上,通義萬相宣佈全面升級,並發佈全新視頻生成模型。據瞭解,迭代後,該大模型可一鍵生成影視級高清視頻,並已開放免費體驗。
據介紹,通義萬相首批上線了文生視頻、圖生視頻功能:在文生視頻功能中,用戶輸入任意文字提示詞,即可生成一段高清視頻,支援中英文多語言輸入,並可以通過靈感擴寫功能智能豐富視頻內容表現力,支援16:9、9:16等多種比例生成;在圖生視頻功能中,支援用戶將任意圖片轉化為動態視頻,按照上傳的圖像比例或預設比例進行生成,同時可以通過提示詞來控制視頻運動。
記者首先向該大模型輸入“千里江山圖古畫,木舟在江上穿梭,江兩岸高山連綿”的文案,要求製作一段視頻。大概10分鐘左右,大模型完成了視頻製作。
國漫3D風格的視頻中,船隻在峽穀中穿梭,遠方群山環繞,雲遮霧繞。
隨後,記者又上傳了一張“飛碟從街道上空飛過”的圖片,要求大模型將該圖片生成為視頻。很快,通義萬相就根據相關圖片生成了一段視頻。

視頻中,大模型為飛碟配上了非常賽博的背景音,而且由近及遠,給人一種真實的感覺。
記者體驗發現,大模型生成的視頻最長5秒左右,每秒30幀,解像度為720P,還能生成與畫面匹配的音效。
和過去AI根據文本描述進行要素的堆砌不同,AI生成視頻大模型發展到現在已經越來越呈現出具有合理運動和模擬物理世界特性的視頻。
事實上,在Sora橫空出世,很多國內廠商都把AI生成視頻作為追逐的焦點。不久前,快手上線了自研的視頻生成大模型“可靈”,智譜AI也緊隨其後推出AI生成視頻模型智譜清言。此外,百度、騰訊、字節都在積極佈局,爭做“中國版Sora”。
要成為“中國版Sora”,關鍵是解決畫面表現力和大幅度運動等視頻生成技術難題。通義萬相相關負責人透露,視頻生成大模型技術的提升,主要在於針對運動生成和物理模擬等難點優化算法,實現大幅度主體運動和運鏡控制,並有效模擬真實世界物理特性。同時,設計了高壓縮比、高質量視頻VAE框架,有效降低視頻信息冗餘,並保持高質量視頻重構能力。
雖然和能生成60秒視頻的Sora相比,國產視頻生成大模型所製作的視頻在時長上仍然有提升空間,不過在電商、廣告、影視等領域,現階段的時長已基本滿足使用。業內人士表示,視頻生成大模型免費開放給用戶使用,能夠為創作者提供更多靈感來源,生成的影視級高清視頻,已在一定程度上可應用於影視創作、動畫設計、廣告設計等領域。