OpenAI發佈GPT-4.1系列模型,超越前輩4o,但未超越競爭對手
GPT-4.1 來了。
香港時間4 月 15 號淩晨,OpenAI 直播發佈了名為 GPT-4.1 的多模態系列模型。
它有三個版本:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。其中 mini 和 nano 的效率更高、速度更快、成本更低,但犧牲了準確性。
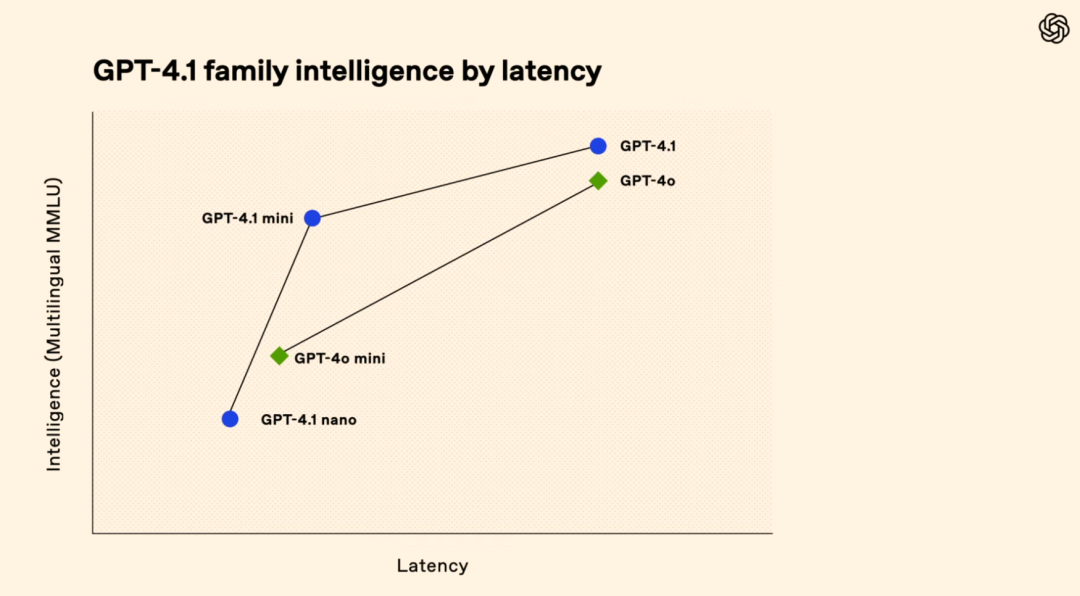
圖
| GPT-4.1 與 GPT-4o 系列對比(來源:OpenAI)
OpenAI 表示,「它們編碼和指令遵循方面取得了重大進展。完整的GPT-4.1 模型在幾乎所有維度上均優於 GPT-4o 系列模型。」
僅從基準測試成績來看,GPT-4.1 的紙面性能雖然比自家前輩有所提升,但如果跟Google、Anthropic 等競爭對手的旗艦模型相比,還是有一定的差距。
看來想要完全超越競爭對手,OpenAI 只能盡快拿出 o3 完全體了。
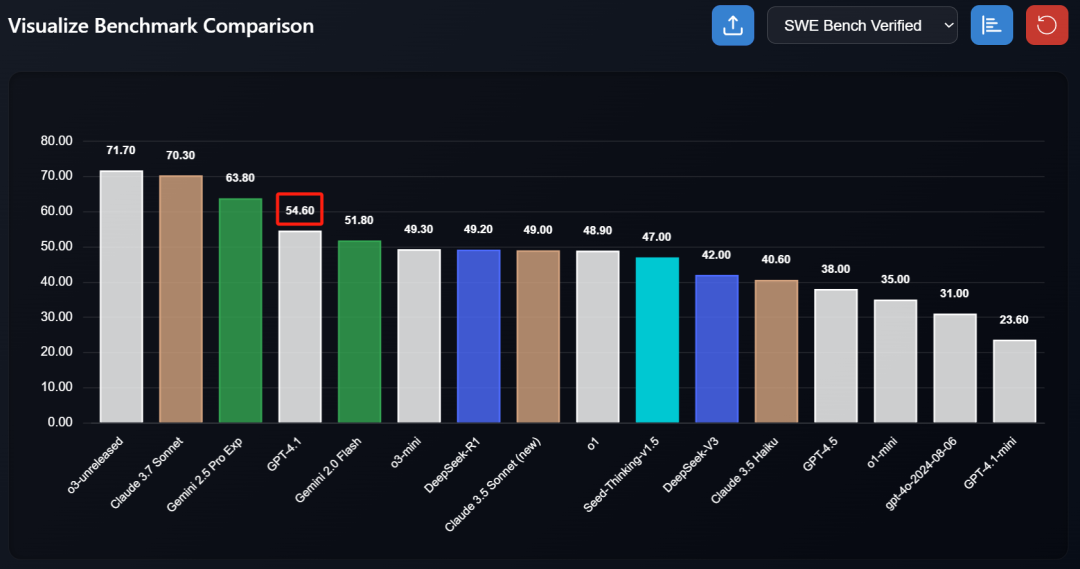
圖
| GPT-4.1 與其他模型的 SWE Bench Verified 成績對比(來源:evalarena.ai)
值得注意的是,GPT-4.1 系列模型目前只能通過 OpenAI 的 API 獲取,無法在 ChatGPT 上使用。
與此同時OpenAI 還宣佈,將很快停止通過 API 提供其有史以來最大的 AI 模型 GPT-4.5。該模型是今年 2 月剛剛發佈的,其運行成本十分昂貴,API 定價也高達每百萬輸入 75 美元,每百萬輸出 150 美元。
今年7 月 14 日之後,API 開發者必須將 GPT-4.5 服務轉移到 OpenAI 的其他模型,首選替代方案是 GPT-4.1。這暫時不會影響通過 ChatGPT 使用 GPT-4.5。
GPT-4.1 系列模型的上下文窗口提高到了 100 萬 token(包含文本、圖像或影片的組合),這意味著它們可以一次性輸入大約 75 萬個單詞。此前的 GPT-4o 最多支持 12.8 萬 token。
