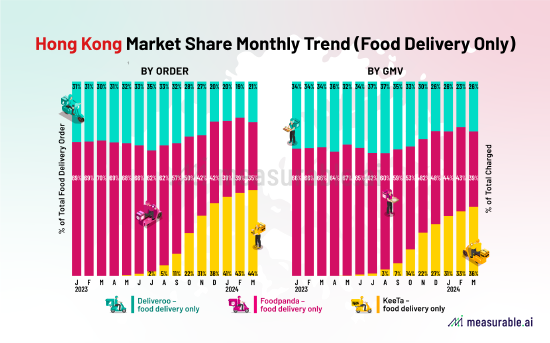
新經濟視界 | 國產大模型掀起“長內容”大戰 要把AI變成人們的“超級知識助手”
封面新聞記者 歐陽宏宇
繼通義千問、Kimi之後,又一國產AI大模型正式進入長內容競賽。
4月26日,科大訊飛更新訊飛星火大模型V3.5版本。更新後,訊飛星火將支援長文本、長圖文、長語音功能,以及多情感超擬人合成、智能體平台等能力。據介紹,這些能力將幫助個人和企業解決大模型落地的最後一公里難題。

國內大模型開始新一輪“我有多長”的比賽,背後是具備了長內容能力後,AI大模型不僅能夠把各種信息來源的海量文本、圖文資料、會議錄音等進行快速學習,進而在各種行業場景給出專業、準確回答。圍繞這一應用場景,多個國內大模型已展開競爭。
以長文本為例,今年3月,在Kimi限額開放200萬字長文本能力後,各大廠排隊官宣跟進這一賽道。通義千問緊隨其後直接免費開放1000萬字長文本功能,文心一言、360智腦也在籌備或內測相關能力,其開放文本長度也在500萬字左右。訊飛星火長文檔能力總體也已達到GPT-4 Turbo最新版本的97%水平,甚至在部分垂直領域實現超越。
大模型帶來的知識管理革命正在上演。據統計,用戶使用AI大模型的最高峰是工作日的上午9:30和下午3:30。這意味著,大部分用戶都在用大模型來解決和工作相關的剛需問題,因而高效的知識獲取成為用戶和開發者都高度關注的問題。
“在知識獲取和學習的過程中,人們能拿到的資料往往不僅是現成的長文本,還有存在於報刊書籍、PPT、培訓視頻等媒介中,AI大模型需要幫助用戶從中快速獲取知識。”業內人士表示,支援長內容的大模型,則可以用來解決用戶真實場景中多源信息的獲取需求。
具有長內容能力並不只是讓大模型囫圇吞棗地把所有知識都灌進“肚子”里,還需要算力支援,讓AI理解和應用其中的內容、知識,進而幫用戶解決真正的問題。科大訊飛董事長劉慶峰透露,通過對大模型進行模型剪枝和蒸餾,就能讓AI在效果損失很小的情況下,實現文檔上傳解析處理、知識問答的首響時間以及文字生成方面的能力提升。

從千億參數到百萬長內容,大模型競爭又進入新高度。目前,長內容能力已成為大模型公司吸引市場關注,贏得競爭的路徑之一。
“大模型升級文本長度,是市場需求的直接反映。”人工智能領域天使投資人郭濤表示,長內容處理能力提升能夠更好地模擬複雜的人類語言交流。賽智產業研究院院長趙剛則認為,提升長內容處理能力,可以解決當前大語言模型應用中的痛點,使得大模型商業化應用更加成熟,更容易被用戶接受。