OpenAI護城河被攻破,AI新王Anthropic爆賺45億,拿下企業級LLM市場
剛剛,矽谷爆出新料:OpenAI企業市場份額斷崖式下跌,Anthropic全面反超!
GPT-5再不來,奧特曼正要熬夜頭禿,無法入眠了!
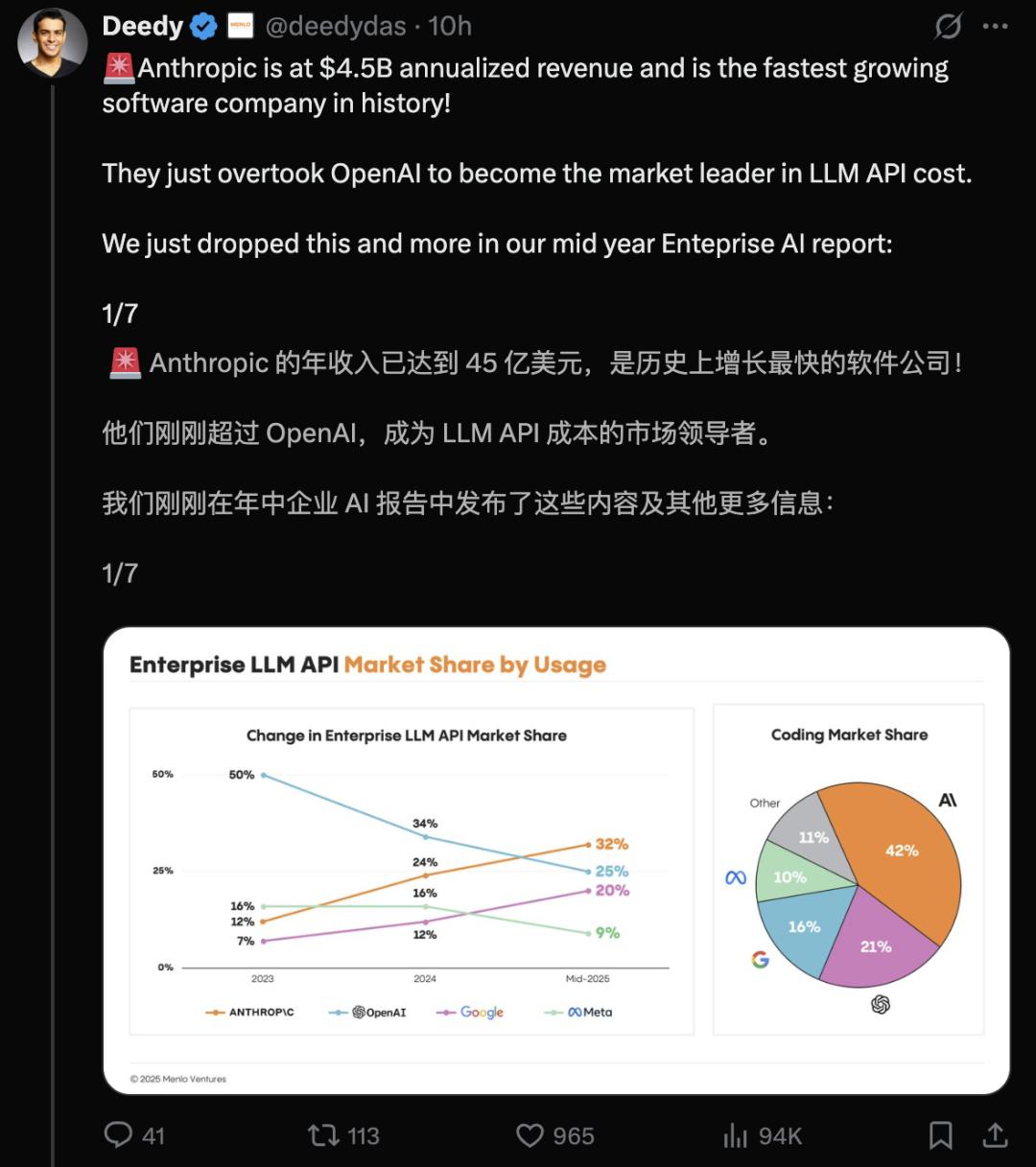
剛剛,OpenAI最強勁敵Anthropic被曝年化收益已達45億美元,晉級為史上增長最快的軟件公司。
在LLM API賽道上,Anthropic成功登頂,而OpenAI在AI編程上更是落荒而逃,市場份額只有Anthropic一半!
