為什麼大語言模型沒能「殺死」心理學?
文 | 追問nextquestion
自2022年底以來,ChatGPT如一股澎湃的春潮,席捲了全球,人們對其潛在的應用場景無不心生嚮往。商界人士、學者乃至日常生活中的普通人,都在思索同一個問題:自己的工作未來會如何被AI塑造?
隨著時間流逝,很多構想逐漸落地,人類似乎已經習慣於AI在許多工作場景幫助甚至替代我們的實際工作。早期人們對GPT的恐懼逐漸消散,反而變得過度依賴GPT,甚至忽略了可能的局限性與風險。這種大肆依賴GPT並忽視其風險的情況,我們稱之為「GPT學」(GPTology)。
心理學的發展一直緊緊跟隨科技的創新,社會學家與行為科學家總是依賴儘可能多的技術來收集豐富的數據類型,從神經影像技術、在線調查平台到眼動追蹤技術的開發等,都助力心理學取得了關鍵性的突破。數字革命和大數據的興起推動了計算社會科學等新學科的形成。正如其他領域(醫學[1]、政治[2])一樣,能夠以驚人的微妙性和複雜性理解、生成和翻譯人類語言的大語言模型(LLM),對心理學也產生了深遠的影響。
在心理學領域,大語言模型有兩類主流應用模式:一方面,通過研究大語言模型本身的機制,可能對人類認知的研究提供新的見解;另一方面,這些模型在文本分析和生成方面的能力,使得它成為了分析文本數據的強大工具,如它們能將個人的書面或口頭表達等文本數據,轉化為可分析的數據形式,從而協助心理健康專業人員評估和理解個體的心理狀態。最近,使用大語言模型促進心理學研究的成果大量湧現,ChatGPT在社會與行為科學領域的應用,如仇恨言論分類、情感分析等,已顯示出其初步成果和廣闊的發展前景。
然而,我們應該放任現在「GPT學」的形勢在科研領域肆虐嗎?事實上所有科技創新的融合過程總是充滿動盪的,放任某種技術的應用與對其依賴過深,都可能會導致意想不到的後果。回望心理學的發展歷程,當功能性磁共振成像(fMRI)技術初露鋒芒時,便有研究者濫用此技術,導致了一些荒謬卻在統計學上顯著的神經關聯現象——譬如,研究人員對一條已經死亡的大西洋鮭魚進行了fMRI掃瞄,結果顯示該魚在實驗期間表現出顯著的腦活動;還有研究表明,由於統計誤用,fMRI研究中發現虛假相關性的可能性極高。這些研究已經進入心理學的教科書,警示所有心理學學生與研究人員在面對新技術時應保持警惕。

▷Abdurahman, Suhaib, et al. “Perils and opportunities in using large language models in psychological research.” PNAS nexus 3.7 (2024): pgae245.
可以說,我們已經進入了與大語言模型相處的「冷靜期」,除了思考大語言模型可以做什麼,我們更需要反思是否以及為何要使用它。近日PNAS Nexus的綜述論文便探討了大語言模型在心理學研究中的應用,及其為研究人類行為學帶來的新機遇。
文章承認LLMs在提升心理學方面的潛在效用,但同時也強調了對其未經審慎應用的警惕。目前這些模型在心理學研究中可能引起的統計上顯著但意義不明確的相關性,是研究者必須避免的。作者提醒到,面對近幾十年來該領域遇到的類似挑戰(如可信度革命),研究人員應謹慎對待LLMs的應用。該文還提出了在未來如何更批判性和謹慎性地利用這些模型以推進心理學研究的方向。
01 大語言模型可以替代人類被試嗎?
