飛槳新一代框架 3.0 正式發佈:減少 Llama 預訓練 80% 分佈式核心代碼,R1 滿血版單機部署吞吐量翻倍

作者 | 褚杏娟
4 月 1 日,飛槳框架迎來重大更新,官方發佈了飛槳框架 3.0 正式版。
據介紹,飛槳框架 3.0 版本不僅延續了飛槳框架 2.0 系列動靜統一、訓推一體的特性,更在自動並行、神經網絡編譯器、高階自動微分等方面取得突破。飛槳框架 3.0 具備以下五大新特性:
-
動靜統一自動並行:通過少量的張量切分標記,即可自動完成分佈式切分信息的推導,Llama 預訓練場景減少 80% 的分佈式相關代碼開發。
-
大模型訓推一體:依託高擴展性的中間表示(PIR)從模型壓縮、推理計算、服務部署、多硬件推理全方位深度優化,支持文心 4.5、文心 X1 等多款主流大模型,DeepSeek-R1 滿血版單機部署吞吐提升一倍。
-
科學計算高階微分:通過高階自動微分和神經網絡編譯器技術,微分方程求解速度比 PyTorch 快 115%。
-
神經網絡編譯器:通過自動算子自動融合技術,無需手寫 CUDA 等底層代碼,部分算子執行速度提升 4 倍,模型端到端訓練速度提升 27.4%。
-
異構多芯適配:通過對硬件接入模塊進行抽像,降低異構芯片與框架適配的複雜度,兼容硬件差異,初次跑通所需適配接口數比 PyTorch 減少 56%,代碼量減少 80%。
飛槳框架 3.0 旨在開為發者提供一個「動靜統一、訓推一體、自動並行、自動優化、廣泛硬件適配」的深度學習框架,像寫單機代碼一樣寫分佈式代碼,無需感知複雜的通信和調度邏輯,即可實現大模型的開發;像寫數學公式一樣用 Python 語言寫神經網絡,無需使用硬件開發語言編寫複雜的算子內核代碼即可實現高效運行。目前 3.0 正式版本已面向開發者開放,並且兼容 2.0 版本的開發接口。
據悉,飛槳框架 3.0 在訓練、推理等方面為文心大模型提供端到端優化,訓練方面重點提升訓練吞吐、訓練有效率和收斂效率,集群訓練有效率超過 98%;推理部署方面通過注意力機制量化推理、通用投機解碼等技術提升推理吞吐和效率;全面支持文心 4.5、文心 X1 等大模型的技術創新和產業應用。