X上的網紅投資人、矽谷VC大佬Deedy,繼2024年AI產業報告之後,重磅推出了年中LLM市場更新報告:
這次他直接斷言:舊皇已死,新王登基!隨著使用量和支出的激增,新的企業級LLM領導者已應運而生。
除了預判未來趨勢外,這次他還分享了LLM商業化的4大趨勢:
1. Anthropic在企業領域的使用率已超越OpenAI
2. 企業採納開源技術的趨勢正在放緩
3. 企業更換模型看重的是性能提升,而非價格優勢
4. 企業在AI上的投入正從模型訓練轉向實際應用的推理階段
LLM天下三分,OpenAI痛失一城
2025年已過一半,AI大模型賽道卻已悄然進入「半場戰事」。
剛剛,Menlo Ventures發佈了半場報告,揭示了整個LLM行業的新格局,也為下半年的市場走勢埋下了伏筆。
這次重點在企業市場。在6月30日至7月10日,他們調研了150家開發AI應用的企業和初創公司技術負責人。
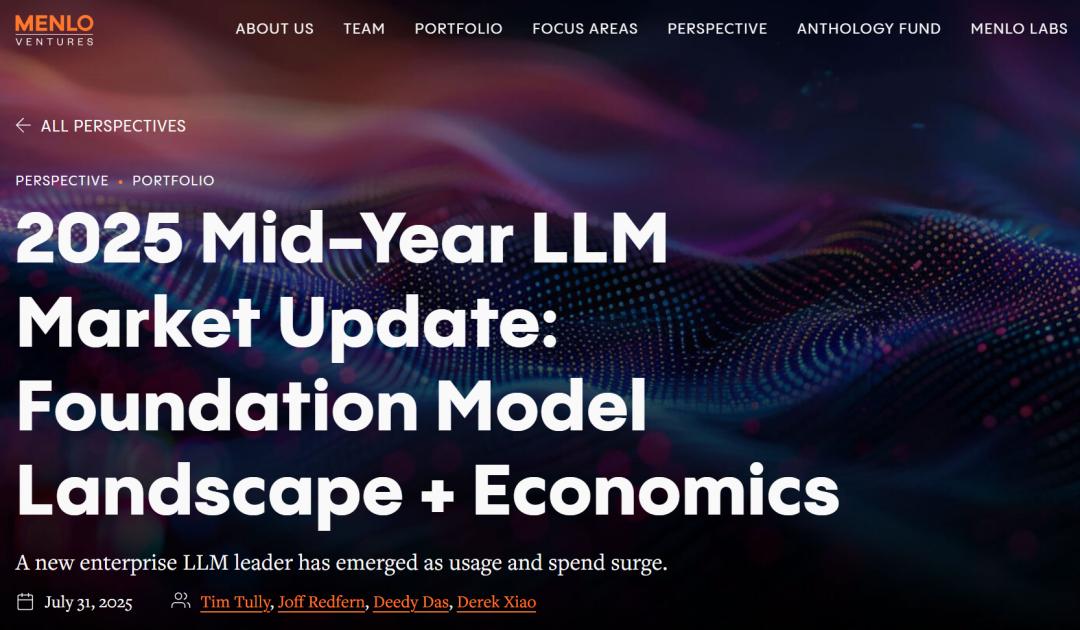 「企業」指員工規模超5000人的組織,初創公司則要求至少500萬美元風險投資
「企業」指員工規模超5000人的組織,初創公司則要求至少500萬美元風險投資到本年中,企業在基礎模型API上的投入已高達84億美元,遠超去年全年的兩倍。他們預計企業在基礎模型上的花費還將繼續飆升。
 企業在LLM API方面的支出
企業在LLM API方面的支出正如他們的報告所言:基礎模型不僅是生成式AI的動力,還在塑造計算的未來。
