曠視科技:堅定投入基礎科研 擁有核心引領技術
自從大模型火爆出圈,全球範圍新一輪的科技革命正式拉開了序幕,人工智能成為中美兩國競爭的焦點,中美人工智能企業也顯現出了各自特色。美國已然形成了以微軟和OpenAI為代表的“科技巨頭+ AI 獨角獸”超級 AI 聯盟,擁有強大的技術實力以及巨量資本投入。中國在大模型方面跟進動作很快:據《中國人工智能大模型地圖研究報告》統計,中國10億以上參數規模的大模型已經發佈了79個。
雖然中國AI公司一路狂飆,但是只有少數公司真正具備通用大模型的技術儲備和資源積累。投資者和市場要在嘈雜當中,去尋找那些真正具備大模型算法、框架等基礎性原創性技術突破能力的行家。
從根源上講,這一次大模型規模爆發的起源仍是深度學習、大模型延續了深度學習的發展。人工智能史上的深度學習大週期依然強勁。2011年成立於北京中關村的曠視科技,是中國最早一批用深度學習方法開展人工智能基礎研發和產業實踐的人工智能獨角獸。和當下湧現出的新一批大模型應用公司不同,曠視十年如一日攻堅人工智能核心技術,不斷創新突破,力圖縮小與美國科技的差距。
從清華走出來的曠視科技的創始團隊,是一群被理想感召的年輕人。“成為受世界尊敬的中國AI公司!”這是曠視科技聯合創始人、CEO印奇在多次採訪中表達過的創業理想。2010年伴隨著深度學習技術,曠視創始團隊發現了計算機視覺技術和智能硬件具有潛在的巨大商業價值。
曠視科技用十年時間完成了高密度的AI人才彙集,組建了全球規模最大的計算機視覺研究院,並取得了一系列具有國際影響力的科研成果,在全球計算機視覺等關鍵領域取得了領先地位:自2014年,曠視拿下了FDDB、LFW、300-W三類圖像類評測世界第一的好成績後,曠視就開始了在國際各類頂級競賽的屠榜之旅,曾經一舉擊敗微軟、Google、Meta等美國科技巨頭,拿下計算機視覺頂級賽事MS COCO十餘項挑戰賽冠軍,被譽為AI界的“中國乒乓球隊”。
國際競賽領先的水平體現了曠視研究院強大算法實力,而算法背後離不開基礎科研的攻堅。在深度學習爆發早期,全球範圍的算法研究員都缺少算法開發工具。2013年底,曠視研發團隊提出了一個現在看來非常也先進的理念:打造一套能夠打通數據、訓練和業務的自動化算法研發系統,可以實現算法從研發到應用的自循環體系。
於是,2014年初,曠視研究院3名實習生從第一行代碼寫起,用半年時間開發了自研的深度學習框架MegEngine。也幾乎是同一時間,Google開發了TensorFlow並於次年對外開源。
深度學習框架上承應用,下接芯片,其重要性不言而喻。“國外大廠都開源了,我們有必要做自己的框架嗎?”當時曠視內部對此爭議非常大。但是經過一系列的評測,大家發現TensorFlow的設計理念和曠視自研的框架出奇一致,然而效果並沒有曠視自研的好,甚至比曠視自研框架要慢上10倍。這個結果讓曠視更加堅定地走上了自研道路。與此同時,曠視跟隨業務發展需要一併研發了數據管理系統MegData和深度學習雲計算平台MegCompute,為訓練出行業領先的高性能算法提供高質量數據養料和大規模計算集群的算力調度。
2019年,曠視將算法、數據和算力能力整合,發佈了MegEngine、MegCompute和MegData構成的人工智能操作系統Brain++。這樣一套自主研發的AI生產力底座平台和中間層工具,成為曠視多年以來基礎研發和創新產品領跑行業的秘籍,也助力曠視研發出了ShuffleNet、DorefaNet等一系列具有國際影響力和產業影響力的原創算法模型。
2020年3月,為了讓中國更多AI從業者用上先進、好用的開發工具,共同加速行業發展,曠視將自研自用了5年的深度學習框架開源,並為MegEngine取了中文名字——天元。這一舉動讓曠視成為了國內第一個將深度學習框架開源的AI獨角獸,也是目前的唯一一個。
國家也對曠視在自研基礎設施層面的投入和成果給予了高度的認可和信任。曠視在深度學習開源框架、數據集、圖像感知技術等領域承擔了國家科技部、工信部、北京市科委等國家級、省級部委多項重大科研項目,推動中國人工智能技術創新。例如,2019年8月,科技部宣佈依託曠視Brain++建設“圖像感知國家新一代人工智能開放創新平台”;2023年,科技部批準曠視科技與西交大合作建設人機混合增強智能全國重點實驗室,該實驗室定位為人機混合增強智能基礎理論與核心技術研究,將著力圍繞國家重大工程與智能產業應用,聚焦解決重大科技問題,打造國際領先的混合增強智能國家戰略科技力量。
除了競賽奪冠的高光時刻,曠視研究院在行業中始終是相對低調和務實的,鮮少看到曠視研究院的研究員活躍在行業活動中。和大廠中被束之高閣的研究員相比,曠視的開發人員更下沉貼近業務,注重科研的實用性。