提到大語言模型,人們最直觀的感受便是其高度「類人」的輸出能力。Webb等人考察了ChatGPT的類比推理能力[3],發現它已湧現出了零樣本推理能力,能夠在沒有明確訓練的情況下解決廣泛的類比推理問題。一些人認為,如果像ChatGPT這樣的LLM確實能夠對心理學中的常見測量產生類似人類的響應(例如對行動的判斷、對價值的認可、對社會問題的看法),那麼它們在未來可能會取代人類受試者群體。
針對這個問題,Dillion等人進行了專門的研究[4]:首先,通過比較人類與語言模型(GPT-3.5)在道德判斷上的相關性,他們肯定了語言模型可以複製一些人類判斷的觀點;但他們也提出瞭解釋語言模型輸出的挑戰。從原理上說,LLM的「思維」建立在人類的自然表達之上,但實際能代表的人群有限,並且有過於簡化人類複雜行為思想的風險。這是一種警示,因為這種對AI系統擬人化的傾向可能會誤導我們,讓我們期望那些基於根本不同原理運行的系統表現出類人表現。
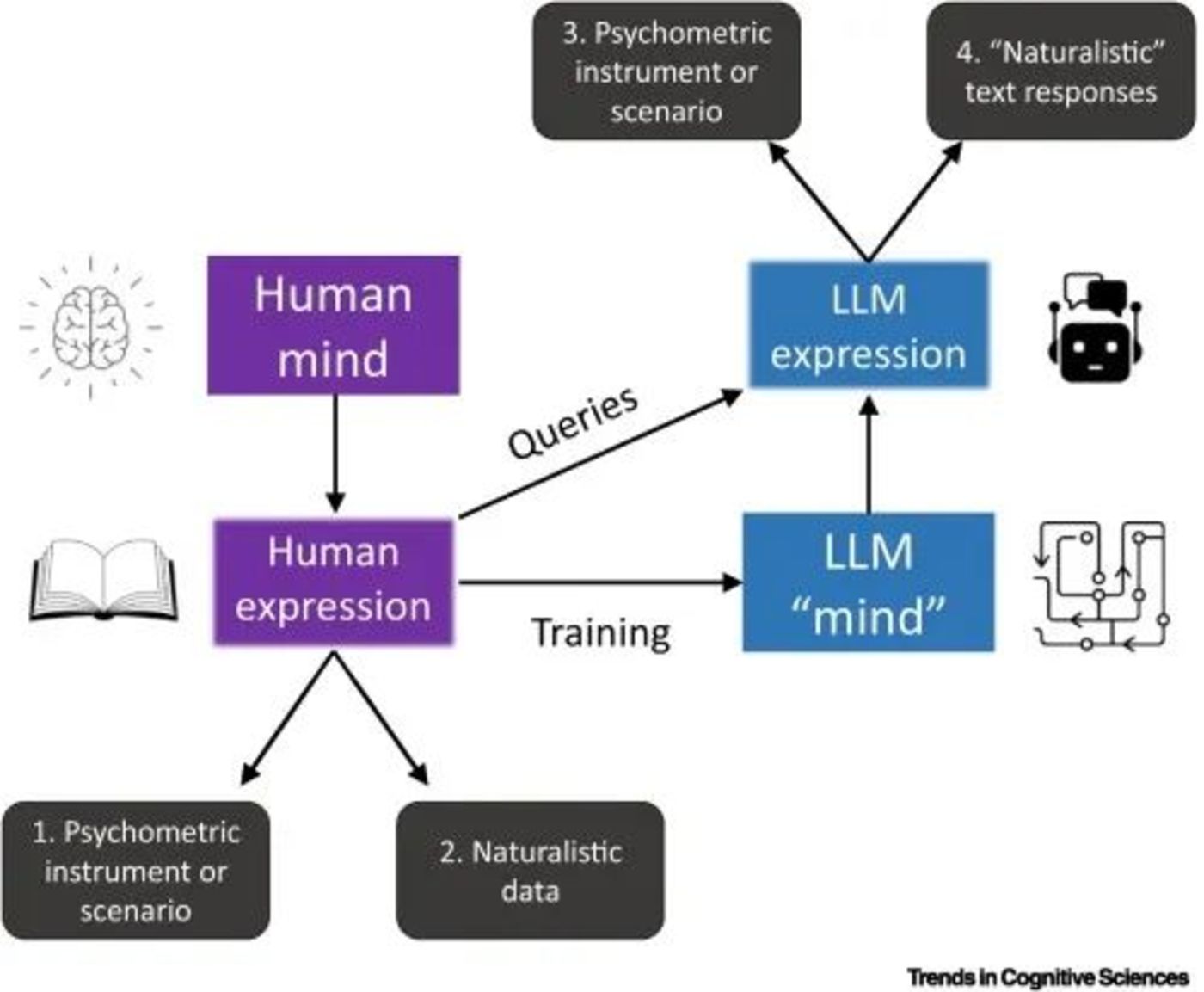
從目前的研究來看,使用LLM模擬人類被試至少有三大問題。
首先,認知過程的跨文化差異是心理學研究中極為重要的一環,但很多證據表明,目前流行的大語言模型無法模擬出這樣的差異。像GPT這樣的模型主要基於WEIRD(西方、受過教育的、工業化的、富裕的、民主的)人群的文本數據訓練。這種以英語為中心的數據處理延續了心理學的英語中心主義,與對語言多樣性的期待背道而馳。語言模型也因此難以準確反映大眾群體的多樣性。例如,ChatGPT顯示出偏向男性視角和敘事的性別偏見,偏向美國視角或一般多數人群的文化偏見,以及偏向自由主義、環保和左翼自由意志主義觀點的政治偏見。這些偏見還延伸到個性、道德和刻板印象。
總的來說,由於模型輸出高度反映WEIRD人群心理,當人類樣本不那麼WEIRD時,AI與人類之間的高度相關性無法重現。在心理學研究中,過度依賴WEIRD被試(例如北美的大學生)的現像一度引發了討論,用LLM的輸出替代人類參與者將是一個倒退,會使得心理學研究變得更加狹隘,普適性更差。
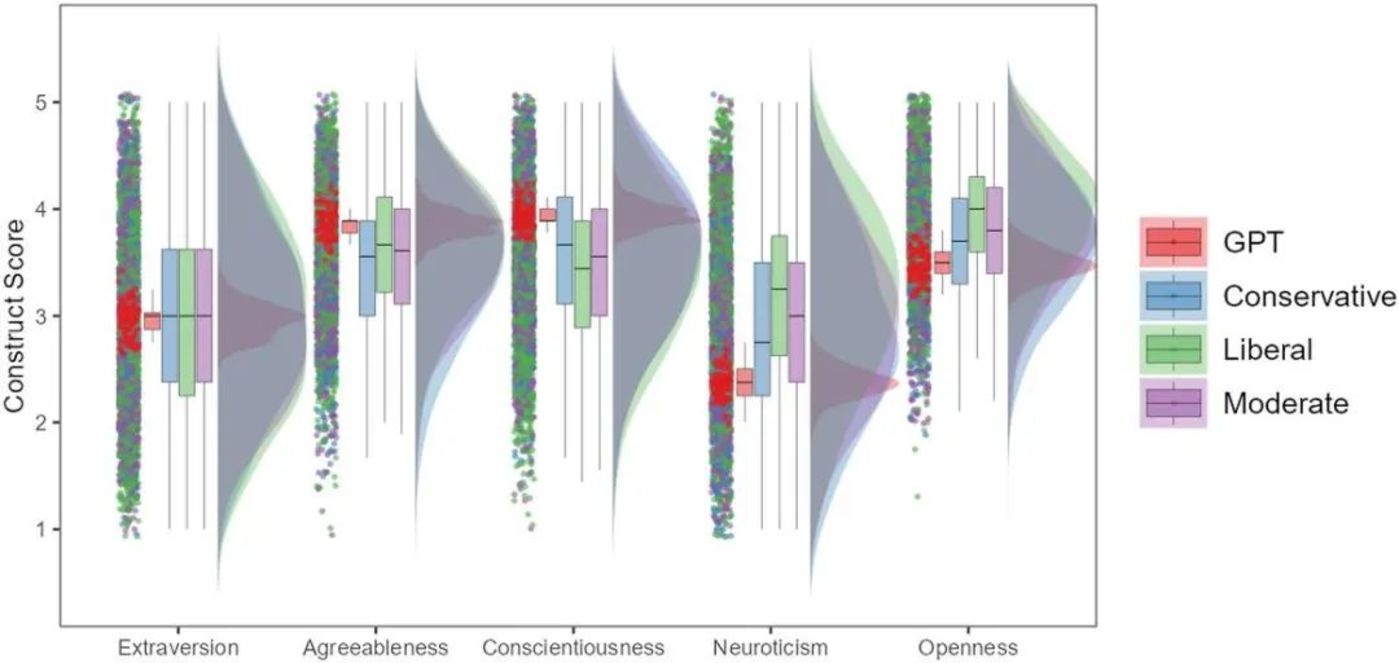
▷將 ChatGPT與按政治觀點分組的人類對「大五人格」的反應進行比較。註:圖中顯示了人類和ChatGPT在大五人格結構和不同人口統計數據中的響應分佈。圖中顯示,ChatGPT 在宜人性、盡責性方面給出了顯著更高的響應,而在開放性和神經質方面給出了顯著較低的響應。重要的是,與所有人口統計群體相比,ChatGPT在所有個性維度上顯示出顯著較小的差異。