隨著其能力與商業模式的演進,構建於其上的系統、應用和產業也將隨之變革。
曾經,OpenAI憑藉ChatGPT 3.5和4系列橫掃市場,遙遙領先。
但如今,局勢開始鬆動。
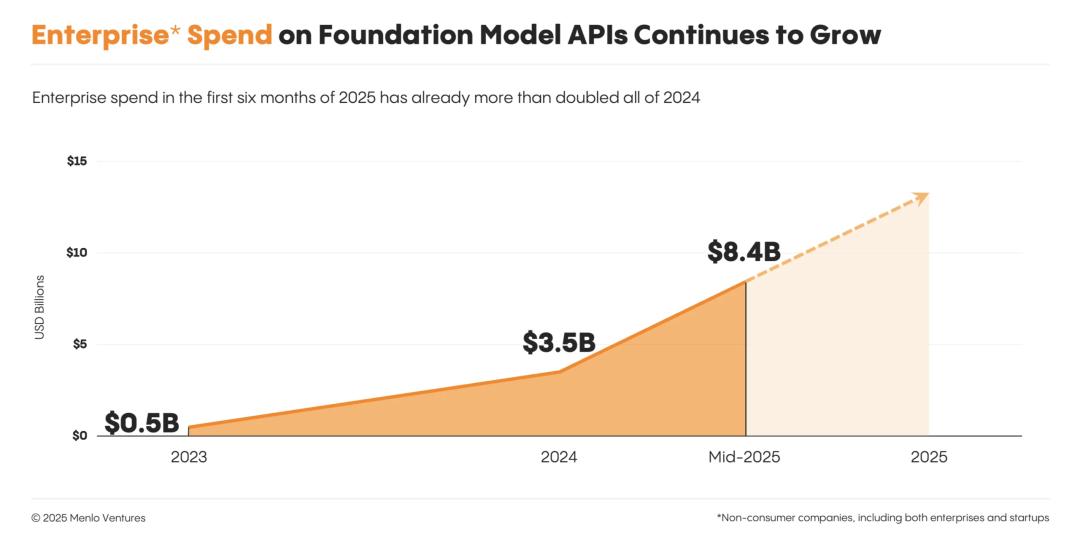
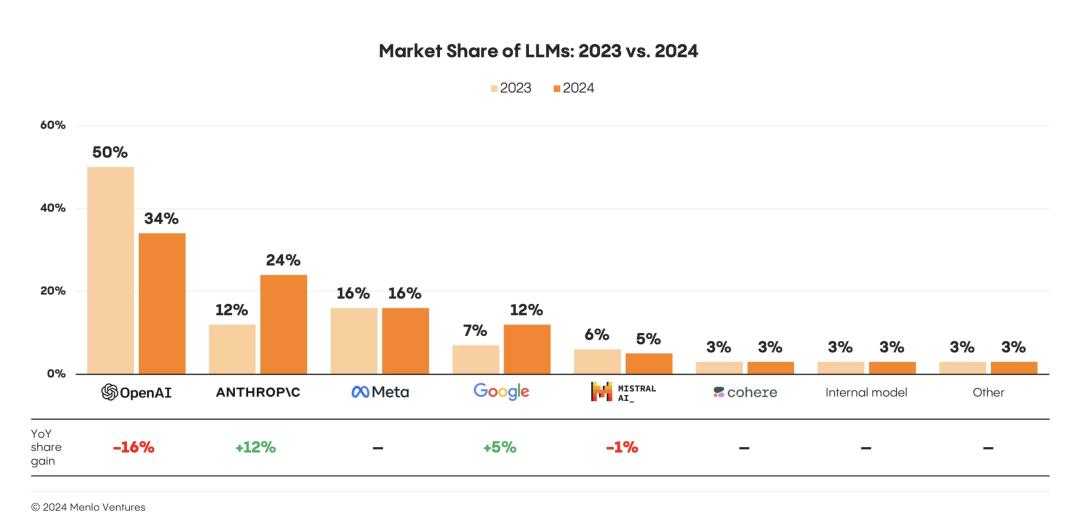
從2023年到今年年中,企業LLM API調用量市場數據顯示:
· Anthropic上增長最快,以32%的份額擊敗OpenAI,成功登頂;
· Google增長速度次之,年中市場份額已達20%,位居第三;
· OpenAI和Meta使用份額持續下降,尤其是OpenAI從50%跌至25%;
· Meta的使用份額不足9%,淪為邊緣角色。
這就是他們的核心發現:Anthropic在企業使用率上超越了OpenAI。

OpenAI已失一城,難再躺贏。
美版「AI三國」正式成型。
舊王已逝,新皇登基
在2023年底,OpenAI一度佔據企業LLM市場50%的份額,但如今地位不再,現在的使用率僅為25%,是兩年前的一半。
而Anthropic已成為企業AI市場的新晉領導者,佔據了32%的份額,領先於OpenAI和Google(20%)。
最近幾個月,Google也表現出強勁的增長。Meta只佔據了9%的份額。
國產的DeepSeek在年初發佈,也佔了1%。
