GPT-4.1深夜偷襲,OpenAI掏出史上最小、最快、最便宜三大模型,百萬token上下文

智東西4月15日報導,剛剛,OpenAI一口氣掏出了GPT-4.1系列的三款模型,並稱這是其有史以來最小、最快、最便宜的模型系列,且新模型的整體性能表現要優於GPT-4o和GPT-4o mini。
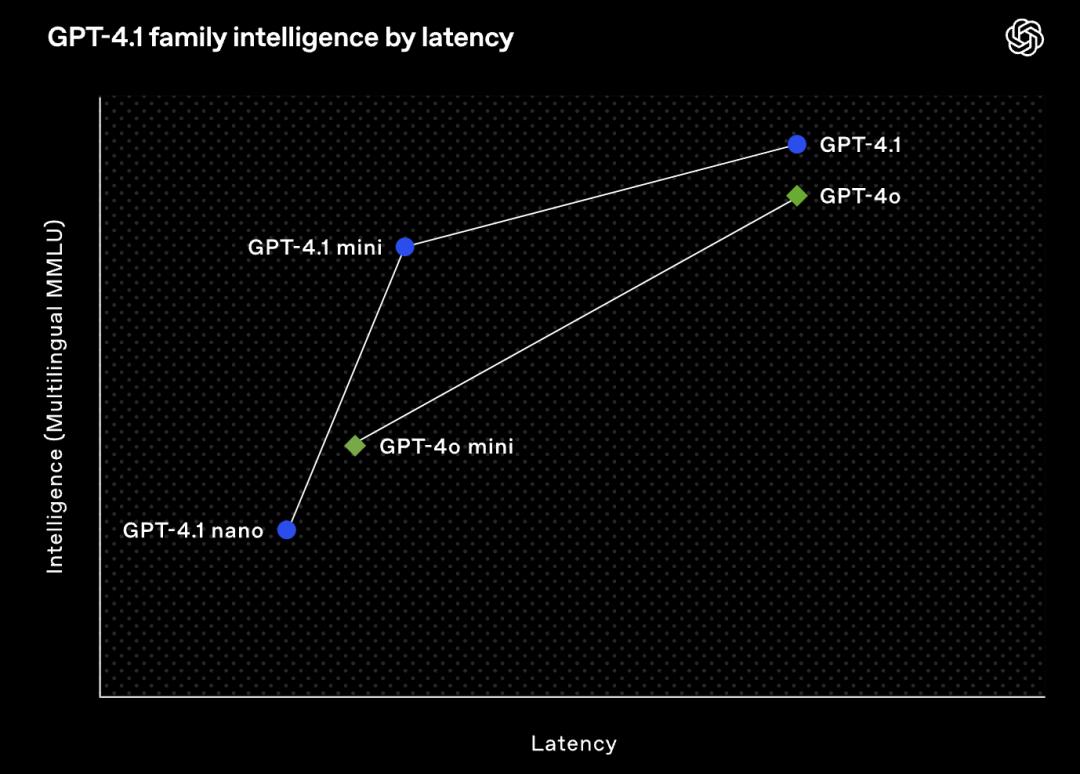
GPT-4.1系列模型包含三個模型:GPT-4.1、GPT-4.1 mini和GPT-4.1 nano,上下文窗口均達到100萬個token,輸出token數達到32768個,知識截止日期為2024年6月。OpenAI的基準測試顯示,其在編碼、指令遵循、長文本理解方面的得分均超過了GPT-4o和GPT-4o mini。

GPT-4.1系列模型僅通過API提供,現已對所有開發者開放。OpenAI將開始在API中棄用GPT-4.5預覽版,因為GPT-4.1系列模型在許多關鍵能力上提供了相似性能,同時成本和延遲更低。GPT-4.5預覽版將在今年7月14日關閉。
具體的性能優化集中於編碼、指令遵循、長文本理解上:
編碼:GPT-4.1在SWE-bench驗證測試中得分54.6%,較GPT-4o提升了21.4%,較GPT-4.5提升了26.6%。
指令遵循:在Scale的衡量指令遵循能力指標的MultiChallenge基準測試中,GPT-4.1得分38.3%,較GPT-4o提升了10.5%。
長文本理解:在多模態長文本理解的Video-MME基準測試中,GPT-4.1在無字幕的長文本類別中得分72.0%,較GPT-4o提升了6.7%。
對延遲較為敏感的場景,OpenAI重點提到了GPT-4.1 nano,並稱這是其最快、最經濟的模型。GPT-4.1 nano基準測試MMLU得分為80.1%,GPQA得分為50.3%,Aider多語言編碼得分為9.8%,均高於GPT-4o mini。
OpenAI在博客中提到,性能表現更好、更經濟的GPT-4.1系列模型將為開發者構建智能系統和複雜的智能體應用開闢新的可能性。
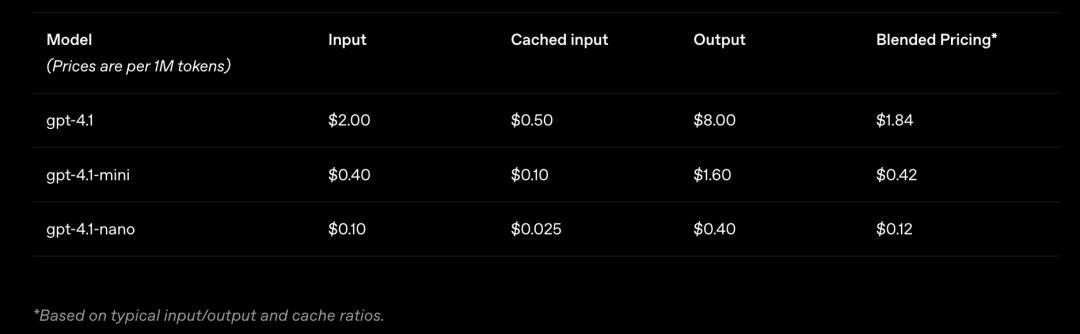
價格方面,對於中等規模的查詢,GPT-4.1的價格比GPT-4o低26%,對於重覆使用相同上下文的查詢,OpenAI將提示緩存摺扣從之前的50%提高到了75%。最後,除了標準的每token費用之外,OpenAI不會對長上下文請求額外收費。
01.