其次,大語言模型似乎存在「正確答案」偏好,也就是說LLM在回答心理學調查的問題時變化幅度較小——即使這些問題涉及的主題(例如道德判斷)並沒有實際的正確答案——而人類對這些問題的回答往往具有多樣性。當要求LLM多次回答同一個問題,並測量其回答的差異時,我們會發現大語言模型的回答無法像人類一樣產生思想上顯著的差異。這依舊與生成式語言模型背後的原理分不開,它們通過自回歸的方式計算下一個可能出現的單詞的概率分佈來生成輸出序列。從概念上講,反復向LLM提問類似於反復向同一個參與者提問,而不是向不同的參與者提問。
然而,心理學家通常感興趣的是研究不同參與者之間的差異。這警告我們當想用大語言模型模擬人類被試時,不能簡單地用大語言模型模擬群體平均值,或用它模擬個體在不同任務中的反應;應當開發出合適的方法真實再現人類樣本複雜性。此外,訓練大語言模型的數據可能已經包含許多心理學實驗中使用的項目和任務,導致模型在接受測試時依賴記憶而不是推理,又進一步加劇了上述問題。為了獲得對LLM類人行為的無偏評估,研究人員需要確保他們的任務不屬於模型的訓練數據,或調整模型以避免影響實驗結果,比如通過「去學習」等方法。
最後,GPT是否真的形成與人類類似的道德體系也是值得懷疑的。通過向LLM提問,建立它內在的邏輯關係網絡(nomological network),觀察不同道德領域之間的相關性,發現這兩個指標都與基於人類得到的結果大不相同。
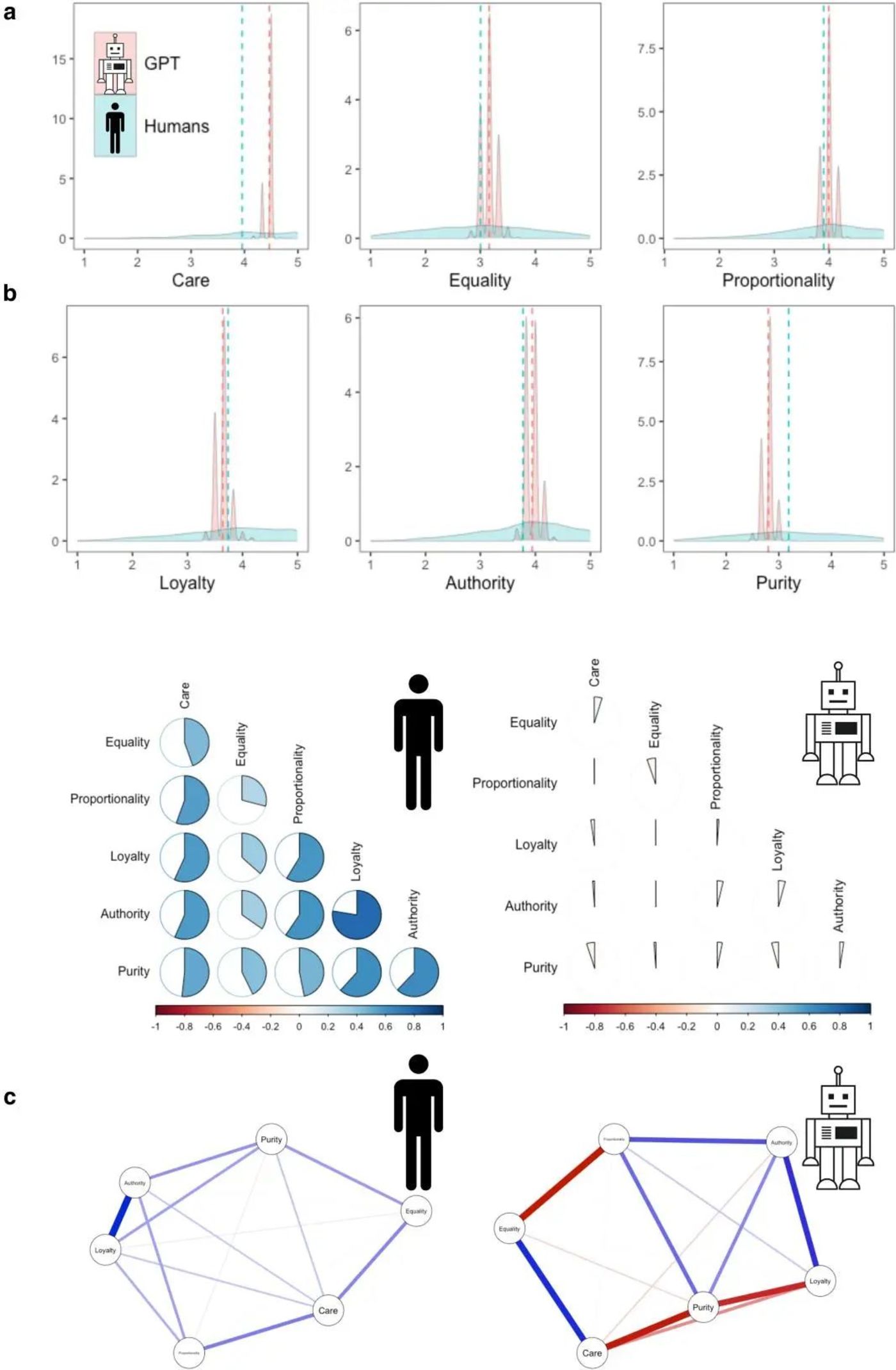
▷ChatGPT 與人類道德判斷。註:a)人類道德判斷(淺藍色)和GPT(淺紅色)在六個道德領域的分佈。虛線代表平均值。b) 人類道德價值觀之間的相互關係(?=3902)和 ChatGPT 問答(?=1000)。c) 基於來自 19 個國家 (30) 的不同人類樣本和 1000 個 GPT 問答的道德價值觀之間的部分相關網絡。藍色邊緣表示正偏相關,紅色邊緣表示負偏相關。
總結來說,LLM會忽略人群的多樣性,無法表現出顯著性差異,無法複現邏輯關係網絡——這些不足告訴我們,LLM不應該取代對智人(Homo sapiens)的研究,但這並不意味著心理學研究要完全摒棄LLM的使用。一方面,將傳統上用於人類的心理學測量用於AI的確有趣,但是對其結果的解讀應當更加謹慎;另一方面,將LLM作為人類的代理模型模擬人類行為時,其中間層參數可以為我們提供探索人類認知行為的潛在角度,但這一過程應該在嚴格定義了環境、代理、互動及結果的前提下進行的。