飛槳 3.0 提供了深度學習相關的各種開發接口;表示層專注於計算圖的表達與轉換,通過高可擴展中間表示 PIR,實現動轉靜、自動微分、自動並行、算子組合以及計算圖優化等核心功能;調度層負責對代碼或計算圖進行智能編排與高效調度,支持動態圖和靜態圖兩種不同的執行模式;算子層由神經網絡編譯器 CINN 和算子庫 PHI 共同構成,涵蓋了張量定義、算子定義、算子自動融合和算子內核實現等關鍵功能;適配層則用於實現與底層芯片適配,包括設備管理、算子適配、通信適配以及編譯接入等功能。
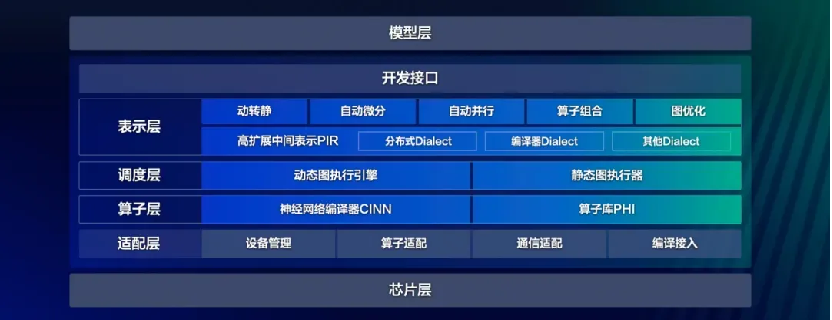 飛槳框架 3.0 架構圖
飛槳框架 3.0 架構圖飛槳框架 3.0 的此次發佈主要針對當前算法工程師和科研人員在使用現有深度學習框架進行算法創新時面臨的諸多挑戰。
全面支持自動並行訓練
傳統的單機單卡訓練已無法滿足需求,分佈式並行訓練成為加速大模型迭代的關鍵。然而分佈式訓練需使用複雜的並行策略,包括數據並行、張量並行、參數分片並行、流水線並行、序列並行、專家並行等,如何實現多種並行策略的高效協同已成為關鍵瓶頸。
當前,無論是動態圖還是靜態圖,市場上的並行訓練框架普遍存在使用成本高的問題。開發者既要熟知模型結構,還要深入瞭解並行策略和框架調度邏輯,使得大模型的開發和性能優化門檻非常高,製約了大模型的開發和訓練效率。為此,飛槳提出了動靜統一自動並行方案,具體工作流程如下圖所示:

動靜統一自動並行流程圖
據介紹,該技術通過原生動態圖的編程界面與自動並行能力,同時保障靈活性和易用性,大幅降低大模型並行訓練的開發成本;同時利用框架動靜統一的優勢,一鍵轉靜使用靜態優化能力,提供極致的大模型並行訓練性能。開發者僅需少量的張量切分標記,框架便能自動推導出所有張量和算子的分佈式切分狀態,並添加合適的通信算子,保證結果正確性。
飛槳自動並行功能允許用戶僅需借助少量 API 調用,即可將算法轉換為並行訓練程序。以 Llama2 的預訓練為例,傳統實現方式需要開發者精細調整通信策略,以確保正確高效執行,而自動並行實現方式相比傳統方式減少 80% 的分佈式核心代碼。
據悉,基於飛槳大模型開髮套件(PaddleNLP、PaddleMIX),飛槳框架已全面驗證 Llama、QwenVL 等從大語言模型到多模態模型的預訓練、精調階段的自動並行訓練。此外,飛槳協同文心實現了精細化重計算、稀疏注意力計算優化、靈活批次的流水線均衡優化等,這些優化技術在飛槳框架 3.0 中開源。