編碼能力:表現優於GPT-4o
超80%用戶喜歡GPT-4.1的應用
GPT-4.1在多種編碼任務上的表現優於GPT-4o,包括主動解決編碼任務、前端編碼、減少不必要的編輯、遵循diff格式、確保工具使用的一致性等。
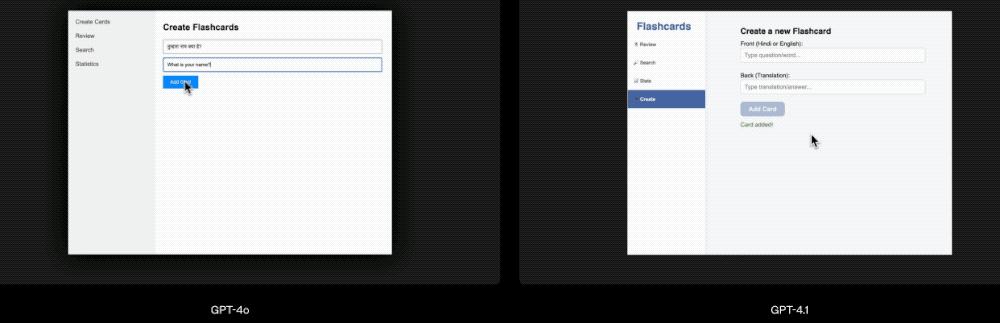
相比於GPT-4o,GPT-4.1可以創建功能更強大、美觀度更高的Web應用,如下圖所示的「閃卡」應用:
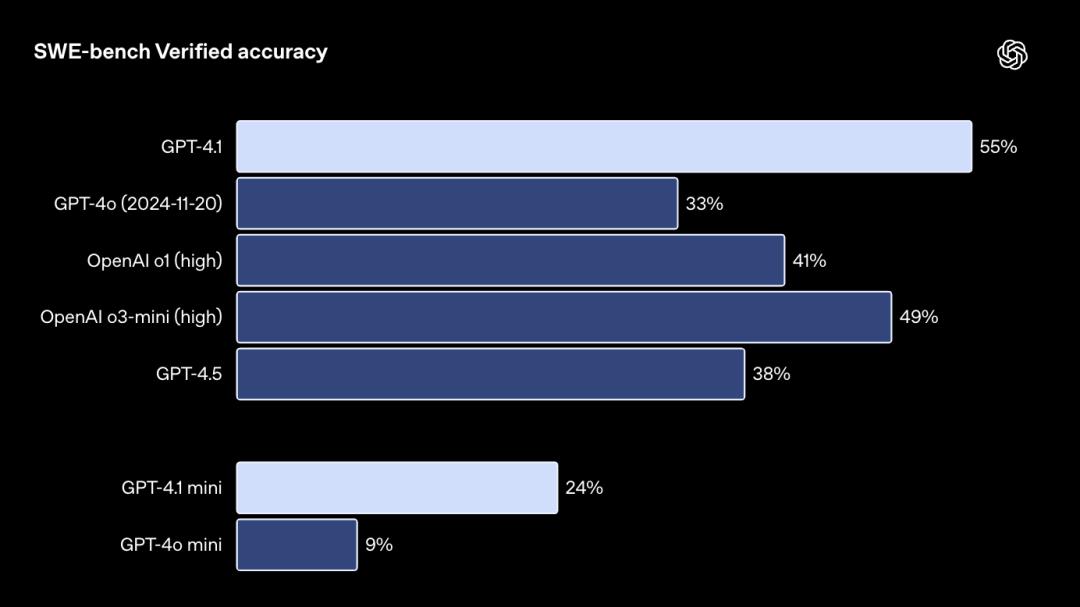
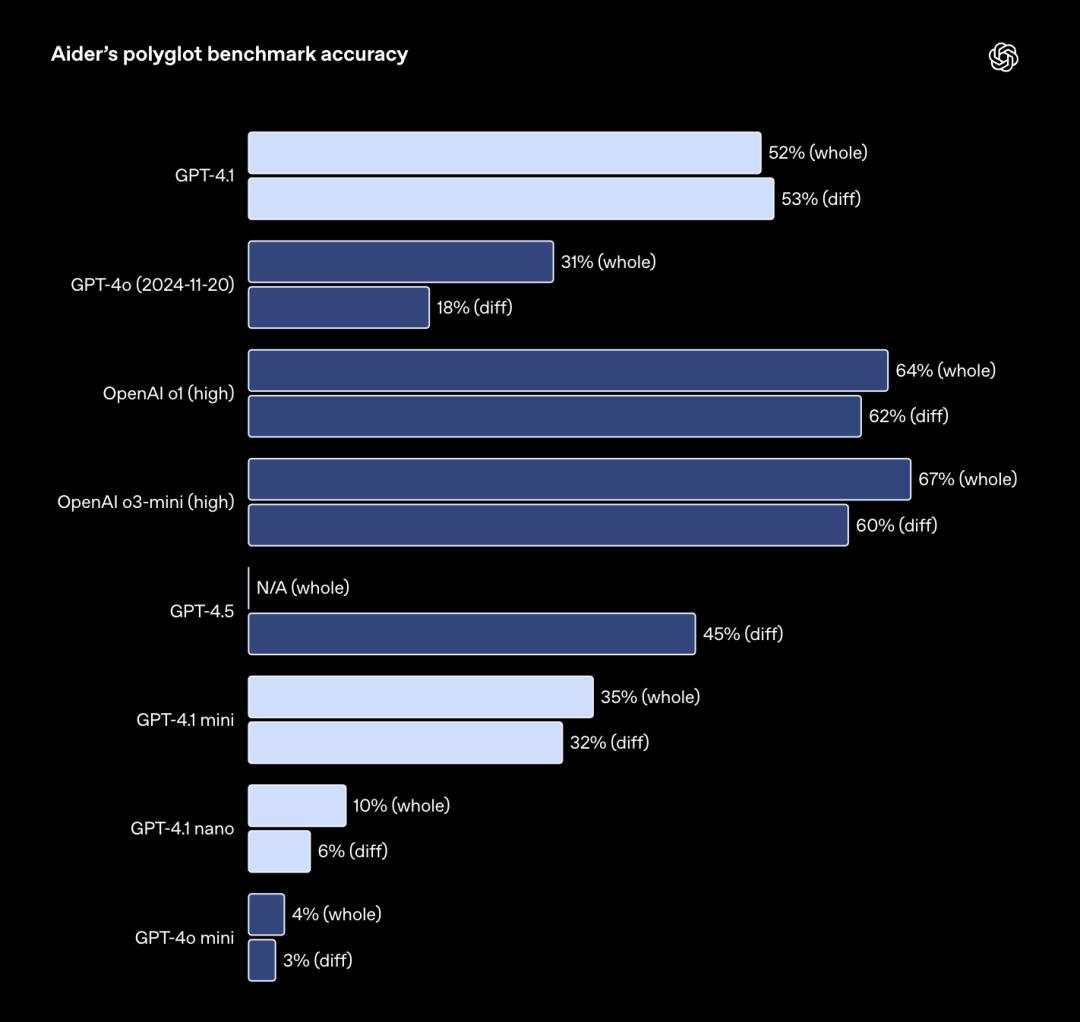
在衡量現實世界軟件工程技能的指標SWE-bench Verified上,GPT-4.1完成了54.6%的任務,GPT-4o為33.2%,這說明GPT-4.1在探索代碼庫、完成任務以及生成既可運行又可通過測試的代碼方面的能力提升。
 ▲該測試中,模型會收到一個代碼庫和問題描述,然後其需要生成補丁來解決該問題,模型的表現會高度依賴於所使用的提示和工具。
▲該測試中,模型會收到一個代碼庫和問題描述,然後其需要生成補丁來解決該問題,模型的表現會高度依賴於所使用的提示和工具。對於希望編輯大文件的API開發者來說,GPT-4.1在多種格式下的代碼差異方面更加可靠。GPT-4.1在多語言差異基準測試Aider中的得分,是GPT-4o的兩倍,比GPT-4.5高出8%。