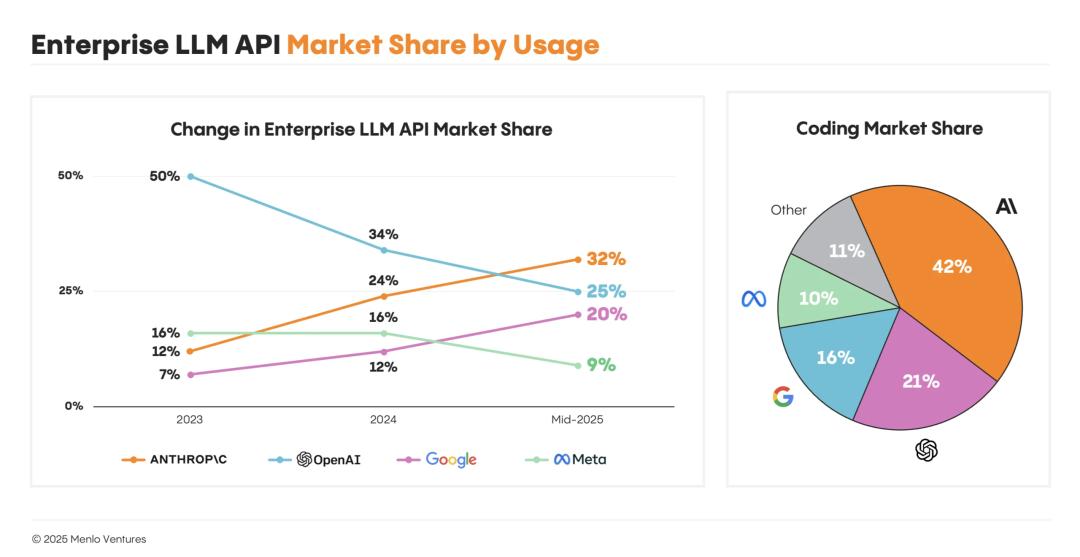 按使用量計算的企業LLM API市場份額
按使用量計算的企業LLM API市場份額Anthropic的強勁形勢,真正始於2024年6月Claude Sonnet 3.5的發佈。
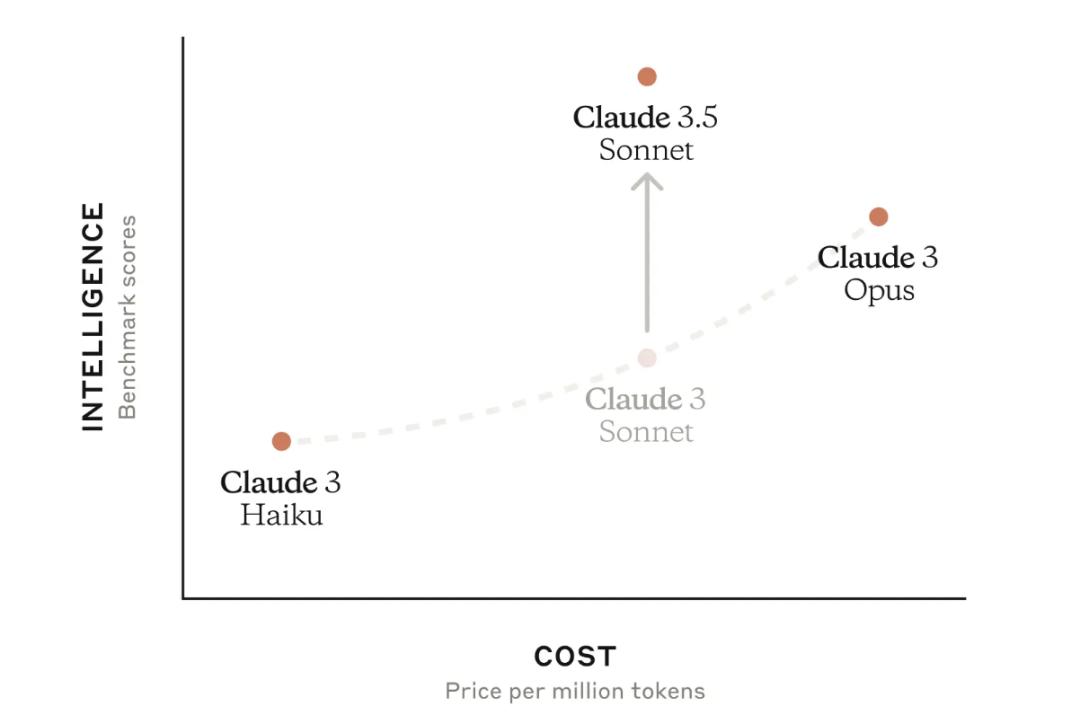 與Claude 3 Haiku和Opus比較,Claude Sonnet 3.5具有極高的性價比
與Claude 3 Haiku和Opus比較,Claude Sonnet 3.5具有極高的性價比今年2月,Anthropic推出了Claude Sonnet 3.7。
Claude Sonnet 3.7首次讓人們一瞥「Agent-First」大語言模型。這進一步加速了這股形勢。
到5月,Claude Sonnet 4、Opus 4和Claude Code相繼發佈,Anthropic徹底鞏固了市場領先地位。


至此,Anthropic一鼓作氣成功登頂,而OpenAI痛失企業LLM市場龍頭地位。
Anthropic乘風而起
Anthropic的崛起也得益於三個顛覆性行業趨勢。
(1)代碼生成成為AI的首個殺手級應用。
Claude迅速成為開發者Coding首選,佔據了42%的市場份額,是OpenAI(21%)的兩倍多。
僅在一年內,Claude就幫助將GitHub Copilot市場,轉變為價值19億美元的龐大生態系統。