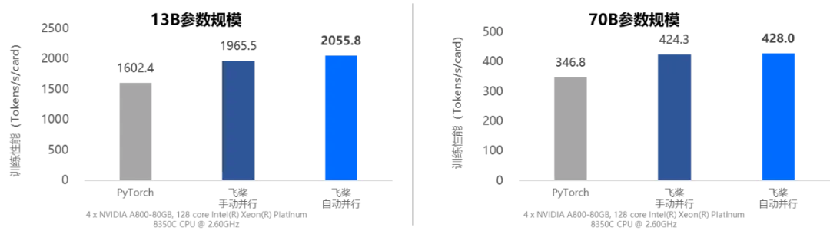 動靜統一自動並行訓練速度對比
動靜統一自動並行訓練速度對比大模型訓推一體
飛槳框架 3.0 繼續採用「動靜統一、訓推一體」的設計理念,並在大模型場景下持續優化。
在推理部署方面,相較於動態圖,靜態圖部署範圍更為廣泛,能夠通過整圖導出的方式,擺脫對 Python 源代碼和執行環境的依賴,而且更適合進行全局調優,可通過手寫或者借助編譯器自動實現算子融合等方式來加速推理過程。
據悉,得益於動靜統一的架構和接口設計,飛槳能夠完整支持動態圖和靜態圖這兩種不同的運行模式,並且具備出色的整圖導出能力。飛槳的動轉靜整圖導出成功率高達 95%,高於 PyTorch 62%。
「訓推一體」意味著能夠在同一套框架下,儘可能複用訓練和推理的代碼,特別是複用模型組網代碼。與業界當前先使用 PyTorch 和 DeepSpeed 進行訓練,再採用 vLLM、SGLang、ONNXRuntime 等推理引擎進行推理部署的方案相比,飛槳採用訓練和推理使用同一套框架的方式可以避免不同框架之間可能出現的版本兼容性問題,以及因模型結構變化、中間表示差異、算子實現差異等帶來的問題。
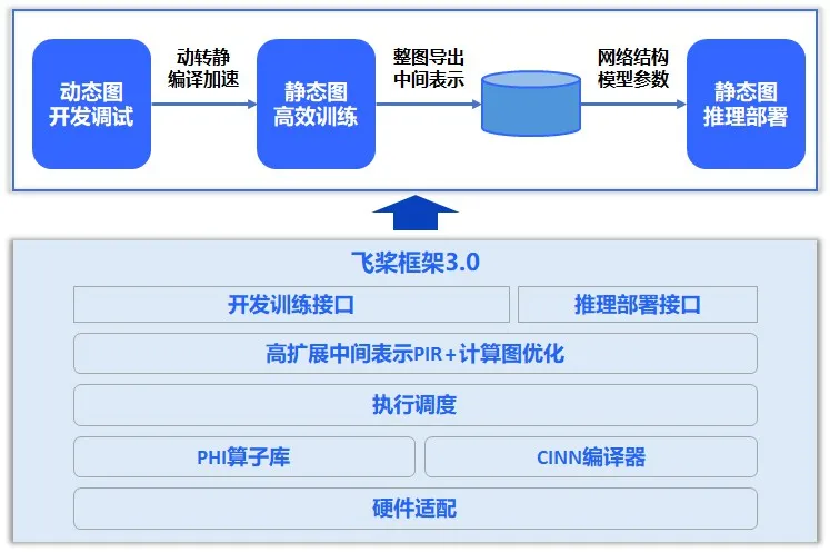 飛槳訓推一體架構設計
飛槳訓推一體架構設計據悉,飛槳框架 3.0 支持了 DeepSeek V3/R1 滿血版及其系列蒸餾版模型的 FP8 推理,並且提供 INT8 量化功能,破除了 Hopper 架構的限制。此外,還引入了 4 比特量化推理,使得用戶可以單機部署,降低成本的同時顯著提升系統吞吐一倍,提供了更為高效、經濟的部署方案。
在性能優化方面,飛槳對 MLA 算子進行多級流水線編排、精細的寄存器及共享內存分配優化,性能相比 FlashMLA 最高可提升 23%。綜合 FP8 矩陣計算調優及動態量化算子優化等基於飛槳框架 3.0 的 DeepSeek R1 FP8 推理,單機每秒輸出 token 數超 1000;若採用 4 比特單機部署方案,每秒輸出 token 數可達 2000 以上,推理性能顯著領先其他開源方案。
此外,飛槳框架 3.0 還支持了 MTP 投機解碼,突破大批次推理加速,在解碼速度保持不變的情況下,吞吐提升 144%;吞吐接近的情況下,解碼速度提升 42%。針對長序列 Prefill 階段,通過注意力計算動態量化,首 token 推理速度提升 37%。