這項評估既考察模型對各種編程語言編碼的能力,還有對模型在整體和差異格式下產生變化的能力。OpenAI專門訓練了GPT-4.1以遵循差異格式,這使得開發者可以通過模型僅輸出更改的行來節省成本和延遲,而不是重寫整個文件。
此外,OpenAI將GPT-4.1的輸出token限制增加到32768個,GPT-4o為16384個token,其還建議使用預測輸出以減少完整文件重寫的延遲。
 ▲在Aider中,模型通過編輯源文件來解決Exercism的編碼練習,允許重試一次。
▲在Aider中,模型通過編輯源文件來解決Exercism的編碼練習,允許重試一次。前端編碼方面,GPT-4.1能夠創建功能更強大、美觀度更高的Web應用。在OpenAI的對比測試中,人工評分員在80%的情況下更青睞GPT-4.1生成的網站,而非GPT-4o生成的網站。
在上述基準測試之外,GPT-4.1可以減少不必要的編輯。在OpenAI的內部評估中,代碼中的不必要的編輯從GPT-4o的9%降至GPT-4.1的2%。
02.
遵循指令:評估6大關鍵指令性能
多輪自然對話效果比GPT-4o提高10.5%
OpenAI開發了一個內部評估系統,用於跟蹤模型在多個維度和幾個關鍵指令遵循類別中的性能,包括:
Format following:提供指定模型響應自定義格式的指令,例如XML、YAML、Markdown等;
Negative instructions:指定模型應避免的行為,例如「不要要求用戶聯繫支持」;