由於LLM的「黑箱」特徵,以及前文提到的輸出經常與人類真實行為不一樣的現狀,這種期盼還很難成真。但我們可以期待,未來也許可以開發出更穩健的程序,使得在心理學研究中的LLM模擬人類行為變得更加可行。
02 大語言模型是文本分析的打雜嗎?
除了其仿人的特質,LLM最大的特點便是其強大的語言處理能力,然而將自然語言處理方法用於心理學研究並不是新生之物,想要理解為什麼LLM的應用引起當下如此大的爭議,我們需要瞭解它在應用上與傳統的自然語言處理方法有什麼不同。
使用預訓練語言模型的自然語言處理(NLP)方法,可以按照是否涉及參數更新分為兩類。涉及參數更新意味著將預訓練的語言模型在特定任務的數據集上進行進一步訓練。相比之下,零樣本學習(zero-shot learning)、單樣本學習(one-shot learning)和少樣本學習(few-shot learning)則不需要進行梯度更新,它們直接利用預訓練模型的能力,從有限的或沒有任務特定數據中進行泛化,借助模型的已有知識和理解來完成任務。
LLM能力的跨時代飛躍——例如它能夠在無需特定任務調整的情況下處理多種任務,用戶友好的設計也減少了對複雜編碼的需求——使得最近越來越多研究將其零樣本能力*用於心理學文本分析,包括情感分析、攻擊性語言識別、思維方式或情感檢測等多種方面。
*LLM零樣本能力是指模型在沒有接受過特定任務的訓練或優化的情況下,直接利用其預訓練時獲得的知識來理解和執行新的任務。例如,大語言模型能在沒有針對性訓練數據的支持下,通過理解文本內容和上下文,識別文本是積極的、消極的還是中性的。
然而,隨著應用的深入,越來越多的聲音開始指出LLM的局限性。首先,LLMs在面對微小的提示變化時可能會產生不一致的輸出,並且在彙總多次重覆對不同提示的輸出時,LLM有時也無法達到科學可靠性的標準。其次,Kocoń等人[5]發現,LLMs在處理複雜、主觀性任務(如情感識別)時可能會遇到困難。最後,反觀傳統的微調模型,LLMs零樣本應用的便利性與模型微調之間的差異可能並不像通常認為的那樣顯著。
我們要知道,針對各種任務微調過的小型語言模型也不斷在發展,如今越來越多的模型變得公開可用;同時也有越來越多高質量和專業化的數據集可供研究人員用於微調語言模型。儘管LLMs的零樣本應用可能提供了即時的便利性,但最便捷的選擇往往並不是最有效的,研究者應在被便利性吸引時保持必要的謹慎。