2024年6月發佈的Claude Sonnet 3.5證明,模型層的突破能直接撬動應用市場,催生出全新賽道:
· AI IDE:Cursor、Windsurf等;
· 應用構建器:Lovable、Bolt、Replit等;
· 企業級編碼智能體:Claude Code、All Hands等;
……
(2)帶驗證器的強化學習,成為提升模型智能的新路徑。
在2024年,提升模型智能的主要方法是投入更多數據,進行更大規模的預訓練。
如今,互聯網數據的規模本身正成為瓶頸。而採用帶可驗證獎勵的強化學習(RLVR)進行後訓練,則成為推動技術前沿的下一個突破口。
在編碼這類易於進行確定性驗證的領域,該策略的效果尤為出色。
(3)將模型訓練為使用工具的「智能體」,使其效用大增。
最初,LLM被設計為在一次交互中給出完整答案。
然而,通過訓練模型進行分步思考、推理問題,並在多次交互中調用外部工具——即構建所謂的「智能體」——能極大地提升模型在真實應用場景中的效能。因此,2025年被稱為「智能體之年」。
Anthropic在這方面處於領先地位,他們訓練模型以迭代方式優化回答,並通過模型上下文協議(MCP)整合搜索、計算器、編碼環境等多種工具,從而顯著提升了模型的能力和用戶採用率。
海外企業市場,開源日漸沉寂
現在,只有13%的AI工作負載使用開源模型,而半年前是19%。
 2024年,Menlo Ventures調研的LLM市場份額同期對比
