AI就是所有人瘋狂競爭,最後Google贏得比賽的遊戲?

作者|週一笑郵箱|zhouyixiao@pingwest.com
2016年,剛剛成為GoogleCEO幾個月後,桑達爾·皮查伊發表聲明稱Google將成為一家「AI優先」的公司,這一宣言背後,是Google對人工智能未來發展的戰略性押注。2017年,一群Google研究人員撰寫了一篇關於AI的開創性論文《Attention Is All You Need》,提出了一種新的網絡架構來分析文本,也就是後來成為了生成式AI技術基礎的Transformer。
然而,七年後的2022年底,ChatGPT橫空出世,Google被打了個措手不及。諷刺的是,Google早在兩年前就已宣佈了類似的技術LaMDA,卻未能將其及時推向市場。正如許多競爭對手所預料的,這個「房間里的大象」終於被迫醒來。面對突如其來的競爭壓力,皮查伊甚至請回了公司聯合創始人拉利·佩奇和謝爾蓋·比連來重新審視公司的AI戰略。
在ChatGPT推出後的幾個月,Google匆忙推出了自己的聊天機器人Bard(後改名為Gemini)。為了追趕對手的領先優勢,Google不斷為Gemini添加大量新功能,試圖彌補落後的局面。Gemini在過去也曾捲入爭議,去年不得不暫時下線其圖像生成功能,原因是這個聊天機器人生成了穿著納粹軍裝的黑人士兵圖像,同時又拒絕生成白人的圖像,這一功能直到六個月後才重新恢復。
經過幾年的努力,甚至重組了團隊結構,將Gemini應用團隊轉移到DeepMind部門,Google通過Gemini實現了反彈,將人工智能業務推向快車道,幾乎在所有方面都趕上了OpenAI。
值得注意的是,所有AI領域的大公司似乎都在朝著相同的方向發展,專注於相似的技術路線:開發AI Agent(能夠自主完成任務的AI系統)、深度搜索、更輕量的模型等等。這種趨同性可能意味著整個行業在某種程度上形成了共識,而Google正試圖在這個共識中脫穎而出。
Gemini的高頻實用更新:從圖像編輯到開源模型
就在蘋果承認那個所謂更智能的AI版Siri目前只是個空頭支票的同一時期,Gemini推出了數個驚豔的更新。Google的Gemini 2.0 Flash模型實現了讓用戶直接用自然語言來編輯圖片的功能,精確度和靈活性達到了很高的水平。此前備曾收到爭議的圖像功能,如今已成為Gemini的亮點之一。
用戶可以精確指導AI只修改圖像中想要改動的部分,還能在同一張圖上連續做多次精確修改而風格不會出現大的偏差,就像在給一位真實的設計師發需求一樣。雖然目前Gemini 2.0 Flash還不能做到100%的一致性和準確性,但它顯然為用戶提供了創造更有趣、有用內容的強大工具。
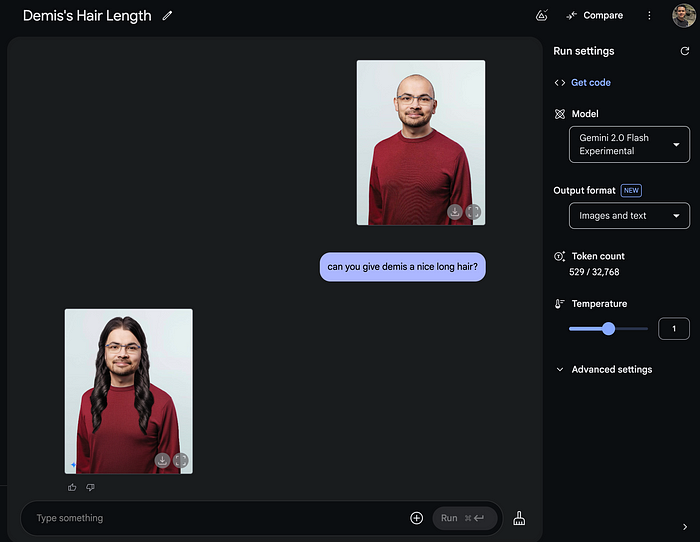
將Google DeepMind 的 CEO Demis Hassabis變成一個長髮男子
在開源方面,Google上週還推出了新的多模態模型Gemma 3,並對外開放了模型權重,允許在遵守規定的情況下用於商業用途。Google表示,Gemma 3的Elo評分達到了1338分,相當於DeepSeek R1模型(1363分)的98%。
但有個顯著區別:DeepSeek模型需要32張英偉達H100顯卡才能達到這個分數,而Gemma 3只需要一張H100就行。因此,Google宣稱Gemma 3是「能在單張GPU或TPU上運行的最強大模型」。
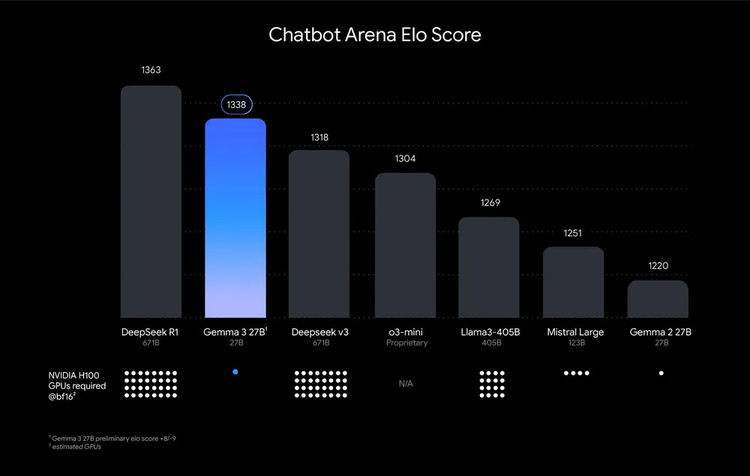
Gemma 3的上下文窗口從先前的8192個token擴展至128000,基於Gemini 2.0基礎架構的Gemma 3還是一款多模態模型,能夠處理文本、高解像度圖像以及影片。這些技術指標顯示了Google在AI基礎模型領域的持續突破。
搜索與AI的深度融合:個性化成為關鍵
顯然,Google在很多領域都能夠持續創新,比如Gemini,或者體驗一下Waymo無人駕駛汽車就知道了。現在的問題是,Google能在自己的核心產品和主營業務上進行創新嗎?微軟目前的AI戰略很大程度上依賴於與OpenAI的合作夥伴關係,而非完全自主創新,蘋果則在AI領域似乎完全迷失方向。
現在,Google一方面在搜索中加入了 Gemini 的 AI 功能,另一方面又在 Gemini中強化了搜索能力,直接切入 OpenAI試圖搶佔的交彙點。過去幾週Google發佈的一系列公告,許多都與搜索與AI語言模型的融合有關,看上去像是在追趕ChatGPT等廠商早已推出的AI搜索功能,但Google試圖達到更高水平。
犧牲一部分隱私,讓AI更瞭解你?Google最近上線了一項新的「實驗性功能」,用戶可以把搜索記錄共享給Gemini,來獲得更加個性化的搜索結果。為了保護隱私,只有Gemini個性化模型才會連接到搜索歷史記錄,且相關對話不會被用來改進Gemini,不會存儲在其他地方,並且會在60天內自動刪除。