Ordered instructions:為模型提供一組必須按給定順序執行的指令,例如「首先詢問用戶的姓名,然後詢問他們的電子郵件」;
Content requirements:輸出包含某些信息的內容,例如「撰寫營養計劃時,始終包含蛋白質含量」;
Ranking:以特定方式排序輸出,例如「按人口數量排序」。
Overconfidence:如果請求的信息不可用或請求不屬於給定類別,則指導模型說「我不知道」或類似的話。例如:「如果你不知道答案,請提供支持聯繫郵箱。」
OpenAI的博客中提到,這些類別是根據開發者反饋得出的。在每個類別中,OpenAI將簡單、中等和困難提示進行了細分,GPT-4.1在困難提示方面相對於GPT-4o有顯著提升。
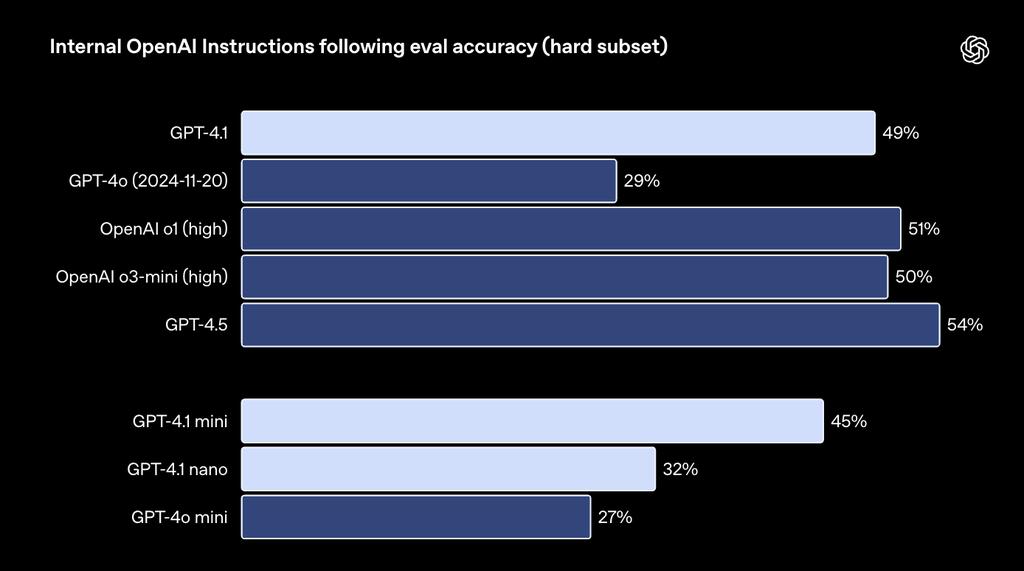 ▲GPT-4.1在困難提示方面表現
▲GPT-4.1在困難提示方面表現多輪指令遵循對開發者的重要性在於,模型需要保持對話的連貫性,並跟蹤用戶之前告訴它的內容。OpenAI訓練GPT-4.1,以使得其能更好地從過去的對話信息中提取信息,從而實現更自然的對話。在Scale的MultiChallenge基準中,GPT-4.1比GPT-4o提高了10.5%。
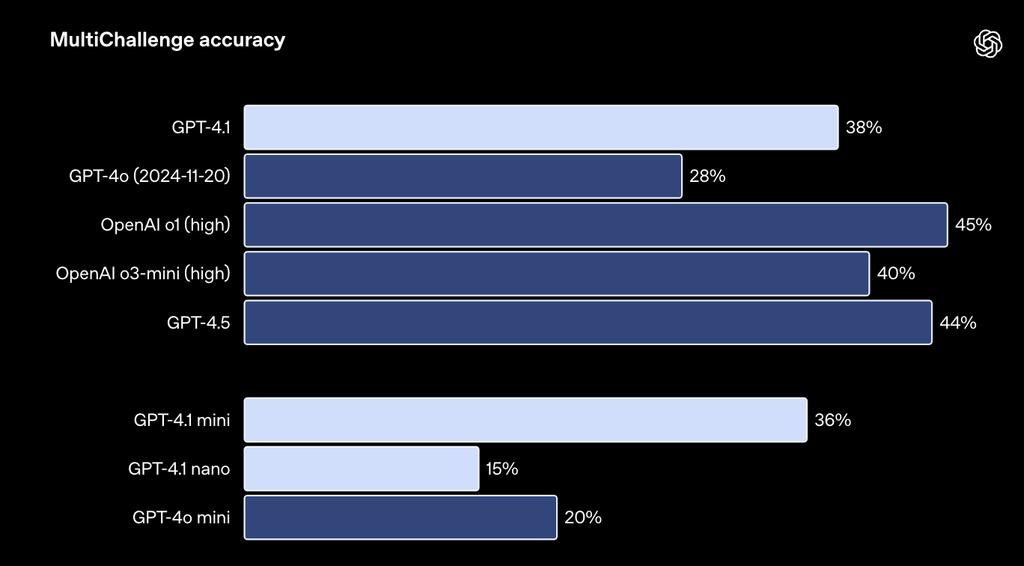 ▲GPT-4.1在MultiChallenge中測試結果
▲GPT-4.1在MultiChallenge中測試結果在IFEval測試中,其使用具有可驗證指令的提示,例如,指定內容長度或避免某些術語或格式。GPT-4.1得分達到87.4%,GPT-4o為81.0%。