2024年,Menlo Ventures調研的LLM市場份額同期對比過去半年內,DeepSeek(V3,R1)、Qwen3、GLM-4.5等國內開源大模型相繼發佈,引人注目。
這次調研顯示市場份額最大的是Meta廣受歡迎的Llama模型,但其4月發佈的Llama 4表現未及預期。
對企業而言,開源模型優勢明確:
可定製性更強、有潛在的成本效益,並且能部署在私有雲或本地環境中。
但在性能上,他們認為開源模型仍落後於頂尖閉源模型大約9到12個月。
這種性能差距,加上部署開源模型的技術複雜性,以及企業技術選型的猶豫,共同導致了開源模型市場份額的停滯。
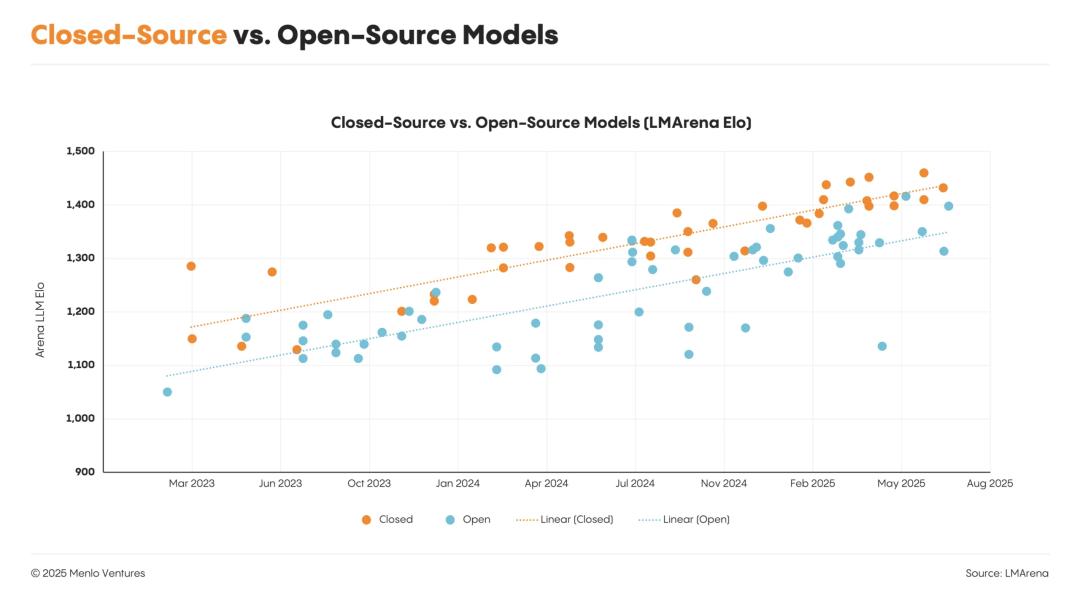 閉源模型 vs. 開源模型
閉源模型 vs. 開源模型不僅是大型企業,出於同樣的原因,選擇開源模型的初創公司也越來越少。
正如一位受訪者所說:
目前,我們的生產工作負載,100%運行在閉源模型上。最初,我們使用Llama等進行概念驗證(POC)。但隨著時間推移,它們的性能無法跟上閉源模型的步伐。
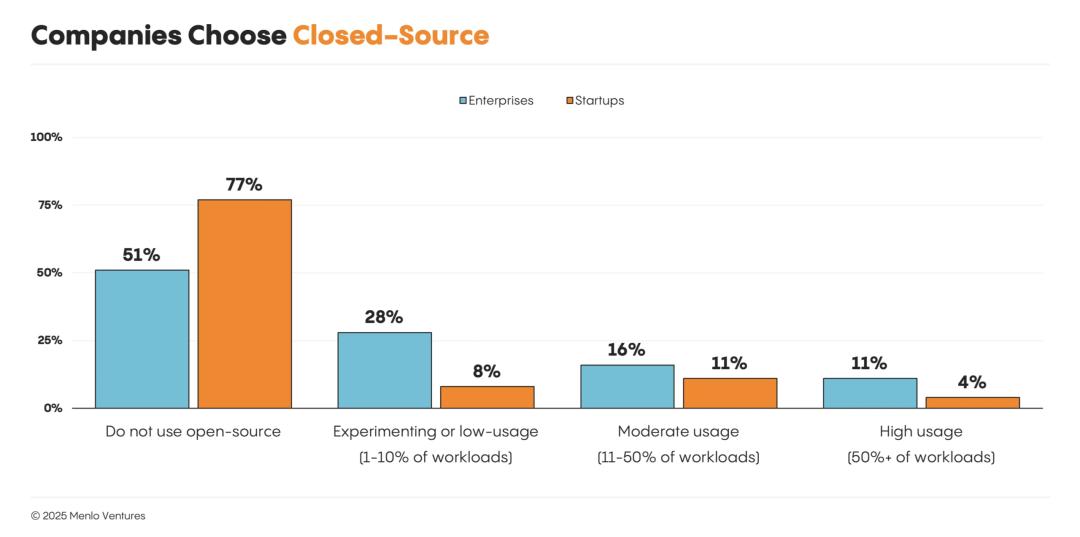 公司選擇閉源
公司選擇閉源價格戰在企業市場行不通
儘管在不同供應商之間切換模型的難度相對較低,但這種情況正變得越來越少見。
大多數團隊會繼續使用原有的供應商,只在新模型發佈時進行升級。一旦開發者選定一個平台,他們就傾向於留下來,但會在性能更強的新模型發佈時迅速升級。
過去一年,66%的開發者在原供應商內部升級了模型,23%完全沒有更換模型,只有11%更換了供應商。