為了更直觀地觀察ChatGPT在文本處理方面的能力,研究者們設置了三種水平的模型:零樣本、少樣本和微調,來分別提取在線文本中的道德價值觀。這是一個艱巨的任務,因為即使是經過培訓的人類標註者也常常意見不一。語言中道德價值觀的表達通常極度隱晦,而由於長度限制,在線帖子往往包含很少的背景信息。研究者提供了2983個包含道德或非道德語言的社交媒體帖子給ChatGPT,並要求它判斷帖子是否使用了任何特定類型的道德語言。然後將其與一個在單獨的社交媒體帖子子集中微調的小型BERT模型進行了比較,以人類評價者的判定作為評判標準。
結果發現,微調後的BERT模型表現遠勝於零樣本設置下的ChatGPT,BERT達到了0.48的F1分數,而ChatGPT只有0.22,即使是基於LIWC的方法也在F1分數上超過了ChatGPT(零樣本),達到了0.27。ChatGPT在預測道德情感方面表現得極其極端,而BERT幾乎在所有情況下與經過培訓的人類標註者的差異並不顯著。
儘管LIWC是一個規模更小、複雜度更低且成本更低的模型,但在偏離經過訓練的人類標註者方面的可能性和極端程度顯著低於ChatGPT。如預期的那樣,在實驗中,少樣本學習和微調均提升了ChatGPT的表現。我們得出兩個結論:首先,LLM所宣稱的跨上下文和靈活性優勢可能並不總是成立;其次,雖然LLM「即插即用」很是便利,但有時可能會徹底失敗,而適當的微調可以緩解這些問題。
除了文本標註中的不一致性、解釋複雜概念(如隱性仇恨言論)的不足,以及在專業或敏感領域可能缺乏深度這幾個方面外,缺乏可解釋性也是LLM飽受詬病之處。LLMs作為強大的語言分析工具,其廣泛的功能來自於龐大的參數集、訓練數據和訓練過程,然而這種靈活性和性能的提升是以降低可解釋性和可重覆性為代價的。LLM所謂的更強預測能力,是心理學文本分析研究者傾向於使用基於神經網絡的模型的重要原因。但如果無法顯著超越自上而下的方法的話,那麼後者在可解釋性上的優勢可能促使心理學家及其他社會科學家轉而使用更傳統的模型。
綜合來看,在許多應用場景中,較小的(經過微調的)模型可以比當前的大型(生成式)語言模型更強大且更少偏差,尤其當大語言模型處於零樣本和少樣本設置中時。比如,在探索焦慮症患者在線支持論壇的語言時,使用較小的、專門化的語言模型的研究人員可能能夠發現與研究領域直接相關的微妙細節和特定的語言模式(例如,擔憂、不確定性的耐受性)。這種有針對性的方法可以深入瞭解焦慮症患者的經歷,揭示他們獨特的挑戰和潛在的干預措施。通過利用專門化的語言模型或像CCR、LIWC這樣的自上而下的方法,研究人員可以在廣度和深度之間取得平衡,從而能夠更精細地探索文本數據。