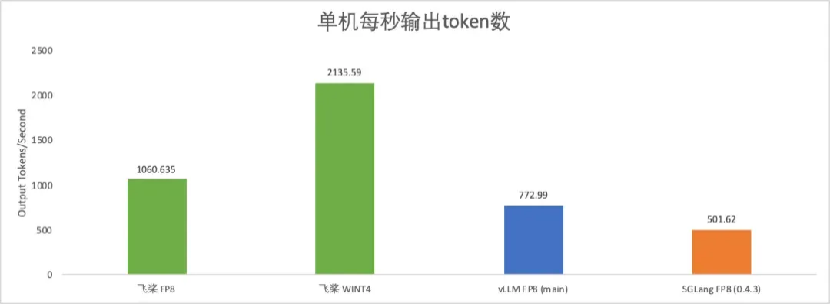 DeepSeek 模型單機推理速度對比(H800 上 256 併發不含 MTP 測試)
DeepSeek 模型單機推理速度對比(H800 上 256 併發不含 MTP 測試)助力科學前沿探索
科學智能(AI for Science)為解決科學問題帶來新方法的同時,也需要深度學習框架能夠具備更加豐富的各類計算表達能力,如高階自動微分、傅里葉變換、複數運算、高階優化器等,還要實現深度學習框架與傳統科學計算工具鏈的協同。
為此,飛槳框架 3.0 提出了基於組合算子的高階自動微分技術,如下圖所示。該技術的核心思想是將複雜算子(如 log_softmax)拆解為多個基礎算子的組合,然後對這些基礎算子進行一階自動微分變換。重要的是,基礎算子經過一階自動微分變換後,其所得的計算圖仍然由基礎算子構成。通過反復應用一階自動微分規則,可以輕鬆獲得高階自動微分的結果。
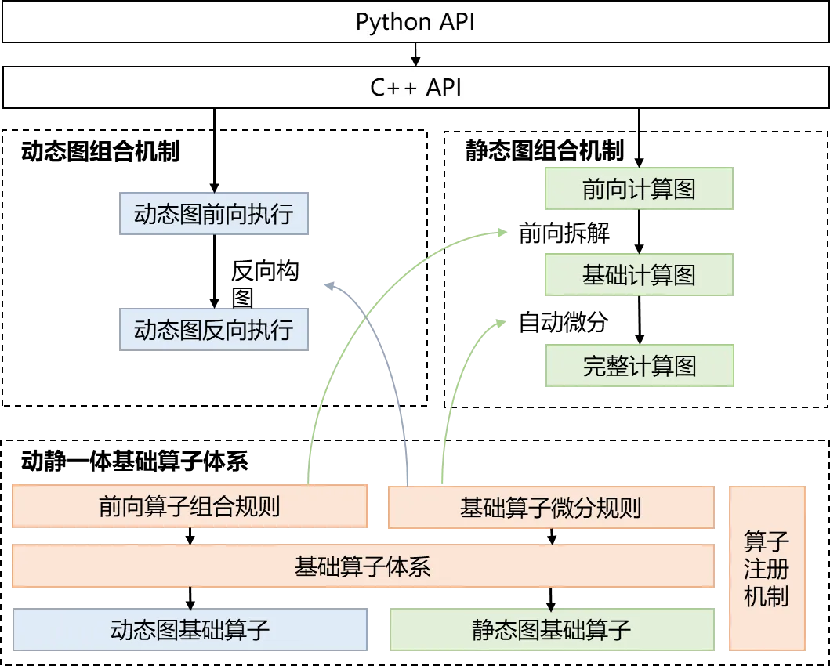 基於組合算子的高階自動微分技術
基於組合算子的高階自動微分技術據悉,英偉達 Modulus 的 41 個不同方程實驗顯示,飛槳的微分方程求解速度比 PyTorch 開啟編譯器優化後的 2.6 版本平均快 115%。此外,飛槳還實現了傅里葉變換、複數運算、高階優化器等功能,這些方法在航空航天、汽車船舶、氣象海洋、生命科學等多個領域都具有廣泛的應用潛力。
在模型層面,團隊研發了賽槳(PaddleScience)、螺旋槳(PaddleHelix)等系列開髮套件,並對 DeepXDE、Modulus 等主流開源科學計算工具進行了廣泛適配。
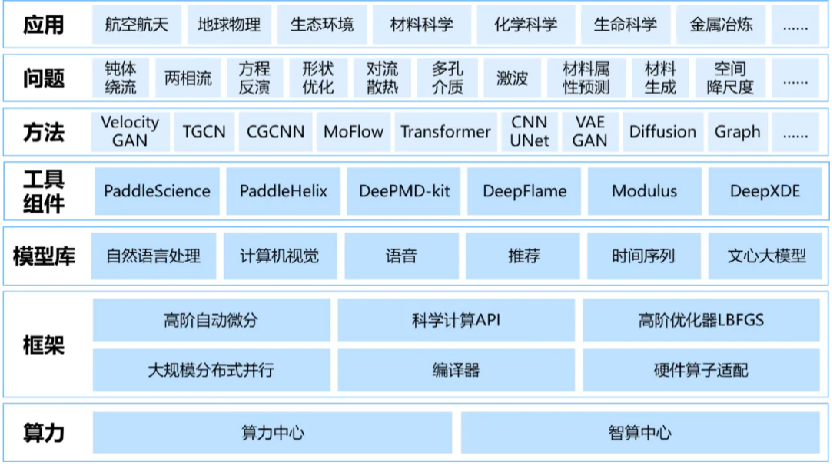 飛槳 AI for Science 全景圖
飛槳 AI for Science 全景圖神經網絡編譯器技術
眾多深度學習的應用場景,如大模型訓練、自動駕駛等,對模型的訓練與推理速度均提出了極高的要求。
在模型結構層面,模型結構正日益呈現出多樣化的趨勢,從基礎的全連接網絡,到複雜的卷積神經網絡、循環神經網絡、Attention 網絡、狀態空間模型、圖神經網絡等,每一種模型結構都擁有其獨特的計算模式與優化需求。