 ▲GPT-4.1在IFEval中測試結果
▲GPT-4.1在IFEval中測試結果早期測試者指出,GPT-4.1可能更容易理解字面意思,因此OpenAI建議開發者可以在提示中明確具體的指令。
03.
長文本理解:適合處理大型代碼庫、長文檔
「大海撈針」也不在話下
GPT-4.1系列模型可以處理100萬個token上下文,此前GPT-4o的上下文窗口為128000個。100萬個token已經是整個React代碼庫的超過8倍之多,因此長上下文適合處理大型代碼庫或大量長文檔。
OpenAI還對GPT-4.1模型進行了訓練,使其能在長和短上下文長度中忽略乾擾信息,這也是法律、編碼、客戶支持等多個領域的企業應用的關鍵能力。
博客中,OpenAI展示了GPT-4.1在上下文窗口內不同位置檢索一條隱藏的少量信息(即一根 「針」)的能力,也就是「大海撈針」的能力。
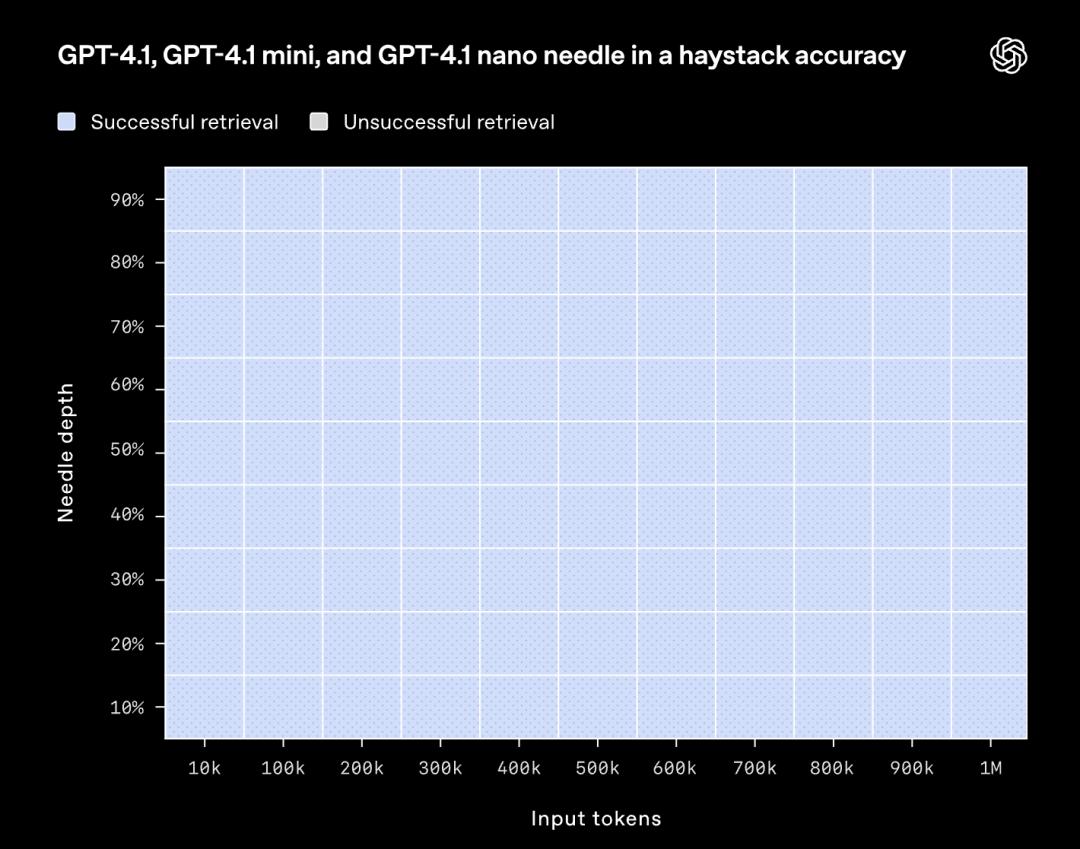 ▲OpenAI內部針對GPT-4.1模型的「大海撈針」評估
▲OpenAI內部針對GPT-4.1模型的「大海撈針」評估其結果顯示,GPT-4.1能夠在所有位置以及各種上下文長度(直至長達100萬個token)的情況下準確檢索到這條關鍵信息(「針」)。無論相關細節在輸入內容中的位置如何,它都能提取出與當前任務相關的細節。