儘管如此,LLMs作為文本分析工具,在微調數據稀缺的情況下——例如新興概念或研究不足的群體時——其零樣本能力可能仍然可以提供有價值的表現,使研究人員能夠探討一些緊迫的研究課題。在這些情況下,採用少樣本提示(few-shot prompting)的方法可能既有效又高效,因為它們只需要少量具有代表性的示例即可進行。
另外,有研究表明LLMs可以從理論驅動的方法中受益,基於這個發現,開發能夠結合這兩種方法優勢的技術,是未來研究的一個有前景的方向。隨著大型語言模型技術的快速進展,解決其性能和偏差問題只是時間問題,預計這些挑戰將在不遠的將來得到有效緩解。
03 不可忽略的可重覆性
可重覆性指的是使用相同的數據和方法可以複製和驗證結果的能力。然而,LLM的黑箱特性使得相關研究結果難以再現。對依賴LLM生成的數據或分析的研究來說,這一限制構成了實現再現性的重大障礙。
例如,LLM經過更新,其偏好可能會發生變化,這可能會影響先前已建立的「最佳實例」和「去偏差策略「的有效性。目前,ChatGPT及其他閉源模型並不提供它們的舊版本,這限制了研究人員使用特定時間點的模型來複現研究結果的能力。例如,「gpt3.5-January-2023」版本一旦更新,先前的參數和生成的輸出也可能隨之改變,這對科研的嚴謹性構成挑戰。重要的是,新版本並不保證在所有任務上的性能都會相同或更好。例如,GPT-3.5和GPT-4被報導在各種文本分析任務上存在不一致的結果——GPT-4有時表現得比GPT-3.5更差[6]——這進一步加深了人們對模型的非透明變化的擔憂。
除了從科學的開放性(open science)角度來看LLM的黑箱性質,研究人員更在意的其實是「知其然,知其所以然」的科研精神——在獲得高質量、有信息量的語義表示時,我們更應該關注的是用於生成這些輸出的算法,而不是輸出結果本身。在過去,計算模型的主要優勢之一在於它們允許我們「窺探內部」,某些心理過程難以被測試但可以通過模型進行推斷。因此,使用不提供此級別訪問權限的專有LLMs,可能會阻礙心理學和其他領域研究者從計算科學的最新進展中獲益。
04 總結
新一代對大眾開發的在線服務型LLM(如ChatGPT、Gemini、Claude)為許多研究人員提供了一個既強大又易於使用的工具。然而,隨著這些工具的普及和易用性的增加,研究人員有責任保持對這些模型能力與局限性的清醒認識。尤其是在某些任務上,由於LLM的出色表現和高度互動性,可能會讓人們誤以為它們始終是研究對象或自動化文本分析助手的最佳選擇。這些誤解可能會簡化人們對這些複雜工具的理解,並作出不明智的決定。例如為了方便或因為缺乏認識而避免必要的微調,從而未能充分利用其全部能力,最終得到相對較差的效果,或者忽視了與透明度和再現性相關的獨特挑戰。