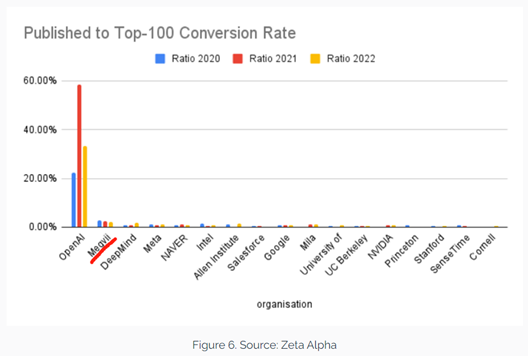
國外一家跟蹤AI研究的ZetaAlpha提供了一組有趣的數據,他們基於 2020年、2021年和 2022年每年被引用次數最多的100篇AI算法領域的論文進行了多維度的詳細分析,並公佈了科研轉化率排名,其中曠視超過DeepMind、Meta、英特爾、Google等全球科技巨頭,排名第二,僅次於美國AI獨角獸OpenAI。但實際曠視被納入統計範圍的論文僅有兩篇,只憑藉兩篇文章卻獲全球AI算法科研轉化率第二的成績,恰恰說明了曠視團隊的科研成果質量之高,以及在產學界的受歡迎程度。
人類的科技曆史始終是疊加發展的,大模型時代同樣如此。對於生長在神經網絡和深度學習樹幹之上的大模型樹冠來說,算法、算力和數據依然是土壤、肥料和陽光雨露般的存在,無論對於深度學習時代的人工智能企業來說,還是對大模型時代的初創企業來說,基礎科研是基本功,基本功如果不夠紮實,靠花拳繡腿上不了更大的擂台。
毋庸置疑,曠視的算法能力已經在全球範圍獲得了公認。隨著中美科技競爭加劇,曠視的潛能也讓美國有所忌憚。2019年10月,美國將曠視科技等28家科技公司列入實體清單;2021年11月,美國財政部又無端將曠視科技列入非SDN中國軍事綜合體清單,限制美國投資者對上述公司投資;2022年10月7日,美國商務部再次以“威脅美國國家安全”為由宣佈針對中國的出口管製新規,將曠視科技列為最嚴厲的“華為式”製裁清單,以至曠視成為中國受美國定向打壓最多輪次的中國AI企業。
曠視在複雜嚴峻的內外環境下沒有放棄底層技術的攻堅。除了三個圍繞核心業務主線的研發團隊,曠視研究院還有兩個團隊專門負責突破技術邊界。曠視的Brain++為團隊的基礎科研和業務發展提供了有力的支撐。
今年,以ChatGPT為代表的人工智能大模型的出現引爆了低迷已久的人工智能市場,為通用人工智能的實現打開了新的想像空間。從表面上看,曠視在這一輪大模型落地競速賽中盡顯低調,但實際上,曠視團隊在過去十年已經形成了更深遠的佈局。
尤其是在基礎模型方面,曠視實力雄厚。早在2017年,曠視研究院就開始投入AI視覺大模型研發,提出的“MegDet”目標檢測模型,首次實現了百卡級別的檢測模型高效訓練,並支持團隊在COCO 2017目標檢測競賽中獲得世界冠軍。MegDet 中所提出的“sync bn”歸一化方法已成為今天視覺大模型訓練的必備算法,被知名框架如Facebook的PyTorch等所支持。
2020年之後,曠視開始攻堅大模型,形成了以通用視覺大模型、通用語言大模型、圖像生成大模型、自動駕駛大模型的“四大核心大模型”研發戰略,誕生了多項世界級的研發成果。例如在通用視覺大模型方面,曠視業內首創了“模型重參數化方法”(RepVGG),能夠在不改變推理耗時的情況下大幅提升性能,助力多項大模型落地。值得注意的是,RepVGG如今已成為視覺大模型實用化部署的首選算法之一,獲得了OpenAI聯合創始人、特斯拉前總監 Andrej Karpathy在Twitter上公開肯定。
在系統層面,曠視於2021年6月將動態圖顯存優化技術引入了已經開源的深度學習框架天元MegEngine,使天元成為首個引入該技術的深度學習框架。該技術可以大幅降低顯存佔用問題,幫助開發者節省硬件成本,用有限的硬件資源訓練出更大的模型。
而支撐著曠視技術不斷突破的Brain++操作系統,自身也在不斷進化。目前,Brain++平台集成了領先了數據管理能力和強大的算力管理能力。平台已積累200萬億token的數據集;可調度管理超萬塊GPU集群訓練單一模型,大模型訓練GPU 資源利用率可以到 80% 以上,可以高效支持大模型研發。
當下,能夠同時處理文字、圖像、視頻的多模態大模型已成為大模型競爭的下一個戰場,曠視憑藉在AI視覺上的多年積累,早已開始相關技術探索,提出的圖文交錯數據的預訓練方法已展現出很強的通用性。
在印奇看來,多模態大模型是通向AGI(通用人工智能)的必由之路,大模型將讓AI技術走上融合統一之路。不過曠視誌不在此,他認為曠視和國際巨頭競爭的終極戰場在AIoT,從長期角度來看,曠視將專注在“大模型+機器人”大方向並堅定投入,致力於將大模型與硬件載體結合。
當下,中美在大模型核心技術和產業鏈佈局上存在差距,但是中國也有獨特的長板,那就是巨大的市場空間和一批敢打敢拚的創業者,所以在新一波浪潮下,中國形成“百模大戰”的局面是必然結果。然而,在短期的繁榮之後,我們還是會回到更本質的問題:中國人工智能企業靠什麼才能贏得更長期的發展?或許曠視給了我們答案,那就是要把每一步路走紮實,不斷修煉內功,創造真正價值。