但OpenAI 也承認,GPT-4.1 處理的輸入 token 越多,可靠性就越低,更容易出錯。
在該公司自己的測試OpenAI-MRCR 中,隨著 token 的數量從 8000 增長到 100 萬,模型的準確率從 84% 左右下降到了不足 50%。該公司表示,GPT-4.1 也比 GPT-4o 更「直接」,有時需要更具體、更明確的提示。

圖
| GPT-4.1 系列模型定價(來源:OpenAI)
定價方面,GPT-4.1 每百萬輸入 token 成本為 2 美元,每百萬輸出 token 成本為 8 美元。GPT-4.1 mini 每百萬輸入 token 成本為 0.4 美元,每百萬輸出 token 成本為 1.6 美元;GPT-4.1 nano 每百萬輸入 token 成本為 0.1 美元,每百萬輸出 token 成本為 0.4 美元。
綜合來看,GPT-4.1 的成本比 GPT-4o 低 26%。同時,OpenAI 還將新模型的即時緩存摺扣輸入提高到了 75%(之前為 50%)。
性能方面,GPT-4.1 可以一次性生成比 GPT-4o 更多的 token(最多 32768 個 token),在最受程序員關心的 SWE-bench Verified 上的得分在 52% 到 54.6% 之間。這個成績低於Google Gemini 2.5 Pro 的 63.8% 和 Anthropic Claude 3.7 Sonnet 的 62.3%。
對於需要編輯大型文件的API 開發者來說,GPT-4.1 在跨多種格式的代碼差異分析方面更加可靠。在 Aider 的多語言差異基準測試中,GPT-4.1 的得分是 GPT-4o 的兩倍多,甚至比 GPT-4.5 還高出 8%。
「我們專門訓練了GPT-4.1,使其能夠更可靠地遵循差異格式,這使得開發人員只需讓模型輸出更改的行,而無需重寫整個文件,從而節省成本和延遲。」OpenAI 寫道。
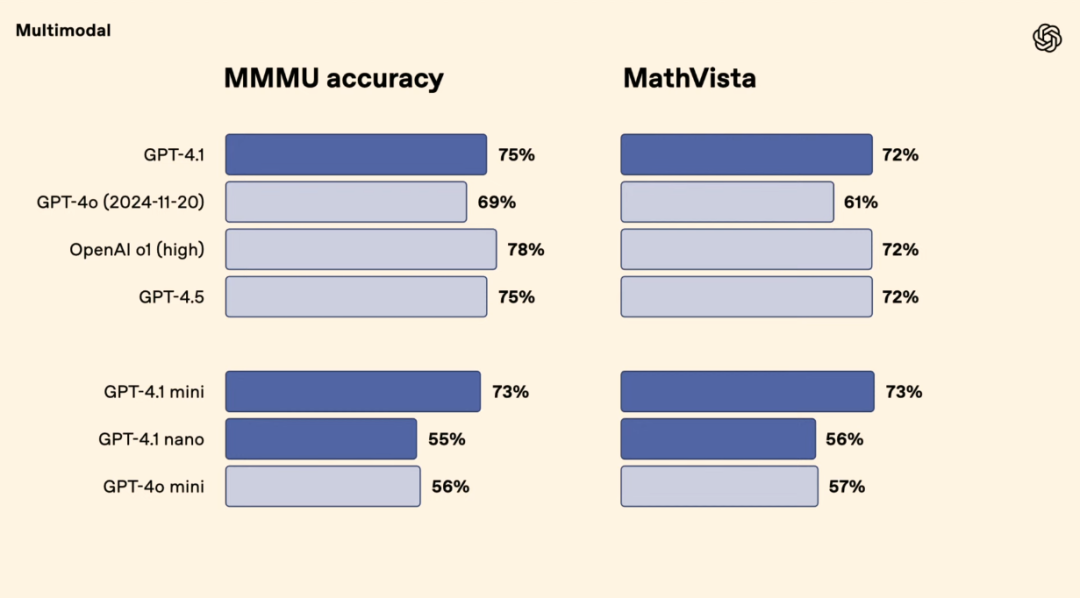
圖
| 多模態性能對比(來源:OpenAI)
這一點在指令遵循上也有所體現。
OpenAI 在博客中介紹稱,GPT-4.1 能更可靠地遵循指令,並且「已經在各種指令遵循評估中測量到了顯著的改進」。