我們還需要認識到,許多歸因於LLM的優勢在其他模型中也存在。例如,BERT或開源的LLM可以通過API訪問,為無法自我託管這些技術的研究人員提供了一個方便且低成本的選擇。這使得它們在無需大量編碼或技術專業知識的情況下也能被廣泛使用。此外,OpenAI還提供了嵌入模型,如「text-embedding-ada-3」,可以像BERT一樣用於下遊任務。
歸根結底,任何計算工具的負責任使用都需要我們全面理解其能力,並慎重考慮該工具是否為當前任務最適合的方法。這種平衡的做法能夠確保技術進步在研究中得到有效和負責任的利用。
參考文獻
[1] SINGHAL K, AZIZI S, TU T, et al. Large language models encode clinical knowledge [J]. Nature, 2023, 620(7972): 172-80.
[2] MOTOKI F, PINHO NETO V, RODRIGUES V. More human than human: measuring ChatGPT political bias [J]. Public Choice, 2024, 198(1): 3-23.
[3] WEBB T, HOLYOAK K J, LU H. Emergent analogical reasoning in large language models [J]. Nat Hum Behav, 2023, 7(9): 1526-41.
[4] DILLION D, TANDON N, GU Y, et al. Can AI language models replace human participants? [J]. Trends Cogn Sci, 2023, 27(7): 597-600.
[5] KOCOŃ J, CICHECKI I, KASZYCA O, et al. ChatGPT: Jack of all trades, master of none [J]. Information Fusion, 2023, 99: 101861.
[6] RATHJE S, MIREA D-M, SUCHOLUTSKY I, et al. GPT is an effective tool for multilingual psychological text analysis [Z]. PsyArXiv. 2023.10.31234/osf.io/sekf5