在實際使用中,用戶經常需要模型理解、檢索多個信息片段,並理解這些片段之間的關係。為了評估這一能力,OpenAI正在開源新的評估工具:OpenAI-MRCR(多輪核心詞識別)。
OpenAI-MRCR可以用來測試模型在上下文中找到和區分多個隱藏得關鍵信息的能力。評估包括用戶和助手之間的多輪合成對話,用戶要求模型寫一篇關於某個主題的文章,例如或「寫一篇關於岩石的博客文章」。隨後,其會在整個對話上下文中插入2、4或8次相同的請求,模型需要據此檢索出對應特定請求實例的回覆。
在OpenAI-MRCR中,模型回答的問題,會擁有2個、4個或8個分散在上下文中的相似提示詞干擾項,模型需要在這些問題和用戶提示之間進行消歧。
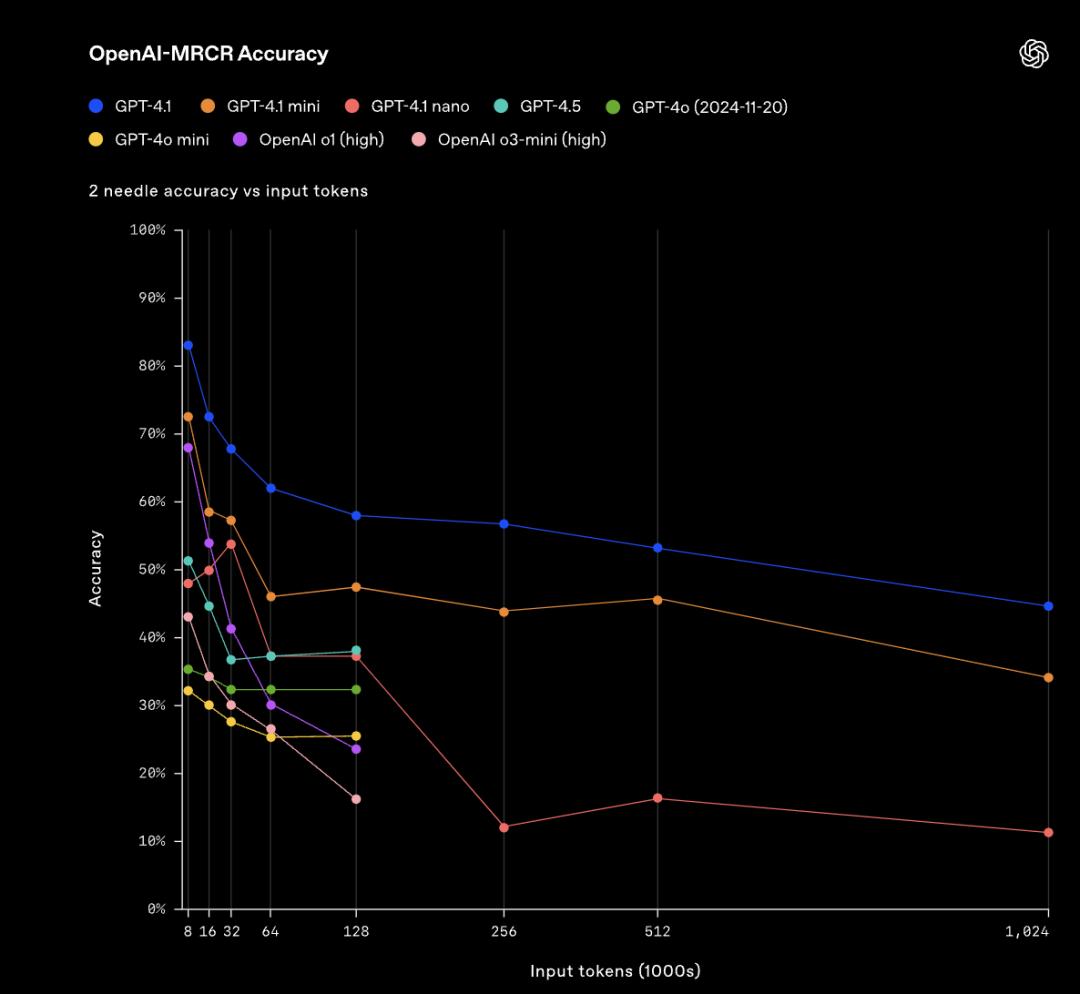 ▲在OpenAI-MRCR中,模型回答問題被添加2個干擾項的評估結果
▲在OpenAI-MRCR中,模型回答問題被添加2個干擾項的評估結果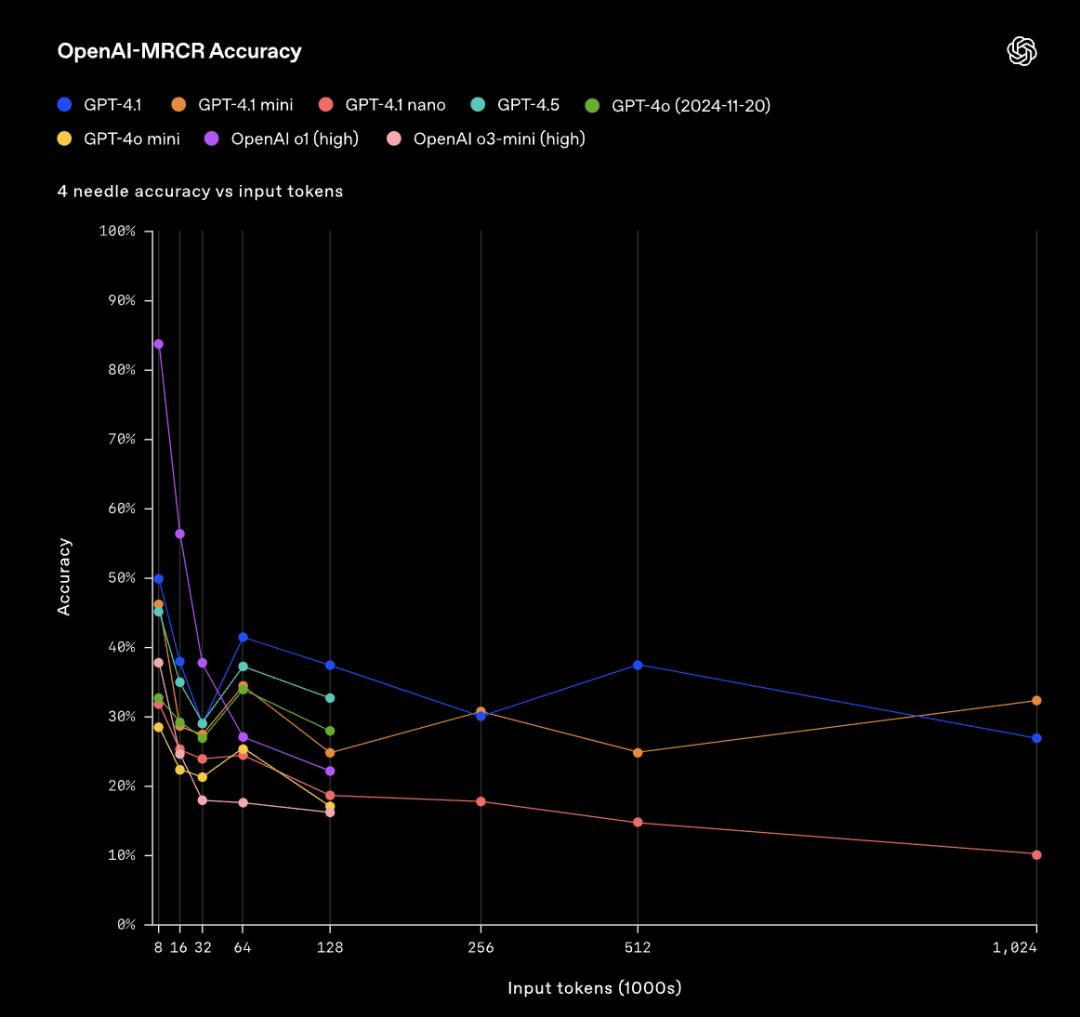 ▲在OpenAI-MRCR中,模型回答問題被添加4個干擾項的評估結果
▲在OpenAI-MRCR中,模型回答問題被添加4個干擾項的評估結果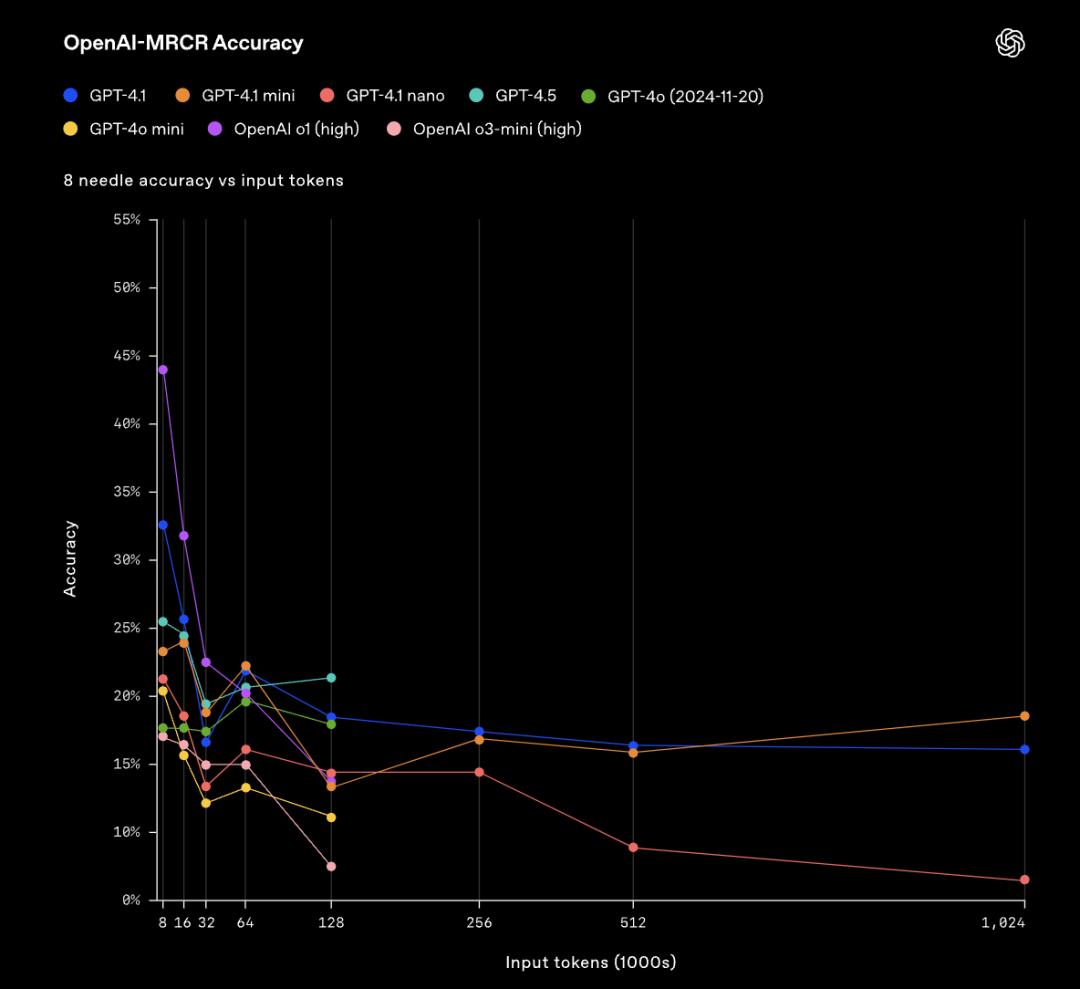 ▲在OpenAI-MRCR中,模型回答問題被添加8個干擾項的評估結果