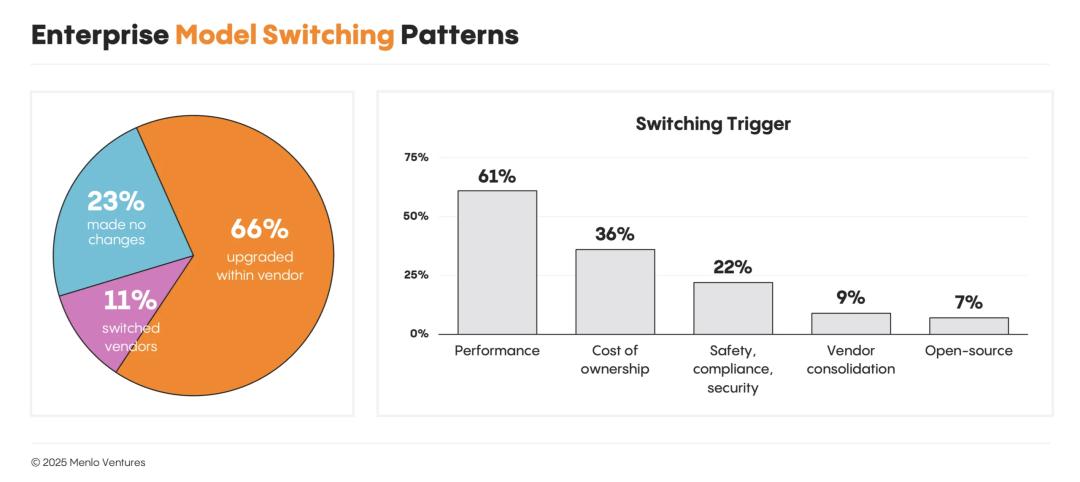 企業模型切換模式
企業模型切換模式性能是決策的核心驅動力。
開發者們始終選擇最前沿的模型,而不是那些更便宜、更快的替代品。他們優先考慮性能,並願意為此付費。每當新模型發佈,切換通常在幾週內完成。例如,在Claude 4發佈的一個月內,Claude 4 Sonnet就吸引了45%的Anthropic用戶,而Sonnet 3.5的份額則從83%驟降至16%。
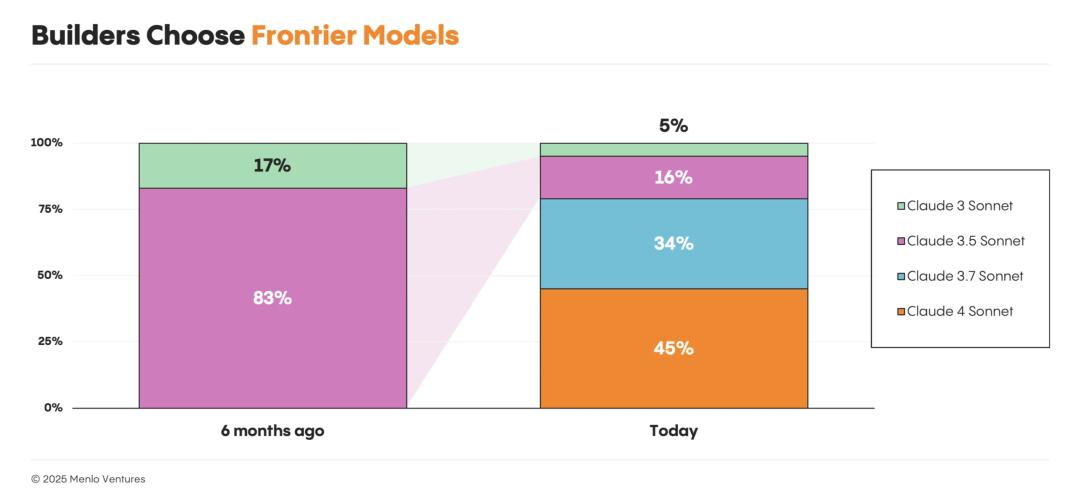 開發者選擇前沿模型
開發者選擇前沿模型一種出人意料的市場趨勢出現了:
即使模型的價格每年下降10倍,開發者也不會為了節省成本,只用舊模型;他們只會集體遷移到性能最強的新模型。
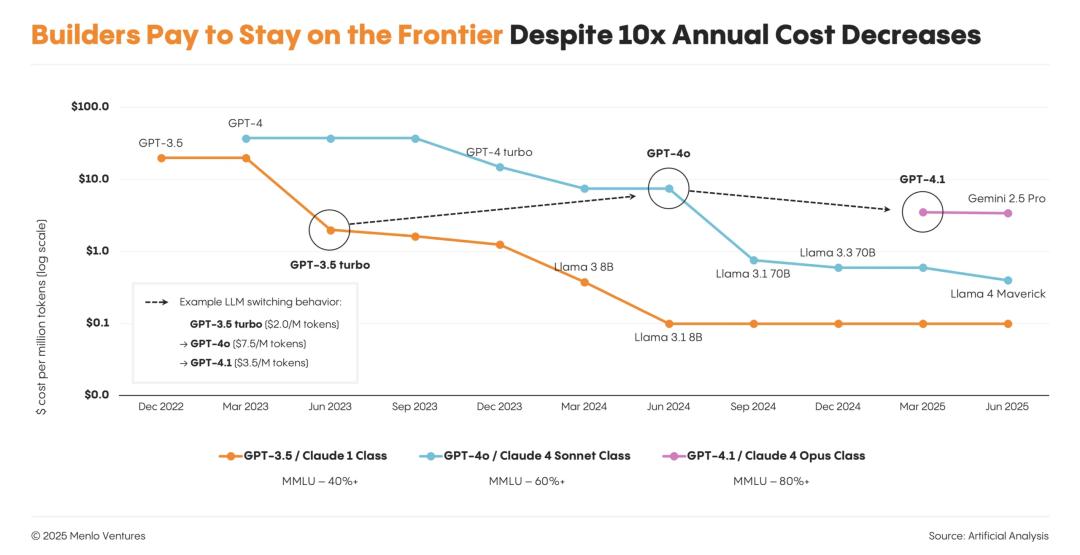 儘管年度成本下降10倍,開發者仍願付費使用前沿模型
儘管年度成本下降10倍,開發者仍願付費使用前沿模型推理比訓練更花錢
計算資源的支出正在穩步地從模型構建和訓練,轉向模型推理——即模型在生產環境中的實際運行。
這種轉變在初創公司中最為顯著:74%的開發者表示,他們的大部分工作負載是推理,遠高於一年前的48%。
大型企業也緊隨其後,近一半(49%)的企業報告稱,其絕大部分計算資源由推理驅動,而去年這一比例僅為29%。
