中科大提出動作價值表徵學習新方法,率先填補長期決策信息的缺失
ROUSER團隊 投稿
量子位 | 公眾號 QbitAI
在視覺強化學習中,許多方法未考慮序列決策過程,導致所學表徵缺乏關鍵的長期信息的空缺被填補上了。
來自中科大的研究人員在信息瓶頸(Information Bottleneck)框架下,提出了一種新穎的魯棒動作價值表徵學習方法ROUSER。
作者從理論上證明了ROUSER能夠使用學習到的魯棒表徵準確估計動作價值,從而避免了智能體在測試環境中的決策能力遭到削弱。

具體而言,ROUSER通過最大化表徵與動作價值之間的互信息,來保留長期信息;
同時,最小化表徵與狀態-動作對之間的互信息,以濾除無關特徵。
由於動作價值是未知的,ROUSER提出將狀態-動作對的魯棒表徵分解為單步獎勵和下一狀態-動作對的魯棒表徵。
實驗結果表明,在包括背景干擾與顏色干擾的12項任務中,ROUSER於其中的11項任務上優於多種當前的先進方法。
傳統方法難以捕捉關鍵長期信息
視覺強化學習中的泛化問題近年來受到了廣泛關注,其研究潛力在於使智能體具備處理現實複雜任務的能力,並能在多樣化環境中表現良好。
這裏的泛化能力是指智能體能夠將其學到的策略直接應用於未知環境,即使這些環境中存在與訓練階段不同的視覺干擾(如動態背景或可控物體顏色變化)。
因此,具備良好泛化能力的智能體可以在面臨未見干擾的環境時依然保持高性能執行任務,無需大量的重新訓練。
儘管現有方法以數據增廣、對比學習等技術增強了智能體面向環境視覺干擾的魯棒性,但值得注意的是,這類研究往往僅聚焦於如何從視覺圖像中提取魯棒的、不隨環境變化的信息,忽略了下遊關鍵的決策過程。
這導致這些方法難以捕捉序列數據中關鍵的長期信息,而這正是視覺強化學習泛化能力的核心因素之一。
為了針對性地解決這類問題,作者在信息瓶頸(Information Bottleneck)框架下,提出了魯棒動作價值表徵學習方法(ROUSER),通過引入信息瓶頸來學習能有效捕捉決策目標中長期信息的向量化表徵。
分解狀態-動作對魯棒表徵
本文提出的ROUSER主要包括兩個核心思路:
一是為了學習能有效捕捉決策目標中長期信息的向量化表徵,ROUSER基於信息瓶頸框架,通過最大化表徵與動作價值之間的互信息,來保留長期信息;