▲在OpenAI-MRCR中,模型回答問題被添加8個干擾項的評估結果這之中的挑戰就是,這些請求與上下文其餘部分很相似,模型容易被細微的差異所誤導。OpenAI發現,GPT-4.1在上下文長度達到128K個token時優於GPT-4o。
OpenAI還發佈了用於評估多跳長上下文推理的數據集Graphwalks。這是因為,許多需要長上下文的開發者用例需要在上下文中進行多個邏輯跳躍,例如在編寫代碼時在多個文件之間跳轉,或者在回答覆雜的法律問題時交叉引用文檔等。
Graphwalks需要模型跨上下文多個位置進行推理,其使用由十六進製散列組成的定向圖填充上下文窗口,然後要求模型從圖中的一個隨機節點開始進行廣度優先搜索(BFS),然後要求它返回一定深度的所有節點。
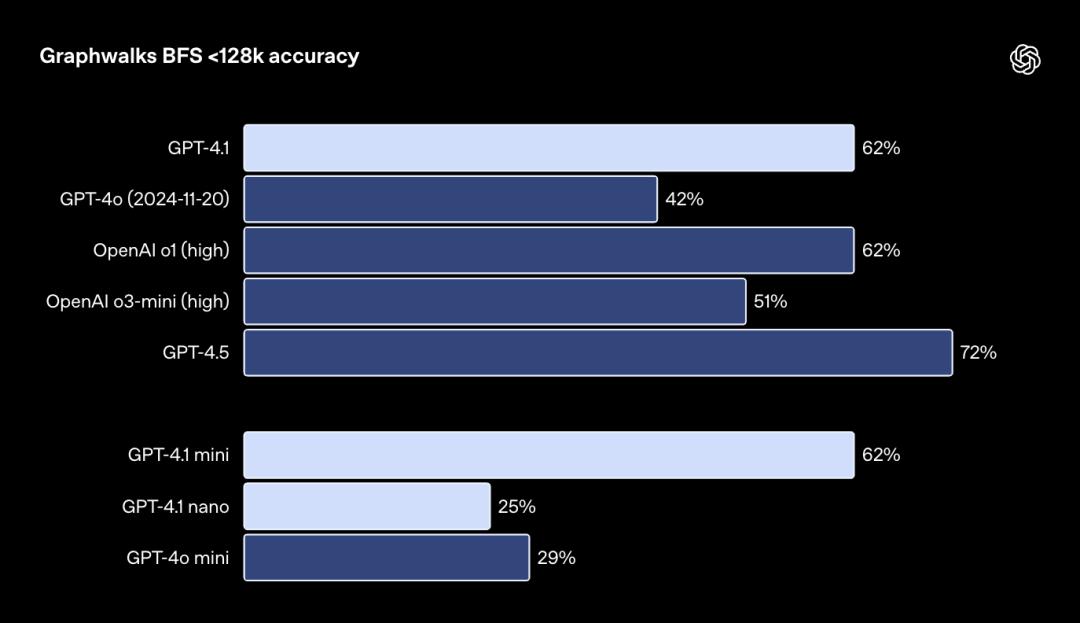 ▲Graphwalks評估結果
▲Graphwalks評估結果GPT-4.1在這個基準測試中達到了61.7%的準確率,與o1的表現相當,並且擊敗了GPT-4o。
除了模型性能和準確性之外,開發者還需要能夠快速響應以滿足用戶需求的模型。OpenAI改進了推理堆棧,以減少首次token的時間,並且通過提示緩存進一步降低延遲、節省成本。
OpenAI的初步測試顯示,GPT-4.1的p95首次token延遲大約為十五秒,在128000個上下文token的情況下,100萬個上下文token為半分鐘。GPT-4.1 mini和nano更快,如GPT-4.1 nano對於128000個輸入token的查詢,通常在五秒內返回第一個token。
04.