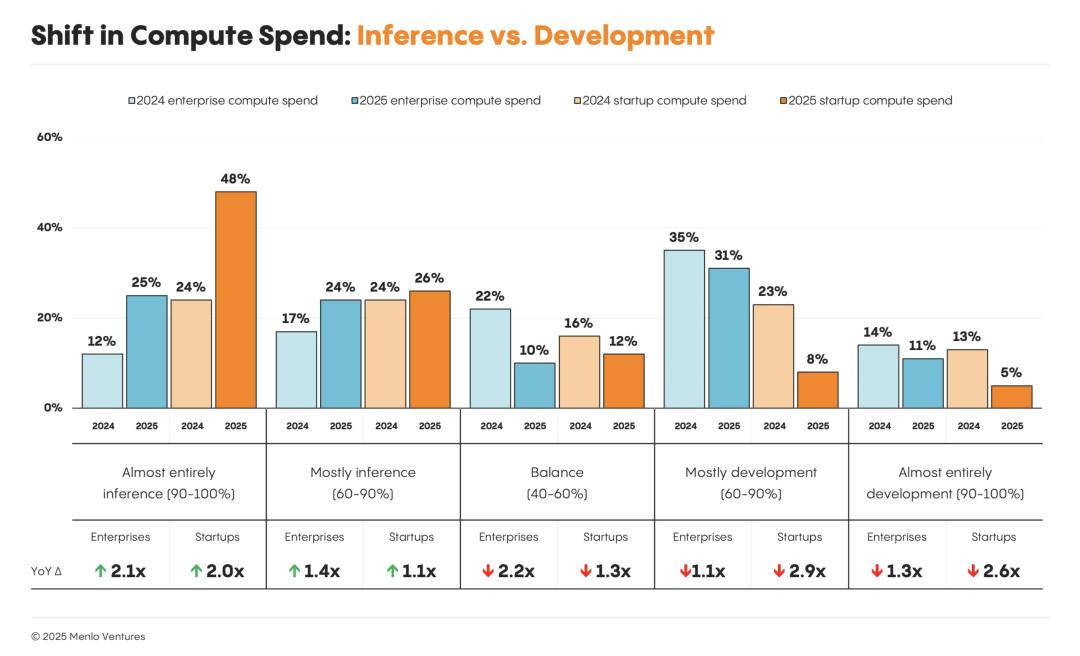 計算資源支出的轉變:推理 vs. 開發
計算資源支出的轉變:推理 vs. 開發AI行業新時代
應用為王時代來臨,LLM不再是極客的「電子寵物」,而是企業的「基礎設施」。
不再是demo show-off,不再是PPT跑分,現在LLM必須落地到真實應用場景中。
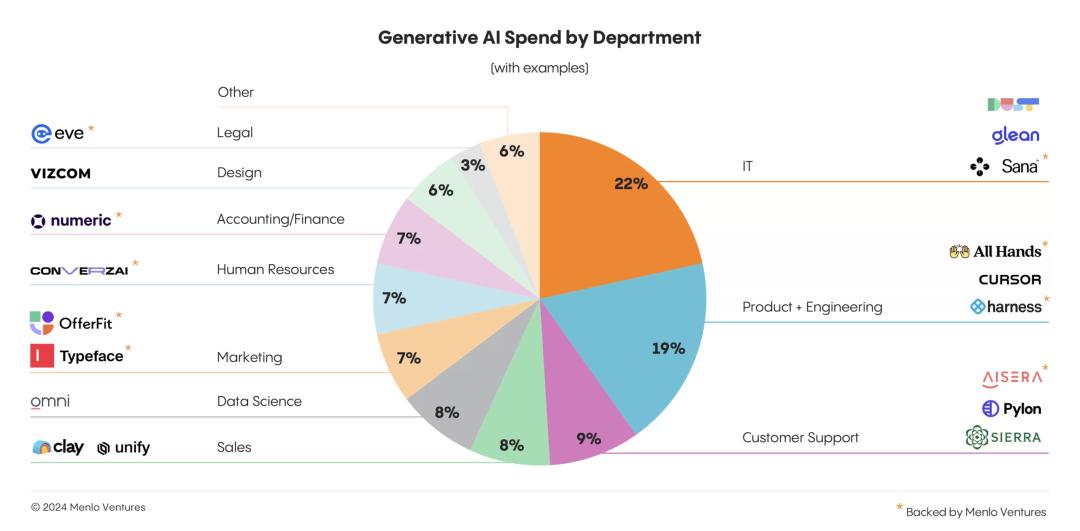
應用新趨勢:
· API平台化:Anthropic、Cohere等轉型做「開發者友好接口」
· 垂類微調:醫療、金融、代碼生成等場景專屬模型風口已起
· 原生產品爆發:AI Agent、AI寫作、AI分析師迅速湧現
誰能提供真實ROI,誰才是下一個市場贏家。
LLM市場正在重新洗牌,一場無聲的淘汰賽已經展開。
或許,2023年屬於OpenAI,2024年屬於Claude與Llama,但2025年,屬於誰還遠未確定。
而我們只知道:
模型性能≠市場贏家
封閉系統≠未來主流
高估值≠商業成功
真正的贏家,是「AI界的福特」——那個「讓AI用起來的人」。
參考資料:
https://x.com/deedydas/status/1950942147529843121
https://menlovc.com/perspective/2025-mid-year-llm-market-update/
本文來自微信公眾號「新智元」,作者:新智元,36氪經授權發佈。