有了這個功能,用戶可以向Gemini提一些基礎性問題,比如「我上週搜索的那家餐廳叫什麼名?」或者「我要去紐約了,能根據我的搜索歷史給我推薦餐廳嗎?」。
此外,Google去年底推出的率先推出的Deep Research功能,如今用戶無需訂閱也可以免費使用了。使用Deep Research時,根據用戶的指令,Gemini會先製定一個研究計劃,然後開始搜索網絡上與提問相關的信息,最終生成一份全面但易讀的報告。這一功能從最初基於成本較高的Gemini 1.5 Pro模型,現已升級到新的推理模型Gemini 2.0 Flash Thinking Experimental模型上。
從數字世界邁向物理世界:Gemini Robotics的野心
Google還在嘗試將Gemini應用於物理世界。DeepMind近期推出了兩個新的模型,旨在幫助機器人更好地執行物理世界的任務。第一個是視覺-語言-動作模型Gemini Robotics,讓機器人即使沒有接受過相關訓練,也能夠理解新情況。
Gemini Robotics基於Gemini 2.0構建,結合了Gemini的多模態理解能力,並加入了物理動作作為新的模態。DeepMind在演示影片中展示了搭載Gemini Robotics的機器人,這些機器人能聽懂人說的指令並做出相應動作:機械臂能摺紙、遞蔬菜、小心地把眼鏡放進盒子裡,還能完成其他各種任務。

DeepMind還推出了Gemini Robotics-ER(具身推理),一種先進的視覺語言模型,能夠理解複雜且動態的世界。簡單來說,這個系統是給機器人開發者用的,目的是讓其他機器人研究人員利用此模型來訓練他們自己的模型,以控制機器人的動作。
Gemini Robotics揭示了GoogleDeepMind眼中AI的發展方向。一些研究人員認為,AI要想達到或超越人類能力,可能需要某種形式的「具身性」,簡單說就是讓AI能在真實世界中感知和行動。而Google似乎已經走在了這條路上。
Google的核心優勢:生態、資源與底蘊
Google追趕OpenAI的表現目前為止還不錯,Gemini 2.0 Pro和Flash模型確實很出色。深度研究功能做得相當好,上下文窗口大小在業界仍然是領先的,與搜索、Gmail、Google辦公套件、Google Meet、Android等的整合也在進行中。
Google還把推理模型整合到了更多日常應用中,包括日曆、筆記、任務和照片。這使得Gemini可以執行更為複雜的任務,比如Google舉例的:「在YouTube上找一個簡單的餅乾食譜,把配料添加到我的購物清單中,然後幫我找附近還開門的雜貨店。」未來,Gemini還能增強對用戶照片的理解能力,幫助用戶在需要時提取信息,例如整理過去旅行的行程,或提醒證件到期等。
有了足夠優秀的基座模型,這讓Google能夠充分利用自己現有的產品組合、雲基礎設施以及他們在現代工作生活中的深度嵌入優勢。Google還擁有數十億用戶和充足的資金實力,可以利用自己的現有用戶基礎,以OpenAI們無法企及的方式發揮優勢。

皮查伊曾在公司年終戰略會議表示:「縱觀歷史,你不一定要成為第一個,但你必須有良好的執行力,真正打造出同類最佳的產品。我認為這就是2025年的關鍵所在。」他希望到2025年底有5億人使用Gemini,此外還有Project Astra這樣的通用Agent項目在醞釀當中。
Google本來有潛力成為像ChatGPT這樣的對話式AI的市場領導者,但當時沒能把握住這個機會。現在,現在Google所能做的就是繼續推進這項服務,吸引更多用戶來使用。
各個科技公司正不斷推出新的應用場景和能力。儘管最初被OpenAI刺激而被動反應,但憑藉深厚的技術積累和廣泛的用戶基礎,Google正逐漸重新確立其在AI領域的領導地位。在這場AI競賽中,Google用Gemini的亮眼表現證明了自己依然是絕對的主力選手,而且底子依然足夠厚,正在展示出贏得這場比賽的實力和決心。