在硬件特性方面,算力的增長速度遠遠超過了訪存性能的提升,訪存性能的瓶頸限制了訪存密集型算子(如歸一化層、激活函數等)的執行效率。特別是,當前市場上硬件平台種類繁多,需要投入大量的人力物力進行針對性的優化工作,這將嚴重拖慢算法創新和產業應用的速度。
以 Llama 模型中經常使用的 RMS Normalization(Root Mean Square Layer Normalization)為例,其計算公式相對簡單明了:
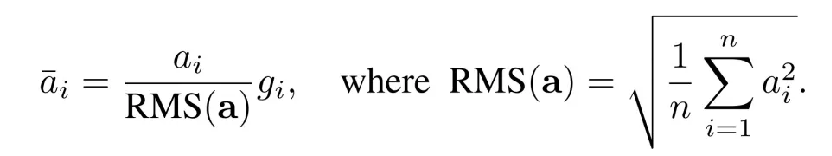
假設需要實現 RMS Normalization 的計算,簡單方法是可以使用飛槳框架提供的張量運算開發接口,調用平方、求和、除法、開根號等操作來完成:

上述代碼開發簡單,但是由於存在大量的訪存操作導致性能很差,且顯存佔比較多。為了突破訪存瓶頸,開發者可以選擇通過手寫 CUDA 代碼的方式實現一個融合的 FusedRMSNorm 算子,但是對於開發者要求更高、開發成本也更高,更重要的是這種方式極大降低了可維護性和靈活性。
為此,飛槳框架 3.0 研製了神經網絡編譯器 CINN(Compiler Infrastructure for Neural Networks),相比於 PyTorch 2.0 的 Inductor 加 Triton 的兩階段編譯方案,CINN 支持直接從神經網絡中間表述編譯生成 CUDA C 代碼,通過一階段的編譯方案,CINN 避免了兩階段編譯由於中間表示信息傳遞和表達能力限制所造成的信息損失,具備更通用的融合能力和更好的性能表現。主要特點如下:
以 Reduce 為核心的算子融合技術。摒棄傳統的粗粒度 pattern 匹配模式,支持維度軸自動變換對齊融合,在保證計算正確性的同時,具有更強的算子融合能力,帶來更大的性能優化潛力。動靜態維度的高效後端 Kernel 調優技術。算子全面支持 reduce、broadcast、transpose 等多種算子的不同組合方式,針對各類算子組合和數據類型,自適應不同維度大小與不同硬件配置,進行全場景高效調優。通過自動向量化提高 BF16、FP16 等小數據類型的訪存效率。通過分析與分桶機制,實現動靜態運行時配置生成,根據運行時的硬件配置,在無需 profiling 的情況下生成高效的 kernel。動態維度的複雜表達式化簡技術。建立了分層化簡體系,Lower、Schedule、CodeGen 階段執行不同等級化簡方法,解決傳統化簡方法中多場景疊加後化簡困難、化簡不徹底問題。實現了複雜表達式結構化簡,抽取融合算子經過編譯、調優後的固定子結構進行專項化簡,且靈活支持自定義化簡方法。