OpenAI 開發了一個內部教學跟蹤評估系統,以跟蹤模型在多個維度和幾個關鍵教學跟蹤類別中的表現,包括格式遵循、避免負面指示、有序遵循指令、遵守內容要求、排序和過度自信。
這些類別是根據開發人員的反饋得出的,這些反饋是關於哪些指令遵循方面對他們來說最相關且最重要。在每個類別中,OpenAI 將其分為簡單、中等和困難提示。GPT-4.1 在困難提示方面的表現尤其優於 GPT-4o。
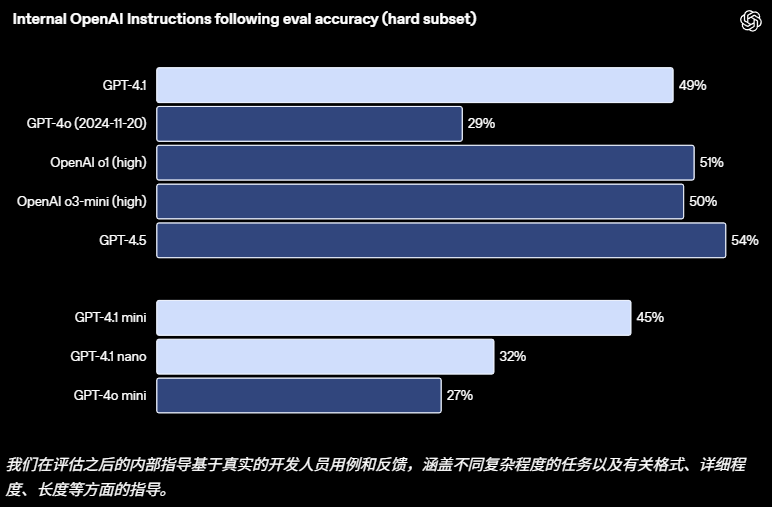
圖
| OpenAI 內部指令遵循測試結果(來源:OpenAI)
多輪指令遵循對許多開發者來說至關重要。對於模型而言,在對話中保持連貫性並跟蹤用戶之前輸入的內容至關重要。
「我們已經訓練了GPT-4.1,使其能夠更好地從對話中的過往消息中識別信息,從而實現更自然的對話。Scale 的 MultiChallenge 基準測試是衡量這一能力的有效指標,GPT-4.1 的表現比 GPT-4o 提高了 10.5%。」OpenAI 表示。
GPT-4.1 在前端編碼方面也比 GPT-4o 有了顯著提升,能夠創建功能更強大、更美觀的 Web 應用。在 OpenAI 的評估中,相比 GPT-4o,測試人員更喜歡 GPT-4.1 創建的網站。
在另一項評估中,OpenAI 使用 Video-MME 測試了 GPT-4.1,該模型旨在衡量模型「理解」影片內容的能力。
OpenAI 聲稱,GPT-4.1 在「長篇無字幕」影片類別中達到了72% 的最高準確率,高於 GPT-4o 的 65.3%。
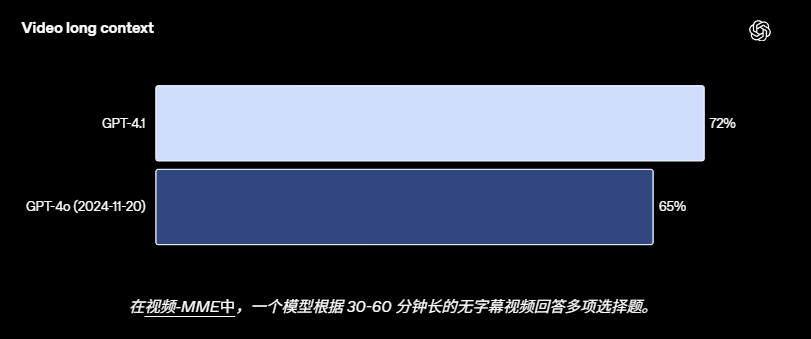
圖
| 影片長內容測試成績(來源:OpenAI)
在衡量真實世界軟件工程技能的SWE-bench Verified 測試中,GPT-4.1 完成了 54.6% 的任務,而 GPT-4o(2024-11-20)的完成率為 33.2%。這反映了模型在探索代碼庫、完成任務以及生成可運行並通過測試的代碼方面的能力有所提升。
OpenAI 還表示,除了上述基準測試之外,GPT-4.1 在遵循代碼格式方面表現更佳,可靠性更高,並且減少了無關編輯的頻率。在內部評估中,代碼中的無關編輯從 GPT-4o 的 9% 下降到了 GPT-4.1 的 2%。