多模態理解:無字幕影片答題、看圖解數學題
表現均超GPT-4o
在圖像理解方面,GPT-4.1 mini在圖像基準測試中優於GPT-4o。
對於多模態用例,如處理長影片,長上下文性能也很重要。在Video-MME(長無字幕)中,模型根據30-60分鐘長的無字幕影片回答多項選擇題,GPT-4.1得分72.0%,高於GPT-4o的65.3%。

模型回答包含圖表、圖表、地圖等問題的MMMU測試結果:

模型解決視覺數學任務的MathVista測試結果:
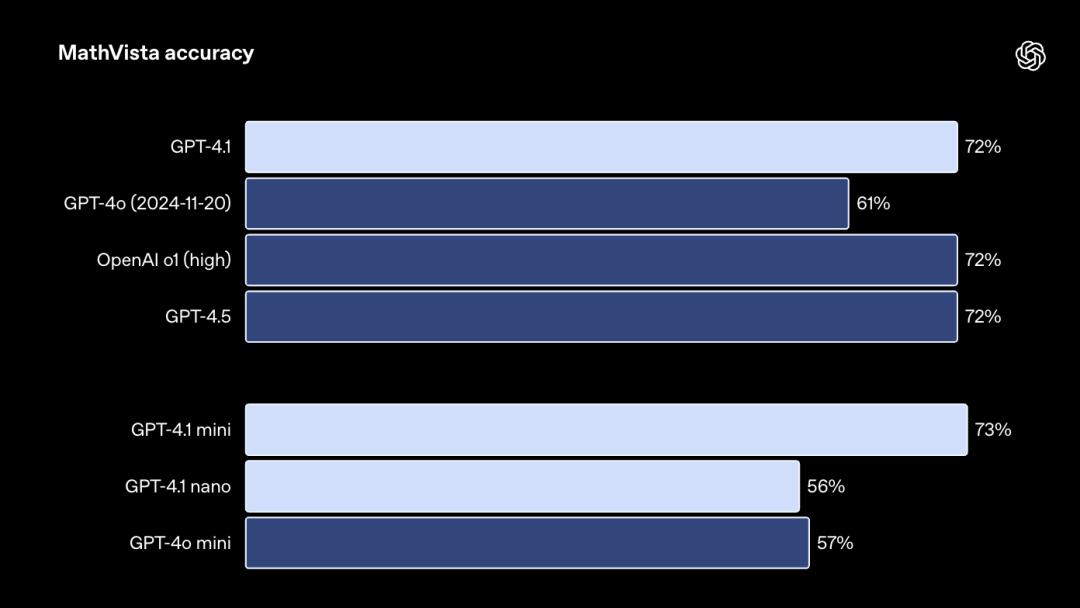
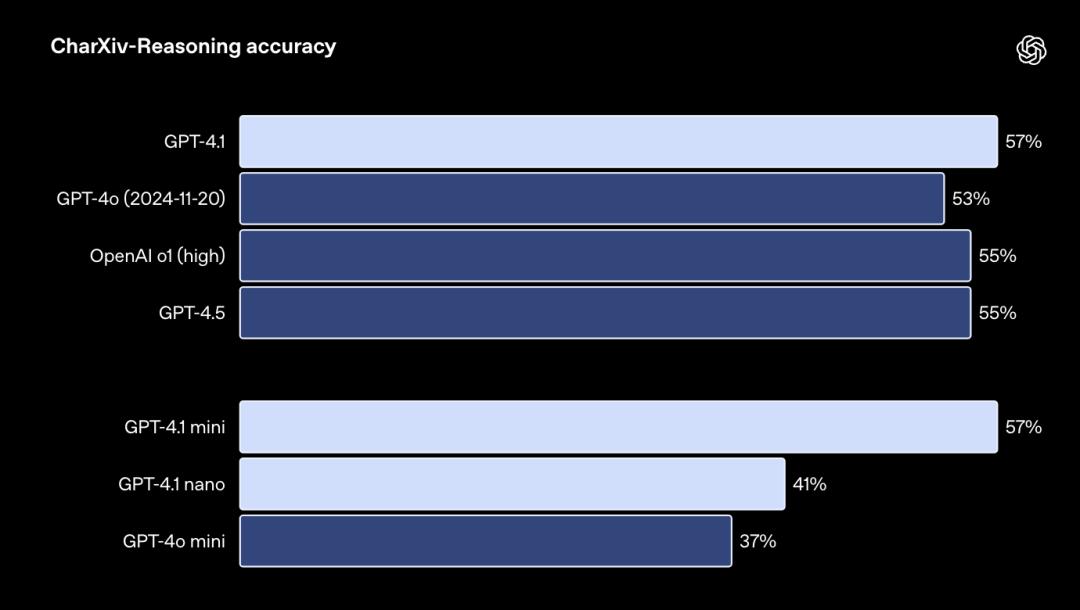
模型回答關於科學論文圖表問題的CharXiv-Reasoning測試結果:
05.
結語:為構建複雜智能體開闢可能性
GPT-4.1的提升與開發者日常開發的真實需求相關,從編碼、指令遵循到長上下文理解,性能表現更好、更經濟的GPT-4.1系列模型為構建智能系統和複雜的智能體應用開闢了新的可能性。
未來,這或許會使得開發者將其與各類API結合使用,構建出更有用、更可靠的智能體,這些智能體可以在現實世界的軟件工程、從大量文檔中提取見解、以最小的人工干預解決客戶請求以及其他複雜任務方面有應用的潛力。
本文來自微信公眾號「智東西」(ID:zhidxcom),作者:程茜,編輯:雲鵬,36氪經授權發佈。