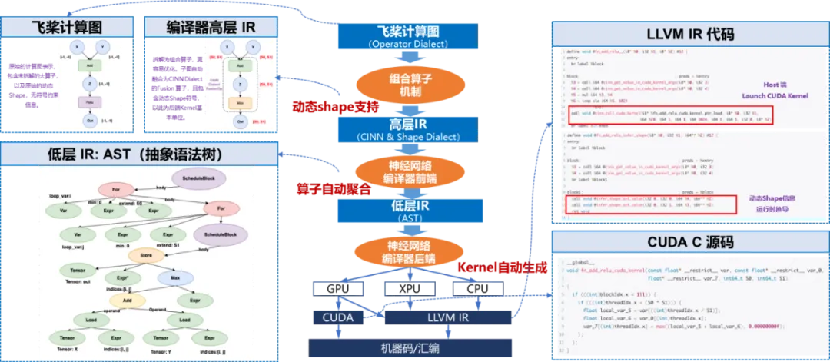 神經網絡編譯器 CINN 流程圖
神經網絡編譯器 CINN 流程圖以下為 A100 平台上 RMSNorm 算子的性能測試結果:相較於採用 Python 開發接口組合實現的方式,經過編譯優化後的算子運行速度提升了 4 倍;即便與手動算子融合的方式相比,也實現了 14% 的性能提升,在靈活性與高性能之間尋找到了較為理想平衡點。飛獎團隊在 PaddleX 開髮套件里選取了超過 60 模型進行實驗,使用 CINN 編譯器後超 60% 模型有顯著性能提升,平均提升達 27.4%。重點模型相比 PyTorch 開啟編譯優化後的版本平均快 18.4%。
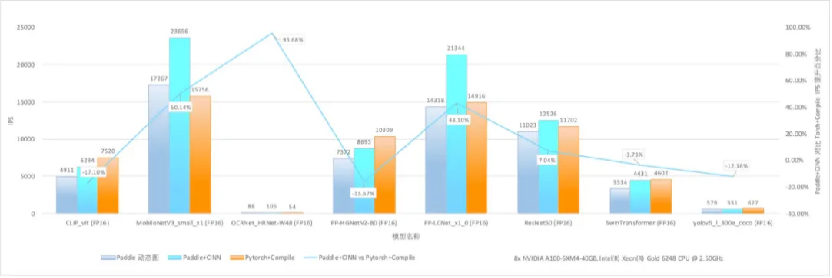 神經網絡編譯器 CINN 訓練速度對比
神經網絡編譯器 CINN 訓練速度對比標準化統一硬件適配
在深度學習的創新探索與產業落地進程中,單一芯片往往難以滿足複雜多變的業務需求,因此通常需要融合運用多種芯片來構建解決方案。
飛槳框架 3.0 版本聚焦於硬件接口的抽像。飛槳將硬件接口細分為設備管理、計算執行、分佈式通信等多個類別,通過標準化的硬件接口成功屏蔽了不同芯片軟件棧開發接口之間的差異。通過合理的抽像,減少了適配所需的接口數量,以昇騰芯片適配為例,初步跑通所需適配接口數比 PyTorch 方案減少 56%,適配代碼量減少 80%。
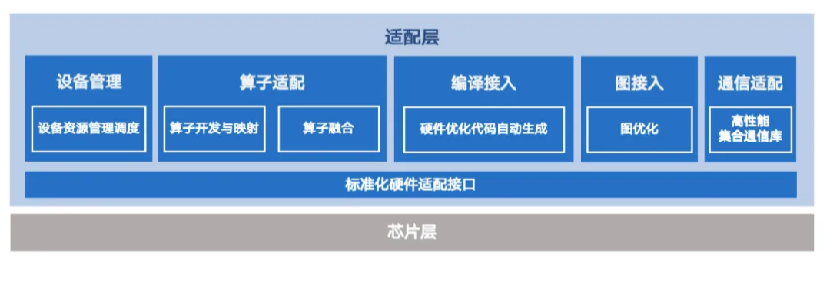 多硬件統一適配方案
多硬件統一適配方案基於標準化適配接口的定義,飛槳實現了鬆耦合、可插拔的架構,每類芯片僅需提供標準化適配接口的具體實現,便能融入飛槳後端。考慮到不同芯片軟件棧成熟度的差異,飛槳提供涵蓋算子開發、算子映射、圖接入、編譯器接入等方式。針對大模型訓練與推理需求,飛槳支持動靜統一編程範式、超大規模分佈式訓練技術等。據悉,基於前述技術,飛槳已經適配 60 多個芯片系列。