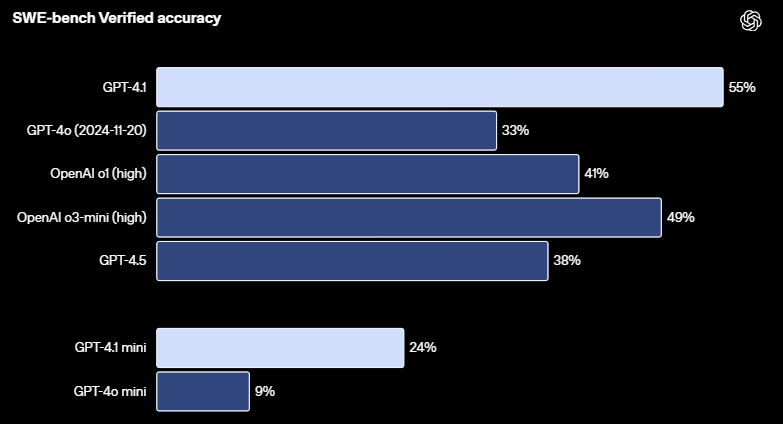
圖
| SWE-bench Verified 測試成績(來源:OpenAI)
此外,根據OpenAI 不久前發佈的更新日誌,OpenAI 將很快從 ChatGPT 中淘汰其兩年多前推出的 AI 模型 GPT-4。
OpenAI 表示,自今年 4 月 30 日起,GPT-4 將被 ChatGPT 當前的預設模型 GPT-4o 完全取代。如有需要,GPT-4 仍可通過 OpenAI 的 API 訪問。
GPT-4o 最初於 2024 年 5 月作為旗艦模型推出,可實時推理音頻、視覺和文本。
OpenAI 在更新日誌中寫道:「在針對性評估中,GPT-4o 在寫作、編碼、STEM 等方面始終超越 GPT-4。最近的升級進一步提高了 GPT-4o 的指令遵循、問題解決和對話流程,使其成為 GPT-4 的自然繼承者。」
GPT-4 於 2023 年 3 月推出,適用於 ChatGPT 和微軟的 Copilot 聊天機器人,具備多模態功能,能夠同時理解圖像和文本,是廣泛部署的 OpenAI 模型的首個版本。
如今,隨著OpenAI 剛剛發佈的 GPT-4.1 系列模型,以及傳聞中待發佈的 o3 和 o4-mini 推理模型,GPT-4 的正式退休也在情理之中。
不過,如今OpenAI 面對的競爭壓力遠遠大於 GPT-4 初亮相的時候。在 Gemini 2.5 Pro、Claude 3.7 Sonnet 和 DeepSeek 的夾擊之下,新 GPT 和 o 系列模型任重而道遠。
參考資料:
https://openai.com/index/gpt-4-1/
https://techcrunch.com/2025/04/14/openai-plans-to-wind-down-gpt-4-5-its-largest-ever-ai-model-in-its-api/
https://techcrunch.com/2025/04/14/openais-new-gpt-4-1-models-focus-on-coding/