同時,最小化表徵與狀態-動作對之間的互信息,以濾除無關特徵。
二是由於動作價值是未知的,無法直接最大化表徵與動作價值之間的互信息,因此ROUSER提出將狀態-動作對的魯棒表徵分解為僅包含單步獎勵信息的表徵和下一狀態-動作對的魯棒表徵。
這樣一來,可以借助已知的單步獎勵,計算用於魯棒表徵學習的損失函數。
方法架構圖如下所示:
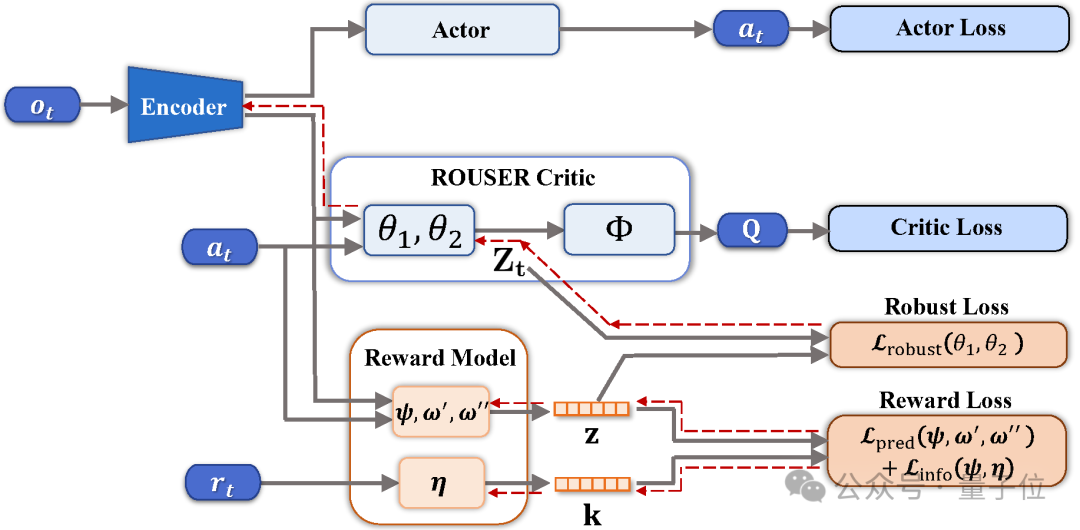
為實現上述思路,ROUSER主要包括兩個核心模塊——獎勵模型(Reward Model)和魯棒損失(Robust Loss)。
其中獎勵模型旨在學習僅包含單步獎勵信息的表徵。
具體來說,獎勵模型基於信息瓶頸框架,最大化從狀態-動作對中提取的獎勵表徵與單步獎勵之間的互信息,同時最小化獎勵表徵與對應狀態-動作對之間的互信息,從而引導模型學習僅包含獎勵信息的表徵。
魯棒損失則旨在構建可計算的損失函數,學習能有效捕捉決策目標中長期信息的向量化表徵。
基於對狀態-動作對的魯棒表徵分解技術,構建遞歸式損失函數,僅利用獎勵模型編碼的表徵即可直接計算該損失。
且該部分僅為損失函數的構建,並沒有更改強化學習中批評家(Critic)模型的架構。最終旨在學習的向量化表徵為批評家模型的中間層嵌入(Embedding)。
本文理論證明了ROUSER能夠利用學習到的向量化表徵準確估計決策目標,即動作價值。
基於這一理論結果,ROUSER能有效結合各類連續和離散控制的視覺強化學習算法,以提升其對動作價值估計的準確性,從而提升整體魯棒性。
實驗結果
在視覺強化學習泛化性研究的12個連續控制任務中,ROUSER於11個任務上取得了最優性能。
其中下圖的6個任務是智能體面向物體動態顏色變化干擾的泛化性能。
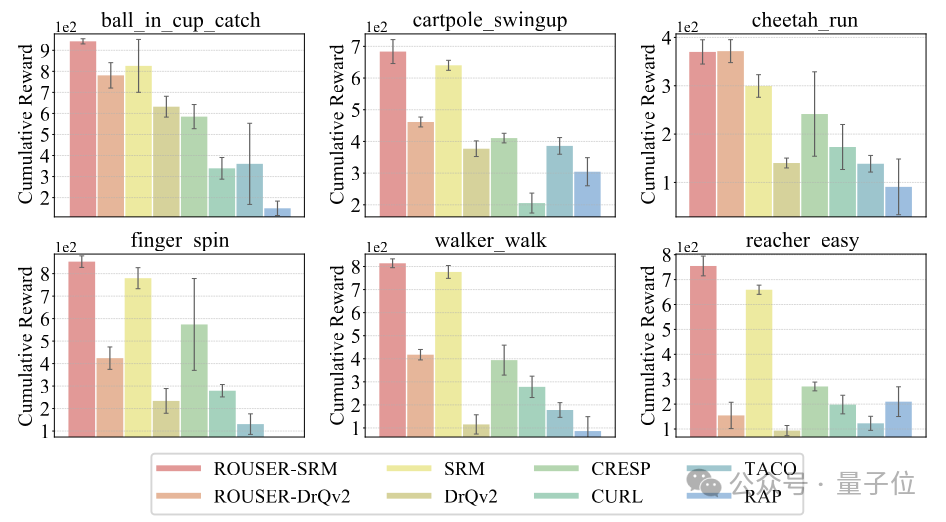
下圖的6個任務展示了智能體面向背景干擾的泛化性能。
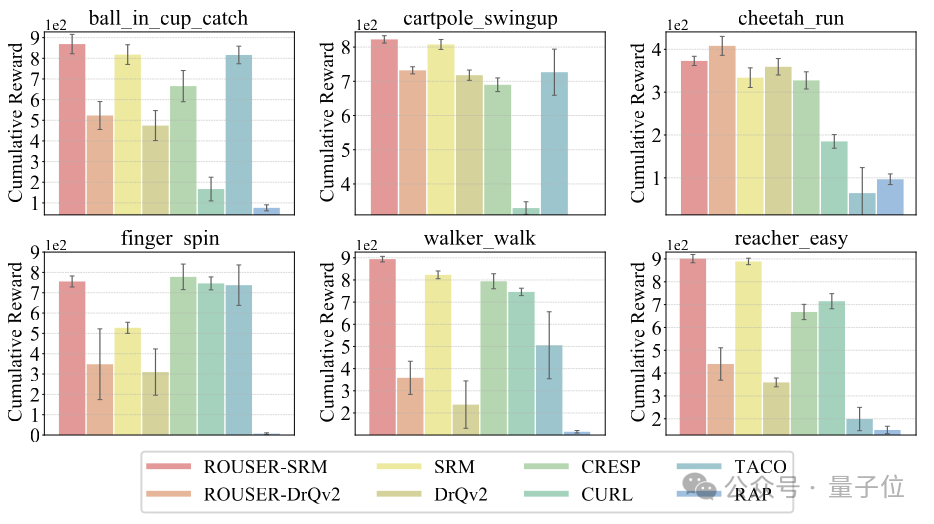
ROUSER方法的一大特點是可以兼容離散控制任務,本文在Procgen環境中進行了相關實驗。
如下表所示,當ROUSER與基於價值的VRL方法結合應用於非連續控制任務時,也能夠提升智能體的泛化性能。




















